TIF Administration and Configuration Guide
11 January 2016
Table of Contents
- 1. TIF Overview
- 2. TIF Server - Initial Setup
- 3. Database
- 4. Configure Mail Settings
- 5. Configure Shutdown Port
- 6. HTTP/HTTPS Support
- 7. HTTP/HTTPS Client
- 8. Kerberos and Spnego Configuration
- 9. Configure Destinations
- 9.1. Token Resolver
- 9.2. Instance Specific Files
- 9.3. File Destination
- 9.4. HTTP Destination
- 9.5. JMS Destination
- 9.6. Rabbit MQ Destination
- 9.7. SOAP Destination
- 9.8. Native MQ / Websphere MQ /IBM MQ Destination
- 9.9. Email destination
- 9.10. FTP destination
- 9.11. Kafka Destination
- 9.12. Handling Delivery Failures
- 10. Log Settings
1. TIF Overview
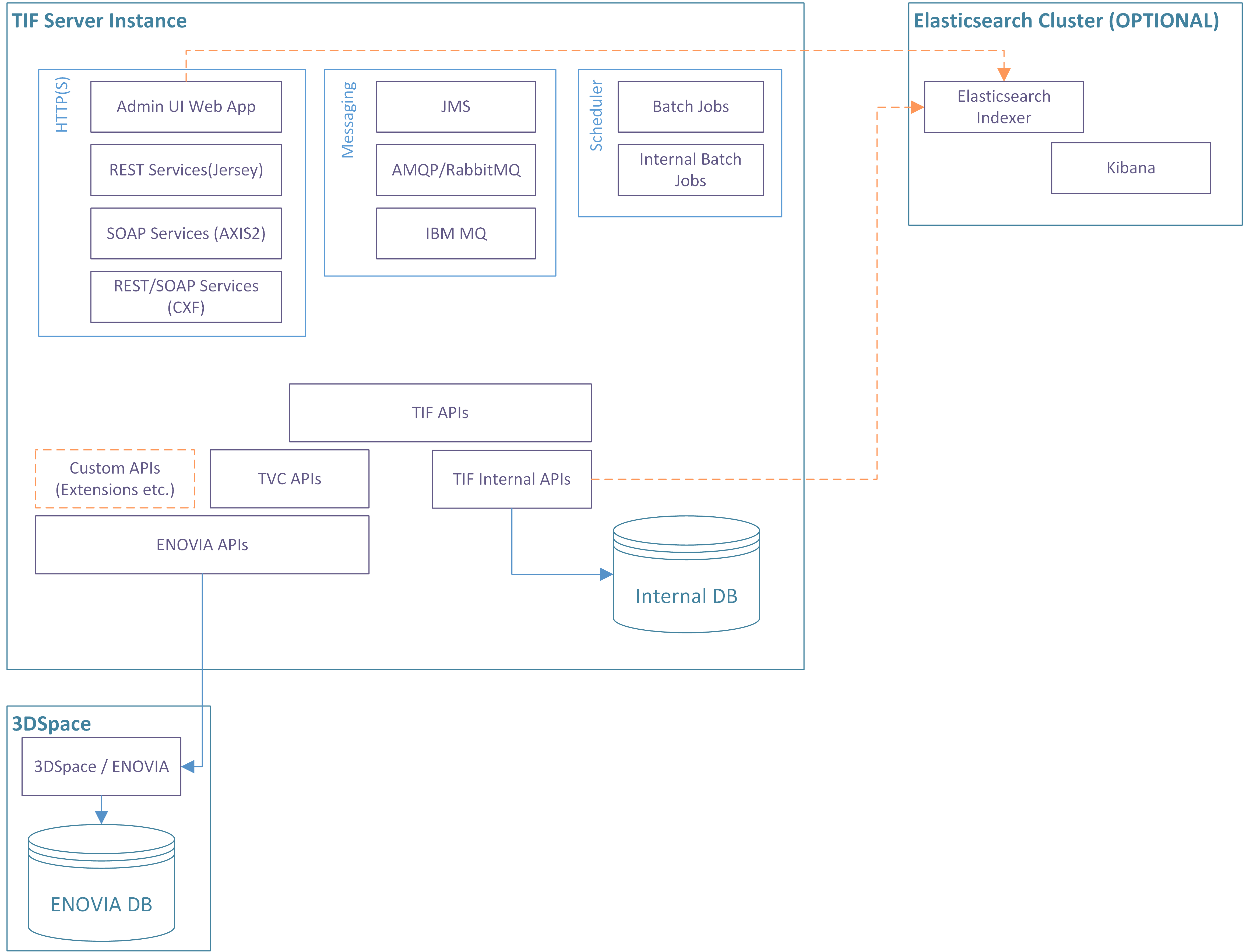
The TIF application is a Java application running inside it’s own JVM. It is not an application hosted inside an Application server like Tomcat, Websphere, JBoss etc.
Below is an image showing an overall view of a single TIF instance.
Figure 1. Overview
Each TIF instance contains a HTTP/HTTPS component (Jetty), which enables:
-
An Administration UI for inspection and validating the health of your integrations
-
Running SOAP or REST services inside either an Apache Axis2, Apache CXF or Jersey container
-
Hosting custom built web-applications
There are also support for using different kind of Messaging technologies in order to send or receive data via a message broker.
TIF also have an internal scheduler that allows running jobs at certain points in time.
Additionally, TIF also contains components such as an internal database in order to track executions of integration jobs over time. TIF is using the TVC Core API to perform ENOVIA/3DExperience queries and operations.
There is also a non-mandatory option also to have an Elasticsearch instance connected with TIF in order to make the Administration UI really fast.
2. TIF Server - Initial Setup
In order to use TIF, you need to configure a couple of things before taking it into use.
The main configuration files inside the TIF server is located under:
-
${TIF_ROOT}/etc -
${TIF_ROOT}/modules/enovia/etc
The sub chapters describe the required setup.
| In general, don’t modify the configuration files that are part of the TIF distribution. You can in most cases create a new file with a different name containing the customized configurations. For example: |
-
Don’t modify the file
${TIF_ROOT}/etc/tif.propertiesdirectly.-
Create instead a new file in the same directory called
${TIF_ROOT}/etc/tif.custom.properties.
-
-
Create/use the file
${TIF_ROOT}/modules/enovia/etc/module.propertiesinstead-
Create/use the file
${TIF_ROOT}/modules/enovia/etc/module.custom.propertiesinstead.
-
-
And also the file
${TIF_ROOT}/modules/enovia/etc/tvc.properties-
Create/use the file
${TIF_ROOT}/modules/enovia/etc/tvc.custom.propertiesinstead.
-
These custom files are merged with the original file meaning that the content of the custom file takes precedence over the original file.
2.1. Macros in Property Files
The property values in the property files may contain macros that resolves to a value.
The macro are defined using a ${} construct.
You can reference other properties from the same file.
Example properties
one=1
two=2
three=3
twenty_three=${two}${three}
dont_resolve=$${two}When resolving properties from ${TIF_HOME}/etc/tif.properties,
then macros are also resolved from system properties. Example:
Resolve from system properties
directory=${user.home}/subdir2.2. Multiple TIF Instances
To support horizonal scaling, you can setup multiple TIF instances.
Internally, a TIF instance is defined by its node id and instance id. The node id is equal to the hostname, which the TIF server binds to. The instance id is either automatically assigned or defined.
The data related to one TIF instance is stored below ${TIF_ROOT}/data/${NODE_ID}/${INSTANCE_ID}, and
every TIF instance must have its own data directory.
| The base location for the data can be specified in the tif.custom.properties file within ${TIF_ROOT}/etc. |
The first time TIF is started up, TIF will assign an instance id (unless the INSTANCE_ID has been defined, see below how the instance id is resolved) and create the directory.
You should NOT try to start two different instances using the same node id and instance id combination. A simple (and naive!) solution is to duplicate the TIF installation directory and simply start up the instances in the normal way. The auto generated instance id’s will be unique, however, you then have two TIF installations to setup and configure so this is not recommended.
The recommended approach is to use one installation base, and simply use different start scripts to start each instance with. See below how to specify the instance-id within a start-script.
| The ENOVIA/3DExperience Connector have some additional things to concern when setting up multiple instance. Please read more here. |
2.2.1. Resolving the Instance Id
The instance id is default set to auto within the file ${TIF_ROOT}/etc/tif.properties.
If you want to change this value to something else, you should do so in the custom
properties file ${TIF_ROOT}/etc/tif.custom.properties.
You can also provide this parameter as a runtime parameter in the TIF start script like this:
java -Dtif.instance.id=auto -Dtif.http.port=8080 ...The latter is useful in case you have one installation base and via different start scripts wants.
2.2.2. Production Mode
Per default, TIF starts in production mode. To start TIF in development mode, use the "productionMode" parameter.
Either set this property in ${TIF_HOME}/etc/tif.custom.properties, or as a Java system parameter as shown below.
java -Dtif.productionMode=false ...2.2.3. HTTP / HTTPS Port
Running different TIF instances on the same network address requires you to configure TIF to bind the HTTP/HTTPS server to a unique port.
This is then set via these Java system parameters:
java -Dtif.https.port=443 -Dtif.http.port=8181 ...2.2.4. Shutdown Listen Port
TIF listens for shutdown signals by default at port 9005. To change this port, which is needed in case you launch multiple TIF instances on the same machine, set the value as a Java system parameter like this:
java -Dtif.shutdownListener.port=9006 ...2.2.5. Example Start Script
Below is an example start script where additional parameters are defined.
@echo off
setlocal
set ENOVIA_HOME=c:\apps\ENOVIA\V6R2016X\Server
set JAVA_HOME=c:\apps\jdk64\7
set WEBAPP_ROOT=c:\webapps\2016X
set EXTRA_OPTS=-Dtif.instance.id=TIF-2 -Dtif.http.port=8282 -Dtif.shutdownListener.port=9005 (1)
set START_ARGS=-Xdebug -Xrunjdwp:transport=dt_socket,address=8000,server=y,suspend=n (2)
set STOP_ARGS= (3)
call tif.bat run| 1 | EXTRA_OPTS is handled in the tif.bat script and is appended to the Java argument list |
| 2 | START_ARGS works similar to EXTRA_OPTS, however they are only set if the TIF server is started |
| 3 | STOP_ARGS are only added to the argument list if the TIF server is stopped |
3. Database
TIF uses by default an embedded database to store its data into. This embedded database is an Apache Derby database.
Another option is to use an external database. This is the preferred option especially if you want to maximize the performance, and/or if there will be multiple TIF server instances in use.
If you have multiple TIF servers in use and don’t use an external database, you need to log-in to each TIF instance to monitor the health and progress of the integration jobs. With an external database, you will be able to see the same information regardless which TIF instance you log in to.
3.1. Embedded Database
Using an embedded database does not require any additional or specific configuration by default. It is the easiest setup and is convenient to use in many cases, although it does not offer the best performance.
The embedded Apache Derby database is per default started up without any network capabilities, meaning that you will not be able to connect to the database over JDBC. It is however possible to enable network access to the database and use some database tool to work with the database.
3.1.1. Connect to the embedded Derby DB
You need the Apache Derby DB / tools installed on your computer. Download these first from this URL:
http://db.apache.org/derby/releases/release-10_14_2_0.cgi
From now on, DERBY_HOME is referred to the directory where you installed the Derby tools.
You can connect in two different ways. The first approach can be used on a NON running TIF instance by connecting directly to the database files:
DERBY_OPTS=-Dderby.system.home=/path/to/tif/data/`hostname`/TIF-1/db.home ${DERBY_HOME}/bin/ijWhen "IJ" starts, connect to the DB using the below syntax.
ij> connect 'jdbc:derby:TIFDB';The second approach can be done against a running TIF instance.
Note however that you need to ensure that the below setting is set within the file etc/tif.custom.properties.
db.mode = mixedThis will enable network access on port 1527 (can be changed) to the Derby DB.
Once TIF is started, it will print out its JDBC URL in the console.
Start IJ and connect:
${DERBY_HOME}/bin/ij
ij> connect 'jdbc:derby://127.0.0.1:1527/TIFDB';3.1.2. Backup
You can perform a database backup of the embedded database by using standard Operating System commands. However, this should only be done when the database is offline.
Another option is to do an online backup using the built-in procedures in the Apache Derby database. To do this, you need to ensure that TIF is running the database with network access enabled (see previous chapter). Secondly, you need to connect to the Derby database using for example the IJ tool (see previous chapter).
Then, read this document to understand the backup procedures:
3.1.3. Maintenance
Prior to doing database maintenance, you need to first shutdown the running TIF instance.
To run maintenance of the internal database, you can use the scripts "tif.bat" or "tif.sh" available in the "bin" folder.
This script accepts an argument: dbmaintenance.
If supplying this, the database maintenance task will start.
If you have multiple instances of TIF, you must perform the maintenance per instance.
Below is an example script (Windows) showing how to run the maintenance task for the instance TIF-1.
|
@echo off
setlocal
set EXTRA_OPTS=-Dtif.instance.id=TIF-1 (1)
call tif.bat dbmaintenance| 1 | Specify the instance ID here |
There are some properties within the tif.properties file that are related to this task.
These properties are described in the properties file.
3.2. External Database
Using an external database is the preferred option especially if there are multiple TIF server instances. This allows deciding whether to use a dedicated database per instance or share it across multiple instances. Sharing a database allows you to work with the same data regardless which TIF Admin UI instance you log in to.
The supported external databases and applied SQL dialects are listed in the below table. Dialect means the variant of the SQL language and defines the required database version. Dialects are typically compatible with later database versions.
| Database | SQL Dialect |
|---|---|
Oracle |
12c |
PostgreSQL |
10 |
SQL Server |
2008, 2000 |
3.2.1. Database Drivers
Database specific drivers are required when using an external database. Due to licensing issues, the TIF server bundle does not include any external driver.
The database driver is distributed by the database vendor. See below links:
PostgreSQL: https://jdbc.postgresql.org/download
SQL Server: https://docs.microsoft.com/en-us/sql/connect/jdbc/download-microsoft-jdbc-driver-for-sql-server
The driver and other related JAR files must be copied into ${TIF_ROOT}/lib/custom.
|
3.2.2. Configuration
Using an external database requires some additional configuration to be added into the file: ${TIF_ROOT}/etc/tif.custom.properties .
First, the property db.type chooses what type of external database to use.
The possible values are oracle, postgresql or mssql.
The minimum required configuration to be applied are host name, port number, database name, user and password.
Non-default database schema/tablespace must be defined by property db.<dbtype>.hibernate.hibernate.default_schema.
See more details in ${TIF_ROOT}/etc/tif.properties.
| In case you have multiple TIF server instances sharing the same external database, also see Admin UI configuration. |
Oracle Example
# Minimum required settings
db.type = oracle
db.oracle.host = myhostname
db.oracle.port = 1521
db.oracle.database = databasename
db.oracle.user = databaseuser
db.oracle.password = databaseuserpassword
# Additional settings
# db.oracle.hibernate.hibernate.default_schema=...
# Data source customization
# db.oracle.customClassName=...PostgreSQL Example
# Minimum required settings
db.type = postgresql
db.postgresql.host = myhostname
db.postgresql.port = 5432
db.postgresql.database = databasename
db.postgresql.user = databaseuser
db.postgresql.password = databaseuserpassword
# Additional settings
# db.postgresql.hibernate.hibernate.default_schema=...
# Data source customization
# db.postgresql.customClassName=...SQL Server Example
| SQL Server database must use case insensitive collation. See: https://docs.microsoft.com/en-us/sql/t-sql/statements/collations |
| If the SQL Server is older than 2008, you must apply SQL Server 2000 dialect. |
# Minimum required settings
db.type = mssql
db.mssql.host = myhostname
db.mssql.port = 1433
db.mssql.database = databasename
db.mssql.user = databaseuser
db.mssql.password = databaseuserpassword
# To apply SQL Server 2000 dialect:
# db.mssql.hibernate.hibernate.dialect=com.technia.tif.core.db.mssql.TIFSQLServer2000Dialect
# Additional settings
# db.mssql.hibernate.hibernate.default_schema=...
# Data source customization
# db.mssql.customClassName=...Data Source Customization
It is possible to inject a custom Java class that can be used for modifying the data source. The data source is a factory for
JDBC connection between the database and the TIF server. The class is specified in the property db.<dbtype>.customClassName.
The class must implement an interface BiConsumer<T extends DataSource, Settings> where T is:
-
Oracle:
oracle.jdbc.datasource.OracleDataSource -
PostgreSQL:
org.postgresql.ds.PGSimpleDataSource -
SQL Server:
com.microsoft.sqlserver.jdbc.SQLServerDataSource
Below examples illustrates how to configure and implement a custom class.
tif.custom.properties:
db.mssql.customClassName=com.acme.tif.db.CustomInitializerThe Java class:
package com.acme.tif.db;
import java.util.function.BiConsumer;
import com.microsoft.sqlserver.jdbc.SQLServerDataSource;
import com.technia.tif.core.Settings;
// This example customizes SQL Server data source
public class CustomInitializer implements BiConsumer<SQLServerDataSource, Settings> {
@Override
public void accept(SQLServerDataSource ds, Settings s) {
// See setter methods exposed by the data source instance
}
}3.2.3. Migrating Data
Integration data can be imported from an existing TIF server instance that uses an embedded Derby database.
To perform the migration, you can use the scripts "tif.bat" or "tif.sh" available in the "bin" folder.
This script accepts an argument called dbmigration, and when supplied the TIF server starts in database migration mode.
For example:
call tif.bat dbmigration| Migration supports importing data from an embedded database to an external database, not vice versa. |
| The migration logic only supports migration from ONE TIF instance, e.g. if you have multiple TIF instances each using its own embedded Derby database you can only migrate one of those instances. |
Before Migration
The following steps needs to be ensured before migration:
-
The target external database instance must be empty. Do not start or run the TIF server in external database mode before migration.
-
Files containing the embedded TIF database must be located in
${TIF_ROOT}/data/${NODE_ID}/${INSTANCE_ID}/db.home. E.g. if you want to migrate the data to a new server installation, first copy directorydb.homefrom old TIF server instance. -
Take a back-up of the data folders.
-
The TIF server must be configured to connect to the external database. Migration cannot be started when TIF server is configured to use the embedded database.
| The TIF server cannot execute integration activities during migration. |
Executing the Migration
Supply the argument dbmigration to start the TIF server in migration mode.
The migration consists of multiple tasks that each import data to one database table.
Depending on the size of the source database, the migration might take from a few minutes up to several hours. The progress can be monitored from the TIF log file or the terminal window where the migration process is started in.
After the migration is completed, the migration process is shut down automatically.
To start the TIF server in normal operational mode again, you need to start the TIF server without the dbmigration argument.
If you need to stop the migration process, send the shutdown signal to TIF server by using the stop argument.
When doing so, the status of an ongoing migration task is stored so that it can be continued later.
Terminating the process e.g. with Ctrl+C combination will not store the status and thus make it difficult or even impossible to continue the migration from where it stopped.
|
Restarting the Migration
If the migration process is stopped properly, it usually can be continued from the last stored position.
If the process is terminated in an uncontrolled way, forcibly or due to an exception, the process cannot always continue due to conflicting data in the database.
In this situation, you can restart a task and its table position.
Each task stores its state in a properties file located in directory ${TIF_ROOT}/data/${NODE_ID}/${INSTANCE_ID}/migration.
Deleting a file causes the task to start again from the first table row.
However, restarting a task might not be enough to recover if the table in the external database already
contains imported rows.
Typically, this leads to an exception like "duplicate key value violates unique constraint sometable_pk".
In this case, rows needs to be manually deleted from the table with an SQL client.
Alternatively, you may set the flag migration.cleanTableOnTaskRestart to true in the ${TIF_ROOT}/tif.custom.properties file.
For example:
migration.cleanTableOnTaskRestart=trueIf the flag is true, each task will clean the target table if there is no associated file in migration directory.
The final recover option is to delete all files within the ${TIF_ROOT}/data/${NODE_ID}/${INSTANCE_ID}/migration directiry and also
drop all tables in the external database.
This will restart all migration tasks from the beginning.
After Migration
After migration, the directory called TIFDB within the directory ${TIF_ROOT}/data/${NODE_ID}/${INSTANCE_ID}/db.home still contains the old Derby database files.
These files will no longer be used by the TIF server.
The sub-directory TIFDB can be removed, but it is
recommended to keep these until you have verified that the migration was ok and you no longer have a need to switch back to the old embedded database.
4. Configure Mail Settings
The mail settings are defined inside ${TIF_ROOT}/etc/tif.properties.
There you see the following properties:
mail.disabled = false
mail.smtp.host = smtp.company.com
mail.smtp.port = 25
mail.from.address = tif@company.com
mail.from.name = TIFTo define these properties, create a file called ${TIF_ROOT}/etc/tif.custom.properties within the same directory unless already created.
Specify the correct values for the keys above in this file.
You can also add additional "mail." properties in this file to be passed over to the Java Mail API.
Below is an example how to pass in extra auth settings for SMTP.
mail.debug=true
mail.smtp.auth=true
mail.smtp.user=user_id
mail.smtp.password=the_secret_word5. Configure Shutdown Port
The TIF server sets up a shutdown listener on a dedicated socket on the machine it runs at. To configure the port use the following properties inside ${TIF_ROOT}/etc/tif.custom.properties.
shutdownListener.port = 9005 shutdownListener.host = localhost
You might need to do this if this port already is used by another service on the same machine, or, if you have multiple TIF instances running on this machine (each must have it’s own port number).
6. HTTP/HTTPS Support
6.1. Configure HTTP Support
The place where to configure the core HTTP settings are in the ${TIF_ROOT}/etc/tif.custom.properties file.
Below is a list of properties TIF support today.
# Setting port < 1 disables HTTP support
http.port = 8181
http.maxIdleTime = 30000
http.requestHeaderSize = 81926.2. Configure HTTPS Support
The place where to configure the core HTTPS settings are in the ${TIF_ROOT}/etc/tif.custom.properties file.
By default the HTTPS support is disabled since the default value of https.port is set to -1. To enable it, you need to specify the port (probably use port 443), a keystore and its password and alias.
Below is a list of all parameters that can be set.
#https.port=-1
#https.keyStore.path=<path to keystore, example: etc/keystore>
#https.keyStore.password=secret
#https.keyStore.type=
#https.keyStore.provider=
#https.keyManager.password=
#https.trustStore.path=<path to the trust-store, example: etc/keystore>
#https.trustStore.password=secret
#https.trustStore.type=
#https.trustStore.provider=
#https.certAlias=
#https.includeCipherSuites=<comma separated list>
#https.excludeCipherSuites=<comma separated list>
#https.maxIdleTime=30000For further details around SSL/TLS please refer to this page.
6.2.1. TLS Version
Supported TLS version vary on used Java JRE. For example Java 11 typically enable TLS 1.3 by default, whereas older Java 8 releases might only support TLS 1.2 or lower.
Consult Java documentation for more information.
6.2.2. SSL Enabling Example
Assuming that you have a valid certificate including a private key, available in the files
-
server.crt
-
server.key
Then you need to create a Java keystore from these files.
First, you need to convert the certificate into PKCS12 format. Below is an example how to do so with openssl. Note that you will be asked for passwords that you will have to remember.
openssl pkcs12 \
-export \
-in server.crt \
-inkey server.key \
-out server.p12 \
-name tifThe next step is to use keytool from the Java installation in order to import the PKCS12 certificate into a Java keystore. Below is an example showing how to do so. Note that the password secret should be changed.
keytool \
-importkeystore \
-deststorepass secret \
-destkeypass secret \
-destkeystore keystore \
-deststoretype PKCS12 \
-srckeystore server.p12 \
-srcstoretype PKCS12 \
-srcstorepass secret \
-alias tifThen, copy the keystore file into the directory ${TIF_HOME}/etc/.
Finally, add into ${TIF_HOME}/etc/tif.custom.properties these properties.
https.port=443
https.keyStore.path=etc/keystore
https.keyStore.password=secret
https.certAlias=tifStart TIF and ensure that it works correctly with HTTPS on port 443 (which is the default port for HTTPS).
6.2.3. Configure Self Signed Certificate
Simply setting up TIF with a self signed certificate is simple and useful for testing. Just follow these steps:
-
Use keytool to create the keystore
cd $TIF_HOME/etc keytool -keystore keystore -alias tif -genkey -keyalg RSA -sigalg SHA256withRSAThen you will be asked for some information like shown below.
Enter keystore password: Re-enter new password: What is your first and last name? [Unknown]: What is the name of your organizational unit? [Unknown]: What is the name of your organization? [Unknown]: What is the name of your City or Locality? [Unknown]: What is the name of your State or Province? [Unknown]: What is the two-letter country code for this unit? [Unknown]: Is CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown correct? [no]: yes Enter key password for <tif> (RETURN if same as keystore password): -
Modify
${TIF_HOME}/etc/tif.custom.propertieshttps.port=443 https.keyStore.path=etc/keystore https.keyStore.password=password https.certAlias=tif
Done
7. HTTP/HTTPS Client
TIF is also used as a HTTP/HTTPS client in case you have integrations that will communicate via HTTP.
There are some global settings you may need to adjust for this client discussed in the sub-chapters below.
7.1. Proxy Configuration
To configure using proxy servers when creating outbound HTTP calls from TIF,
you can set this from ${TIF_HOME}/etc/tif.custom.properties
There are two properties to use, e.g
http.proxy-
Defines proxy server for plain HTTP calls.
https.proxy-
Defines proxy server for secure HTTP calls.
8. Kerberos and Spnego Configuration
Different web-applications running inside a TIF instance may support single-sign-on via Spnego/Kerberos authentication for users on a Windows or Active Directory based network.
In order to support this, one need to configure the underlying Kerberos/Spnego modules within the JDK with a number of settings.
| You should enable SSL for TIF when using Kerberos authentication. |
8.1. Active Directory Configurations
On your Active Directory server, you need to do some administration and generate a so called "keytab" file.
You need the following information
-
hostname of the machine, which your TIF instance is running from
-
Example:
tifserver.exampledomain.com
-
-
An Active Directory user
-
Example:
tifuser
-
First, you need to run the setspn command (https://technet.microsoft.com/en-us/library/cc731241(v=ws.11).aspx).
setspn -A HTTP/tifserver.exampledomain.com tifuserNext step is to create/generate the keytab file.
| This keytab file should be transferred to the TIF server and kept securely and not readable for the "world". |
Creating the keytab is used by the command ktpass. (https://technet.microsoft.com/en-us/library/cc753771(v=ws.11).aspx)
ktpass -out c:\dir\krb5.keytab -princ HTTP/tifserver.exampledomain.com@EXAMPLEDOMAIN.COM -mapUser tifuser -mapOp set -pass THE_SECRET_PASSWORD -crypto AES256-SHA1 -pType KRB5_NT_PRINCIPAL| change the hostname + username/password and also the "-out" argument above to match your environment. |
Also note that you need to review what encryption algorithm to be used. Over time, this may change and different versions of Windows may add new algorithms, which we are not able to keep up-to-date in this document.
8.2. TIF Properties
Within the file ${TIF_ROOT}/etc/tif.custom.properties you will have some property keys to set.
These keys corresponds to Java System properties, and you can if wanted use the Java system property
and specify them via "-D" parameters on the command line. However, that requires modifying the start
scripts for TIF so the recommended approach is to apply these within the tif.custom.properties file.
Required properties:
| TIF Property Key | Java System Property | Description |
|---|---|---|
kerberos.enabled |
- |
A boolean flag indicating if to enable kerberos via TIF property key/values. You can still configure Kerberos via Java system parameters as usual, however, you need to set this property to true in order to let TIF configure the kerberos module through properties specified in here. |
kerberos.conf |
java.security.krb5.conf |
Points out the file configuring the underlying kerberos setup. |
kerberos.authLoginConfig |
java.security.auth.login.config |
Configures Spnego vs Kerberos |
kerberos.authUseSubjectCredsOnly |
javax.security.auth.useSubjectCredsOnly |
This one is by default set to FALSE and should be in this case. |
kerberos.debug |
sun.security.spnego.debug |
Used to enable debugging from the JDK layer. Default is false. Should only be used for debugging during setup, otherwise your log-files will be filled quite fast. |
| If a Java system property already has been defined, TIF will never re-assign that value. |
8.3. Example Configurations
Below is a working example how to setup all. Note that we have tested with a Windows 2008 server setup, other versions may need other configuration values or switches/arguments to setspn/ktpass.
${tif.home}/etc/tif.custom.properties
kerberos.enabled=true (1)
kerberos.conf=${tif.home}/etc/kerberos/krb5.ini (2)
kerberos.authLoginConfig=${tif.home}/etc/kerberos/spnego.conf (3)| 1 | Required to enable setting up kerberos via TIF properties |
| 2 | Points out a kerberos configuration file |
| 3 | Points out a Spnego configuration file |
${tif.home}/etc/kerberos/krb5.ini
[libdefaults]
default_realm = EXAMPLEDOMAIN.COM
default_keytab_name = FILE:c:/apps/tif-server/etc/spnego/krb5.keytab
permitted_enctypes = aes128-cts aes256-cts arcfour-hmac-md5
default_tgs_enctypes = aes128-cts aes256-cts arcfour-hmac-md5
default_tkt_enctypes = aes128-cts aes256-cts arcfour-hmac-md5
[realms]
EXAMPLEDOMAIN.COM= {
kdc = 192.168.0.123
admin_server = 192.168.0.123
default_domain = EXAMPLEDOMAIN.COM
}
[domain_realm]
exampledomain.com= EXAMPLEDOMAIN.COM
.exampledomain.com = EXAMPLEDOMAIN.COM
[appdefaults]
autologin = true
forwardable = true${tif.home}/etc/kerberos/spnego.conf
com.sun.security.jgss.initiate {
com.sun.security.auth.module.Krb5LoginModule required
principal="HTTP/tifserver.exampledomain.com@EXAMPLEDOMAIN.COM"
useKeyTab=true
keyTab="c:/apps/tif-server/etc/spnego/krb5.keytab"
storeKey=true
isInitiator=false;
};
com.sun.security.jgss.accept {
com.sun.security.auth.module.Krb5LoginModule required
principal="HTTP/tifserver.exampledomain.com@EXAMPLEDOMAIN.COM"
useKeyTab=true
keyTab="c:/apps/tif-server/etc/spnego/krb5.keytab"
storeKey=true
isInitiator=false;
};Please read more from the link below regarding additional properties:
8.4. Tips
Setting up kerberos/spnego is a "fragile" task and its easy to do something wrong. The debugging information you will see from the JDK level is far from helpful in some cases.
Below are some URLs with information that might help:
A last recommendation is to NOT test the setup with the client and server on the same machine!
Also note that the site/host running your TIF instance may need to be added to the "Trusted Sites" on the clients. This is typically updated via GPO in Windows, done by the Domain Administrators.
9. Configure Destinations
Transferring data to another system requires you to declare the destination endpoints somewhere.
This is done within one centralized file located at ${TIF_ROOT}/etc/destinations.xml.
This file is not part of the installation, instead, we provide an example configuration called ${TIF_ROOT}/etc/destinations.xml.sample.
This configuration file is of XML format, and the root element of this file is <Destinations>.
The currently supported destinations are:
- File
-
Used to store data into a generated file inside a particular directory
- FTP
-
Transfer data to a FTP site
-
Transfer data via mail to a recipient
- HTTP
-
Used to transfer the data to some destination via HTTP protocol. E.g. a REST service or similar.
- SOAP Service
-
A defines SOAP endpoint.
- JMS
-
Used to transfer the data to a JMS topic or queue.
- Rabbit MQ (AMQP)
-
Used to transfer the data to a Rabbit MQ server via the AMQP protocol.
- Websphere MQ / Native MQ
-
Used for transfer the data to a IBM-MQ broker via the Native-MQ protocol. Note that IBM MQ also supports the JMS protocol.
- Kafka
-
Transfer data to an Apache Kafka topic
Each destination within this configuration file is associated with an identifier. This identifier must be unique across all destinations.
Example: ${TIF_ROOT}/etc/destinations.xml
<Destinations>
<JMS id="erp-01"
initialContextFactory="org.apache.activemq.jndi.ActiveMQInitialContextFactory"
providerURL="tcp://erp01.company.com:61616">
<Queue name="released_parts" jndiKey="queue.%s"/>
<Env key="..." value="..."/>
<Env key="..." value="..."/>
</JMS>
<RabbitMQ id="SAP"
uri="amqp://userName:password@hostName:portNumber/virtualHost"
routingKey="rk1">
<Queue name="q1" autoDelete="false" durable="true" exclusive="false"/>
<Exchange name="e1" autoDelete="false" durable="true" type="direct"/>
</RabbitMQ>
</Destinations>|
TIF generally do not bundle any vendor specific JAR files. You need to manually decide which vendor JAR files that are required, and put these into the folder |
9.1. Token Resolver
Some destinations, like the Http destination, may require some additional tokens to be established prior to performing the actual http reqeust. To support that, you can register token resolvers within the destinations file.
<Destinations>
<TokenResolver id="keycloak" cacheFor="300s">
...
</TokenResolver>
</Destinations>You can define as many token resolvers as needed, just ensure that each have a unique identifier.
The cacheFor directive specifies the duration how long the generated tokens may be reused.
The tokens are cached per url/header/payload combination, meaning that if your token resolver
uses dynamic values, the caching is sensitive to the resolved values and thus each token resolver may contain many cache entries.
9.1.1. Configuration Format
On a high level, the token resolver configuration contains three parts:
- Request
-
Defines how the request will be constructed when requesting the tokens. There is support for constructing requests using either x-www-form-url-encoded key/value pairs or JSON request bodies.
- Response
-
Defines what data from the response we are interested in when contructing our tokens. Currently you can take values from response headers and/or JSON values from the response body.
- Tokens
-
Specifies the tokens to be used and how to build these.
Below is a complete example for a token resolver that works against Keycloak to establish an authorization token according to the OAuth2 client credentials flow.
<Destinations>
<TokenResolver id="keycloak-1" cacheFor="5m">
<Request url="http://localhost:30180/auth/realms/${job.param.keycloak_realm}/protocol/openid-connect/token">
<Params>
<Param name="grant_type" value="client_credentials" />
<Param name="scope" value="${job.param.keycloak.scopes}" />
<Param name="client_id" value="tif" />
<Param name="client_secret" value="${tif.setting.keycloak.tif.secret}" />
</Params>
</Request>
<Response>
<Json>
<Map jsonPath="$.access_token" as="access_token" />
<Map jsonPath="$.token_type" as="token_type" />
</Json>
</Response>
<Tokens>
<Token name="Authorization" macro="${token_type} ${access_token}" />
</Tokens>
</TokenResolver>
<Http id="http-dest-with-keycloak" tokenResolver="keycloak-1" url="..." />
</Destinations>In this example, the request is a param name/value request and the response is of type JSON.
It is also possible to send out JSON data and map the response headers into tokens, see example below:
<TokenResolver id="monitor" cacheFor="24H">
<Request
url="http://monitor:8001/${tif.setting.monitorLanguageCode}/${job.param.companyNumber}/login">
<Json> <!-- implies application/json + method = POST -->
<Object>
<Property name="Username" string="${job.param.monitorUserName}" />
<Property name="Password" string="${job.param.monitorPassword}" />
<Property name="ForceRelogin" bool="true" />
</Object>
</Json>
</Request>
<Response>
<Header name="X-Monitor-SessionId" as="sessionId" />
</Response>
<Tokens>
<Token name="X-Monitor-SessionId" value="${sessionId}" />
</Tokens>
</TokenResolver>The details of each element is described below.
9.1.2. <TokenResolver>
The top level element <TokenResolver> supports the following attributes.
| Attribute | Description | Required |
|---|---|---|
id |
A unique identifier among all token resolvers. |
Yes |
cacheFor |
An optional duration definition specifying how long time the token may be cached. If omitted, no caching takes place. Example values:
|
No |
Supported child elements:
-
<Request> -
<Response> -
<Tokens>
9.1.3. <Request>
Specifies how the request will be constructed.
This element supports the following attributes
| Attribute | Description | Required |
|---|---|---|
url |
The URL to perform the request against |
Yes |
method |
Specifies request method. If omitted, GET is used in case no body is configured and POST is used if a body is configured. |
No |
contentEncoding |
Can be used to control the content encoding. Default is UTF-8 |
No |
proxyOverride |
Can be used to override global proxy settings in TIF |
No |
disableProxy |
Can be used to disable using proxy server for token resolving. |
No |
|
The request will per default use the global http/https proxy setting unless overridden via the See this document for details around proxy settings in TIF. |
Supported child elements:
| Element | Description | Required |
|---|---|---|
|
Defines that you will send JSON data to the server. |
No |
|
Defines that you will send key/value parameters |
No |
|
Defines additional headers to be part of the request |
No |
<Json>
The Json element is used to declare a JSON structure to be generated
See example below how to construct such Json definition:
<Request ...>
<Json>
<Object>
<Property name="Username" string="${job.param.monitorUserName}" />
<Property name="Password" string="${job.param.monitorPassword}" />
<Property name="ForceRelogin" bool="true" />
<Array name="test">
<Property int="1" />
<Property int="2" />
</Array>
</Object>
</Json>
</Request>This will generate a JSON payload like the example below:
{
"Username" : "the resolved value from the job param monitorUserName",
"Password" : "the resolved value from the job param monitorPassword",
"ForceRelogin" : true,
"test" : [ 1, 2 ]
}You can use <Object>, <Array> and <Property> to define the structure.
The Property element supports the following attributes:
| Attribute | Description |
|---|---|
string |
Defines that the value is of type string |
bool |
Defines that the value is of type boolean |
int |
Defines that the value is of type int64 |
double |
Defines that the value is of type double |
number |
Defines that the value is of type number |
splitValueBy |
Specify optional separator that can be used to split the value into an array instead |
<Params>
The <Params> element is used to define a payload that is x-www-form-urlencoded (e.g. a form post).
Example:
<Request ...>
<Params>
<Param name="grant_type" value="client_credentials" />
<Param name="scope" value="${job.param.keycloak.scopes}" />
<Param name="test" value="a,b,c,d" splitBy="," />
</Params>
</Request>This will generate a payload like below
grant_type=client_credentials&scope=s1+s2+s3+s4&test=a&test=b&test=c&test=dThe <Params> element contains one or more <Param> elements, which supports the following attributes.
| Attribute | Description | Required |
|---|---|---|
name |
Name of parameter |
Yes |
value |
The value of the parameter |
Yes |
splitValueBy |
Specify optional separator that can be used to split the value into an array instead |
No |
9.1.4. <Response>
The <Response> element defines what data you are interested in from the response.
You can save values from headers and/or data from a JSON response body.
The idea is that you will define what data you are interested in and associate that with a variable. Later on, you will use those variables to construct the final tokens.
When working with JSON response data you will use so called JSON paths to select data from the JSON structure to be saved.
For more detailed information about JSON path, see this document
Below is an example where the properties token_type and access_token are saved from the JSON object. Note that selecting anything else than plain literals (strings, numbers, booleans) are typically not supported.
<Response>
<Json>
<Map jsonPath="$.token_type" as="tokenType" />
<Map jsonPath="$.access_token" as="accessToken" />
</Json>
</Response>The <Map> element supports the following attributes
| Attribute | Description | Required |
|---|---|---|
jsonPath |
The JSON path expression to use |
Yes |
as |
The name of the variable to save the value as |
Yes |
To save some header values into a named variable, see the example below:
<Response>
<Header name="X-Monitor-SessionId" as="sessionId" />
<Header name="Another-Header" as="another" />
</Response>The <Header> element supports the following attributes
| Attribute | Description | Required |
|---|---|---|
name |
Name of header to take |
Yes |
as |
The name of the variable to save the value as |
Yes |
ignoreCase |
If header names are case sensitive or not. Default is to ignore case. |
No |
9.1.5. <Tokens>
The final tokens to use are defined within the <Tokens> element.
See example below where the Authorization token is generated based upon the variables token_type and access_token
<TokenResolver>
...
<Tokens>
<Token name="Authorization" macro="${token_type} ${access_token}" />
</Tokens>
</TokenResolver>The <Token> element supports the following attributes
| Attribute | Description | Required |
|---|---|---|
name |
Name of the token |
Yes |
macro |
The macro to use when resolving the token value |
Yes |
value |
The fallback value to use |
No |
9.2. Instance Specific Files
If you run multiple TIF instances, you may in some cases need to have instance / node specific destinations file. This is supported and the order how the destinations.xml files is parsed is shown below.
-
etc/destinations.xml
-
etc/destinations-<TIF-INSTANCE-ID>.xml
-
etc/destinations-<TIF-NODE-ID>.xml
-
etc/destinations-<TIF-NODE-ID>-<TIF-INSTANCE-ID>.xml
9.3. File Destination
A file destination is used to define a location where files are either written to or read from.
Below is an example configuration of a File destination.
<Destinations>
<File id="file1"
directory="/var/transfer/tif"
filePrefix="ECO_"
fileSuffix=".xml"/>
</Destinations>The table below shows the available attributes on the File destination element.
| Attribute | Description | Required |
|---|---|---|
id |
A unique identifier. |
Yes |
directory |
The directory, which the files will be generated inside. You may use the following macros inside the value:
Use absolute paths, unless using a macro. |
Yes |
filePrefix |
The prefix, which the generated file will get. Note The length of the prefix must be at least three characters long. |
No |
fileSuffix |
The suffix, which the generated file will get. |
No |
fileName |
A static filename to be used if you want this destination to use the same file over and over again. |
No |
append |
True/false to append data. May be useful in combination with the fileName attribute |
No |
If your destination is used for writing data into,
then either the fileName or filePrefix attributes must be used.
|
9.4. HTTP Destination
A HTTP destination is used to transfer data into a remote server via HTTP.
Below is an example configuration of a HTTP destination that transfers data via HTTP/POST.
<Destinations>
<Http id="http-1"
url="http://server:port/app/servlet/test"
retryCount="3"
retryDelay="3000"
timeout="30000">
<Header name="Authorization" value="Bearer ABCDEF" />(1)
</Http>
</Destinations>| 1 | Optional headers can be applied |
The table below shows the available attributes on the HTTP destination element.
| Attribute | Description | Required |
|---|---|---|
id |
A unique identifier. |
Yes |
url |
The URL of the HTTP endpoint that will receive the data. |
Yes |
tokenResolver |
The ID of the token resolver to be used to establish additional authentication tokens |
No |
retryCount |
The number of times to retry sending if the remote server does not answer |
No |
retryDelay |
The delay in ms to wait between to retry attempts |
No |
timeout |
The connect timeout in ms |
No |
method |
Request method. Default is POST if not defined. |
No |
The HTTP destination also supports authentication using either Basic or Digest methods. Below is an example illustrating how to accomplish this.
<Destinations>
<Http>
<Authentication> (1)
<Basic/> (2)
<UserName>name of user</UserName> (3)
<Password>the password</Password> (4)
<Realm>the realm</Realm> (5)
</Authentication>
</Http>| 1 | Defines the authentication block |
| 2 | Either Basic or Digest can be used |
| 3 | Specifies username |
| 4 | Specifies the password |
| 5 | Specifies the authentication realm |
The password can be stored in encoded formats such as base 32 or base 64 values, or encoded using the ENOVIA/3DExperience MQL command "encrypt password". If an encoding strategy is used, the encoded password must be prefixed with the encoding format like this:
<Destinations>
<Http>
<Authentication>
<Basic/>
<UserName>name of user</UserName>
<Password>b64:aGVsbG8gd29ybGQ=</Password>
...
</Authentication>
</Http>The valid prefixes are:
-
plain
-
b64
-
b32
-
enovia
-
For passwords envoded with a MQL client prior to version 19xHF2
-
-
enovia-19x
-
For passwords encoded with a MQL client between the version 19xHF2 and 20x
-
-
enovia-21x
-
For passwords encoded with a MQL client of version 2021x or later.
-
The password can also be entered without prefix.
9.4.1. SSL Configuration
By default, all SSL certificates are trusted when transferring data to HTTPS destination. To improve security, you can change the behavior by configuring settings in ${TIF_ROOT}/etc/tif.custom.properties.
To configure settings, it is required to stop trusting all certificates:
https.client.disableTrustAll=true
When https.client.disableTrustAll is set true, the available settings are:
https.client.keyStore.path=<path to keystore, example: etc/keystore> https.client.keyStore.password=secret https.client.keyStore.type= https.client.keyStore.provider= https.client.keyManager.password= https.client.trustStore.path=<path to the trust-store, example: etc/keystore> https.client.trustStore.password=secret https.client.trustStore.type= https.client.trustStore.provider= https.client.includeCipherSuites=<comma separated list> https.client.excludeCipherSuites=<comma separated list>
At least a keystore and the password needs to be configured.
9.4.2. Preempt Basic Authentication
By default, when transferring data to a HTTP destination for the first time, TIF’s HTTP client does the following conversion with the destination:
-
The client sends a request.
-
The destination issues a challenge by responding with status code 401 and the header "WWW-Authenticate".
-
The client sends similar request, but with "Authorization" header.
If the authentication is successful, it is cached and reused for subsequent requests.
It is possible to preempt basic authentication by setting attribute preempt to true in element <Authentication>. In this case, the "Authorization" header is added immediately to the request without additional roundtrip to the destination.
9.5. JMS Destination
An example JMS destination is shown below:
<Destinations>
<JMS id="jms-1"
initialContextFactory="org.apache.activemq.jndi.ActiveMQInitialContextFactory"
providerURL="tcp://server:61616">
<Queue name="TestQueue1" jndiKey="queue.%s"/> (1)
</JMS>| 1 | The JMS element must contain either a <Topic> or a <Queue> child element. |
The attributes, which the JMS elements support, are shown in the table below:
| Attribute | Description | Note |
|---|---|---|
id |
A unique identifier. |
|
initialContextFactory |
The fully qualified name of the class that your JMS provider provides as InitialContextFactory. |
The JAR files that your JMS provider provides, should be put inside the folder |
providerURL |
The URL to your JMS broker |
|
user |
Optional user name |
Not required unless your JMS provider requires this when establishing the connection. |
password |
Optional password |
|
connectionFactoryKey |
When looking up the ConnectionFactory from the JNDI registry, a key is used for this lookup. By default, the key is assumed to be |
Not required. |
extensionId |
May be used to separate different implementation classes from each other. See below |
Not required |
The Queue or Topic element may have these attributes:
| Attribute | Description | Note |
|---|---|---|
name |
The name of the queue or topic to use |
Required |
jndiKey |
The key used to lookup this destination from the JNDI registry. By default this value is If your JMS provider uses a different naming convention for the JNDI lookup key of the destination, you need to configured this attribute accordingly. |
Optional |
Additional JNDI environment variables can be set via nested <Env> elements as shown below. This element supports two attributes: key and value. Example:
<JMS ...>
<Queue name="testqueue" jndiKey="destination.%s"/>
<Env key="a key" value="a value"/>
<Env key="another key" value="another value"/>
</JMS>9.5.1. Separation of Classes
Normally, the JMS provider specific classes should be put into ${TIF_HOME}/lib/custom. However,
if there are some collisions of classes, one can instead put these into a folder like this ${TIF_HOME}/extensions/<name-of-extension>.
Then you need to specify the name of the extension on the extensionId attribute on the JMS destination itself.
So if you put your implementation JAR files below ${TIF_HOME}/extensions/sib then your JMS destination needs the attribute extensionId="sib".
9.6. Rabbit MQ Destination
An example RabbitMQ destination is shown below:
<Destinations>
<RabbitMQ id="rabbitmq-1"
uri="amqp://userName:password@hostName:portNumber/virtualHost"
routingKey="rk1">
<Queue name="q1" autoDelete="false" durable="true" exclusive="false"/>
<Exchange name="e1" autoDelete="false" durable="true" type="direct"/>
</RabbitMQ>
</Destinations>The attributes for the <RabbitMQ> element is described in the table below:
| Attribute | Description | Note |
|---|---|---|
id |
A unique identifier. |
|
uri |
The AMQP URI |
|
userName |
The user name |
Not required if complete URI is defined |
password |
The password |
Not required if complete URI is defined |
hostname |
The host name of the Rabbit MQ server |
Not required if complete URI is defined |
port |
The port number of the Rabbit MQ server |
Not required if complete URI is defined |
virtualHost |
The virtual host name |
Not required if complete URI is defined |
routingKey |
The routing key to be used |
This can typically be overridden when the RabbitMQ destination is being used |
mandatory |
The mandatory flag |
Boolean (default: false) |
immediate |
The immediate flag |
Boolean (default: false) |
Attributes for the <Queue> element is described in the table below:
| Attribute | Description | Note |
|---|---|---|
name |
The name of the queue |
|
autoDelete |
||
durable |
||
exclusive |
Attributes for the <Exchange> element is described in the table below:
| Attribute | Description | Note |
|---|---|---|
name |
The name of the exchange |
|
autoDelete |
||
durable |
||
type |
The AMQP API supports providing arguments.
These can be declared on the <Queue> and <Exchange> elements as shown below:
<Destinations>
<RabbitMQ ...>
<Queue ...>
<Arg name="argument-name"
value="value of argument"
type="string | int | double | boolean | long | float"/>
...
</Queue>
</RabbitMQ>
</Destinations>9.7. SOAP Destination
The SOAP destination type is used when you post data to a SOAP based webservice.
To configure such destination, the syntax is shown below:
<Destinations>
<SOAP id="soap-1">
<ServiceURL>http://server:8080/axis2/services/PartInfoService/update</ServiceURL>
<Namespace prefix="part" uri="http://www.technia.com/part"/>
<Namespace prefix="doc" uri="http://www.technia.com/document"/>
...
<!-- To support basic authentication
<Authentication>
<UserName>A User</UserName>
<Password>The Password</Password>
</Authentication>
-->
<!-- following required for SOAP 1.1
<ActionBaseURL>http://localhost:8080/axis2/services/</ActionBaseURL>
<Action>PartInfoService</Action>
<Method>update</Method>
-->
</SOAP>
</Destinations>Some restrictions
-
The "ServiceURL" is mandatory.
-
Currently, you also need to specify the used XML namespaces in the payload. That is accomplished via the Namespace element.
-
The Authentication element is used to provide support for Basic authentication
-
Finally, if you call a SOAP 1.1 service, you need to specify SOAPAction header that is constructed of ActionBaseURL, Action and Method elements using format <ActionBaseURL><#><Action><:><Method>. See table below:
| Element | Description | Note |
|---|---|---|
ActionBaseURL |
Base URL appended to header |
Element must exist (with or without content) to include SOAPAction header |
Action |
Action appended (with leading # delimiter if ActionBaseURL is not empty) to header |
Optional |
Method |
Method appended (with leading : delimiter if ActionBaseURL and/or Action is not empty) to header |
Optional |
| To include an empty SOAPAction header, use empty element <ActionBaseURL/> and leave Action and Method unspecified. |
9.8. Native MQ / Websphere MQ /IBM MQ Destination
If you must send data to a IBM MQ queue using the Native MQ protocol, then you must declare a NativeMQ destination. An exaple of so is shown below:
<Destinations>
<NativeMQ id="mq1-partdata-req"
queueManagerName="QM_acme_mq"
hostName="192.168.1.10"
port="1414"
characterSet="1208"
encoding="546"
channel="S_acme_mq"
connectOptions="">
<Queue name="partdata_req" options="INPUT_AS_Q_DEF,OUTPUT"/>
</NativeMQ>
</Destinations>Attributes for the <NativeMQ> element is described in the table below:
| Attribute | Description | Note |
|---|---|---|
id |
The unique identifier |
|
queueManagerName |
The name of the MQ queue manager |
Required |
channel |
The channel to be used |
Required |
hostName |
Required |
|
port |
The port, which your queue manager uses |
Required |
characterSet |
Default message character set |
|
encoding |
Default message encoding |
|
priority |
Default message priority |
|
expiracy |
Default expiracy value |
|
connectOptions |
Optional additional connect options |
|
ccsid |
The <Queue> element supports these attributes:
-
name: The name of the queue -
optionsComma separated list of MQOO option (MQ Open Options)Example:
INPUT_AS_Q_DEF,OUTPUT
9.9. Email destination
An email destination is used to send data to one or more email recipients. Below is an example configuration.
<Destinations>
<Email id="email-1" subject="My Test Message">
<To>example1@technia.com</To>
<To>example2@technia.com</To>
<Cc>example3@technia.com</Cc>
<Bcc>example4@technia.com</Bcc>
</Email>
</Destinations>The table below describes the available attributes for element Email.
| Attribute | Description | Required |
|---|---|---|
id |
A unique identifier. |
Yes |
subject |
The "Subject" header field of message. |
No |
The table below describes the available sub elements for element Email.
| Element | Description | Required |
|---|---|---|
To |
The "To" (primary) recipient. At least one must be defined. |
Yes |
Cc |
The "Cc" (carbon copy) recipient. One or more can be defined. |
No |
Bcc |
The "Bcc" (blind carbon copy) recipient. One or more can be defined. |
No |
|
Mail Settings
Mail settings must be configured to enable email destination. See chapter Configure Mail Settings. |
9.10. FTP destination
An FTP destination is used to send data to a file located in an FTP(S) server. Below is an example configuration.
<Destinations>
<FTP id="ftp-1"
hostName="myHost"
port="21"
userName="myUserName"
password="myPassword"
directory="myDir/mySubDir"
filePrefix="myPrefix-"
fileSuffix=".xml"
existStrategy="replace"
useSSL="false"
implicit="false"
usePROTP="true" />
</Destinations>The table below describes the available attributes for element FTP.
| Attribute | Description | Required | Default Value |
|---|---|---|---|
id |
A unique identifier. |
Yes |
|
hostName |
Host name of a FTP(S) server. |
Yes |
|
port |
Port number of the server. Default one is used if not defined. |
No |
|
userName |
Name of a user that is logged in. |
No |
|
password |
User’s password. |
No |
|
directory |
A directory to which the file is uploaded. If not defined, default working directory is used. |
No |
|
fileName |
A static name for the uploaded file. If defined, |
No |
|
filePrefix |
A prefix which the uploaded file will get. If |
No |
|
fileSuffix |
A suffix which the uploaded file will get. If |
No |
|
existStrategy |
Defines what happens if a file with You may use the following values:
|
No |
fail |
useSSL |
Defines if an SSL connection is used to communicate with the FTP Server. Use value "true" or "false". |
No |
false |
implicit |
Defines if implicit security mode is used. Use value "true" to enable implicit mode or "false" for explicit mode. If |
No |
false |
usePROTP |
Defines if command "PROT P" is executed in the server. This means private security mode is used. Use value "true" or "false". If |
No |
false |
Either fileName or filePrefix is required. If fileName is not defined, the name of uploaded file will consist of filePrefix, a random string and optional fileSuffix.
|
TLS session presumption is not supported when PROT P (usePROTP) is used.
|
9.11. Kafka Destination
A Kafka destination is used to send data to a Kafka topic.
Example configuration:
<Destinations>
<Kafka id="kafka-test-1"
bootstrapServer="server1:9092,server2:9092,server3:9092"
acks="all"
linger="5"
clientId="${tif.node}_${tif.instance}"
topic="test-1">
<ProducerProperty name="" value="" />
</Kafka>
</Destinations>The table below describes the available attributes for element Kafka.
| Attribute | Description | Consumer / Producer | Required | Default Value |
|---|---|---|---|---|
id |
A unique identifier. |
Both |
Yes |
|
bootstrapServer |
Comma separated list of Kafka bootstrap server(s) |
Both |
Yes |
|
clientId |
Define a string used to identify the client. Can include macros |
Both |
No |
|
acks |
Define the acks value |
P |
No |
1 |
linger |
Define the Kafka linger in MS |
P |
No |
0 |
topic |
Defines a default topic to be used when using this destination. |
Both |
No |
|
groupId |
Defines what consumer group to join |
C |
No |
In addition, you can also:
-
Add custom producer properties via nested
<ProducerProperty>elements. -
Add custom consumer properties via nested
<ConsumerProperty>elements. -
Define custom headers to be sent when producing data via nested
<Header>elements
The nested <ProducerProperty>, <ConsumerProperty> and <Header> elements uses the attributes name and value.
|
Per default, TIF will produce data to a Kafka topic using a string encoder for the keys and a byte-array encoder for the values. When TIF consumes data from Kafka, it will deserialize both the keys and values using a String decoder. |
9.12. Handling Delivery Failures
If a delivery fails to some destination, you can configure an error handler per each destination.
To do so, use the XML format as shown below: (Example used for RabbitMQ, but applies to all destination types).
<Destinations>
<RabbitMQ ...>
<OnError> (1)
<SendMail>
<Subject>Unable to use RabbitMQ destination</Subject>
<TO>support@company.com</TO>
<TO>another@company.com</TO>
<CC>tif.admin@company.com</CC>
<ContentType>text/plain</ContentType>
<Message>
An error occured. Error message was: ${ERROR_MESSAGE} (2)
Pls look at the stack trace below.
${STACK_TRACE} (2)
</Message>
</SendMail>
</OnError>
</RabbitMQ>
</Destinations>| 1 | The <OnError> element is supported on all destinations. |
| 2 | The macros ERROR_MESSAGE and STACK_TRACE refers to the exception raised during the use of the destination. |
An alternative approach is to implement a custom ErrorHandler
<Destinations>
<RabbitMQ ...>
<OnError>
<Handler>name of class</Handler> (1)
</OnError>
</RabbitMQ>
</Destinations>| 1 | The class specified here must implement com.technia.tif.core.error.ErrorHandler |
10. Log Settings
Log settings are configured in file logback.xml that is located in ${TIF_ROOT}/etc.
The file can be modified to configure where TIF log messages will be written. Also, you can configure log level for each package.
10.1. Logging from Custom Classes
Use classes org.slf4j.Logger and org.slf4j.LoggerFactory when logging and add your Java package name along with a suitable log level to logback.xml.
For example:
package com.acme;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class YourClass {
private static final Logger logger = LoggerFactory.getLogger(YourClass.class);
public void yourMethod() {
// The following will construct a debug message 'This is your debug message'.
String yourParam = "your debug message";
logger.debug("This is {}", yourParam);
}
}Add a logger with the package name to logback.xml:
<configuration>
...
<logger name="com.acme" level="DEBUG"/>
...
</configuration>