TIF ENOVIA/3DExperience Connector - Module Settings
The settings for the ENOVIA/3DEXPERIENCE Connector in TIF is found inside the file ${TIF_ROOT}/modules/enovia/etc/module.properties.
If you want to change or add something in this file, create an empty
file with name module.custom.properties in the same directory.
All your changes should go into the customized file.
|
Note also that you may apply instance specific properties. This may be important in case you have multiple TIF instances running and you need to configure the instances slightly different.
Read here for more details.
JAR Inclusion / Exclusion
In order to be able to connect to ENOVIA/3DEXPERIENCE with the Java API, you
need some JAR files from the ENOVIA/3DEXPERIENCE installation. One way to do this is to
set the WEBAPP_ROOT environment variable pointing to the root of your ENOVIA/3DEXPERIENCE
web application when starting up TIF. Typically this is done within the
${TIF_HOME}/bin/setenv.sh script or similar.
Note that some JAR files that you might have in the web application you point out, may contain JAR files that is in conflict with what TIF is using. Hence, you need to be able to control what to include/exclude.
The following properties are used to control this.
-
include.jar.file.pattern.defaults
-
include.jar.file.pattern
-
exclude.jar.file.pattern.defaults
-
exclude.jar.file.pattern
The properties ending with .defaults contains a pre-defined list of JAR files to
either include or exclude provided by TIF. Generally, you should not override
or modify these properties.
Instead, to control what to be excluded OR included, use these properties within your custom configuration file.
-
include.jar.file.pattern
-
exclude.jar.file.pattern
Both of these properties contains a ; separated list of regular expressions
that are matched on the files in the web application (the lib directory).
| As of version 2020.1.0, a more restrictive strategy was introduced (the include pattern) due to increasing number of support tickets caused by including too many conflicting JAR files in TIF. |
Per default, TIF provides both a list of JARs to be included and a list of JARs to be excluded. And these are defined as follows:
exclude.jar.file.pattern.defaults=mx_axis.jar;\
slf4j-.*\.jar;\
logback-classic.jar;\
logback-core.jar;\
profiler-server.jar;\
tvc-collaboration-.*\.jar;\
tif-enovia-client-.*.jar;\
jsf-.*\.jar;\
jstl-.*\.jar;\
ehcache-.*\.jar;\
enoappmvc.jar;\
fasterxml-jackson.*.jar;\
jackson-.*.jar;\
javax.*.jar;\
.*rest.*.jar
exclude.jar.file.pattern=
include.jar.file.pattern.defaults=eMatrixServletRMI.jar;\
enoviaKernel.jar;\
FcsClient.jar;\
FcsClientLargeFile.jar;\
Mx_jdom.jar;\
search_common.jar
include.jar.file.pattern=Moreover, you can disable a pattern completely by using any of these properties
include.jar.file.pattern.enabled=true
exclude.jar.file.pattern.enabled=trueSo to revert back to pre-2020.1.0 behaviour, you can simply add this into your custom property file.
include.jar.file.pattern.enabled=trueHTTP Support
There is support for HTTP inside TIF, for example running Webservices etc.
You may disable HTTP, or make configuration changes such as changing context paths. All of this is defined in the module.settings file.
Integration with Elastic Search
You can configure TIF to integrate with Elasticsearch in order to enhance the usage of the Admin UI.
This in turn will also reduce the load on the TIF server since some queries from the Admin UI adds a lot of work to the TIF server. E.g. CPU/memory can be used for job processing instead of running expensive Admin UI queries.
You need to install Elasticsearch as a separate service. We have tested TIF with versions 6.2 up-to 8.15 of Elasticsearch.
After setup of the Elasticsearch server, you need to configure some properties on the TIF side.
searchIndexer=elasticsearch
elasticSearch.hosts=http://name-of-host:9200There are plenty of other properties that plays a role, but by default you don’t need to deal with them.
You can read more about these properties within the module.properties file.
|
If you have multiple TIF instances in your production system, all of these should use the same Elasticsearch instance. TIF separates the data within the index by the tif-node-id AND tif-instance-id. But, don’t use the same Elasticsearch index for TEST instances as you use for your PRODUCTION instances. |
Search Index Synchronization
TIF has a routine for adding legacy data not yet being indexed, to the index by a Search Index Synchronizer.
|
If your database contains large amount of jobs and payload data, it may take some time to completely add all data into the index. The data is added to the index in chunks in order to not make the TIF server unresponsive. |
There is a background task running on the TIF server that takes care about this.
This task is configured by default like this:
searchIndexer.synchronizer.execute=0 0/5 * * * ?
searchIndexer.synchronizer.job.chunkSize=2000
searchIndexer.synchronizer.job.maxIterations=100
searchIndexer.synchronizer.payload.chunkSize=300
searchIndexer.synchronizer.payload.maxIterations=100E.g. every fifth minute, look for un-indexed data. On each run, run maximum 100 iterations and on each iteration try to index max 2000 jobs.
You may need to elaborate on these settings to your environment. It may also be wise to use different values during the initial period when all legacy data is being added to the index, and later change to run this routine less often.
The payload data will be added to the index AFTER all jobs have been added.
| The chunk size for payload may need to be changed depending on typical/average size of your payload data. |
If either chunk size or max iterations is set to a negative value, then no synchronization will be made for that type.
Un-indexed data is either job-data being created in the past OR job-data that is created during a period when TIF does not have contact with your Elasticsearch server.
Clean-up and Maintenance Routines
Cleaning up of expired integration data is performed by dedicated scheduled maintenance tasks. These scheduled tasks are called "cleansers".
The integration data consists of meta data that is persisted in the TIF database, and of payload data files that are saved in TIF’s data folder. The data expires according to service history settings that define how long jobs are kept in the database, and whether to store payloads. Service settings can be configured via TIF Admin UI. The default settings will be applied in case a service has no specific configuration.
The cleanser task configurations are defined in ${TIF_ROOT}/modules/enovia/etc/module.properties.
See also default service settings in Service settings.
| Make sure you configure suitable default history settings before enabling job/payload cleansers. |
In addition to the cleansers, there are also some other maintenance tasks, e.g. for updating search index and calculating some statistics.
Scheduled Maintenance Tasks
Below is a diagram illustrating the different maintenance tasks.
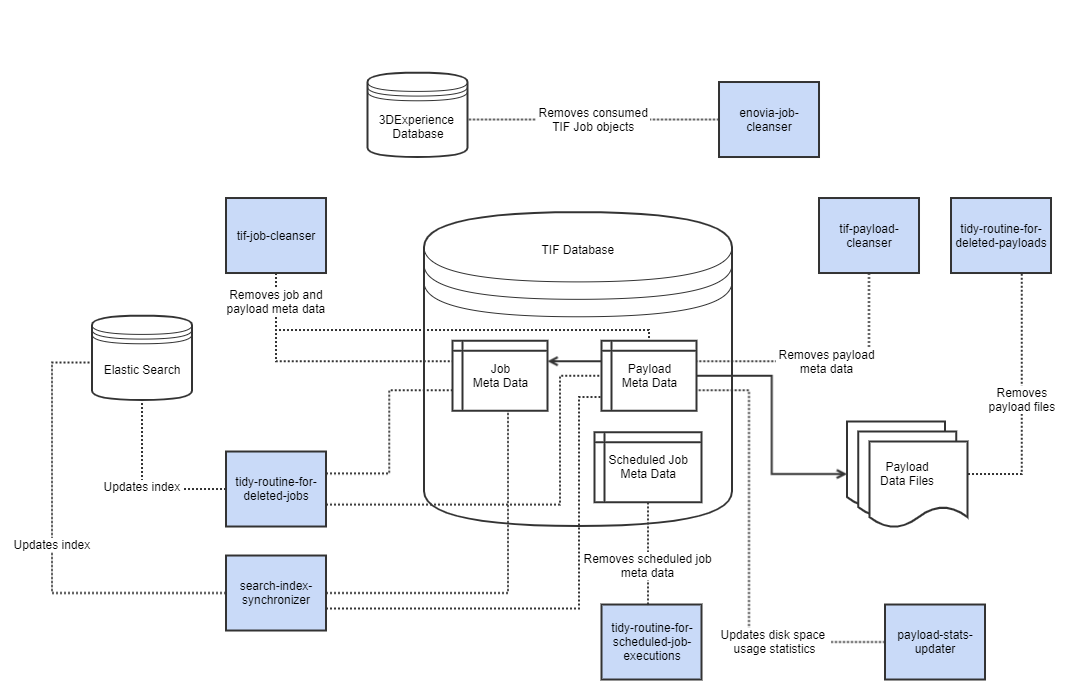
Job Cleanser (tif-job-cleanser)
The task tif-job-cleanser cleans up meta data of expired jobs. The meta data is persisted in the TIF database. Whenever a job is removed,
also associated payload meta data is removed.
Please note that tif-job-cleanser will only remove meta data from the TIF database, and does not remove actual payload data files that are stored outside the TIF database.
There are separate tasks tidy-routine-for-deleted-jobs and tidy-routine-for-deleted-payloads for removing payload files and updating search index
(if TIF is integrated with Elastic Search).
Payload Cleanser (tif-payload-cleanser)
The task tif-payload-cleanser cleans up payload meta data produced by services that are configured not to store payloads.
Deleted Job Cleanser (tidy-routine-for-deleted-jobs)
The task tidy-routine-for-deleted-jobs updates search index by cleaning up references to removed meta data.
Deleted Payload Cleanser (tidy-routine-for-deleted-payloads)
The task tidy-routine-for-deleted-payloads deletes payload data files. This
occurs after the payload meta data is removed from the database.
ENOVIA/3DEXPERIENCE Job Cleanser (enovia-job-cleaner)
The task enovia-job-cleaner removes "TIF Job" business objects from the ENOVIA/3DEXPERIENCE database.
Objects contain necessary parameters to trigger an outbound integration, and those are consumed by TIF server.
Scheduled Job Cleanser (tidy-routine-for-scheduled-job-executions)
Clean-up routine for old scheduled job executions is performed by scheduled job
tidy-routine-for-scheduled-job-executions under group "tif-internal-maintenance-jobs".
By default, the clean-up runs once per hour and keeps 20 newest execution entries in the log history.
The settings can be configured in ${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
Defaults are as follows:
scheduledJobCleanser.enabled=true
scheduledJobCleanser.execute=0 0 0-23 * * ?
scheduledJobCleanser.keepCount=20Scheduling Cleansers
All cleanser tasks can be scheduled to be run periodically at fixed times, dates, or intervals.
Schedule is configured in execute property that expects a standard Cron expression (https://en.wikipedia.org/wiki/Cron)
For example:
jobCleanser.execute = 0 15 2 * * ?In the above example, cleanser will run at 02:15:00 am every day.
In some cases it might be necessary to adjust the schedule. There are some recommendations:
-
Make sure the cleansers are executed regularly in order to prevent the TIF database from growing too much. Although the database is initialized with internal indexing, cleaning up of a large database might affect to overall performance.
-
The cleansers might perform heavy database queries, so it is not recommended to schedule all tasks to be run in parallel.
-
If possible, consider executing tasks in a window when there are less integration activities.
-
In addition to the schedule, please notice it is also possible to adjust cleanser query parameters that might improve the performance, please see the next chapter.
Adjusting Cleanser Database Queries
The cleansers performs database select and update queries that might be consuming depending on the size of the database.
In order to prevent performance problems, you may configure cleansers to split queries and/or limit the query size.
For example:
jobCleanser.deleteLimit = 10000
jobCleanser.maxIterations = 5This configuration restricts a cleanser to delete maximum of 10000 jobs per one query and perform maximum of 5 queries per one execution. Thus, the cleanser can delete maximum of 50000 jobs in total per one execution.
In addition to deleteLimit and maxIterations you may also adjust the schedule to
control how often cleansers are executed.
To prevent the database from growing too much, a general guideline is to configure cleansers to clean up at least the same amount of expired jobs/payloads that are created by average.