enovia.host = http://server:8001/internalTIF Administration and Configuration Guide - {x-enovia-brand} Connector
15 January 2016
Table of Contents
- 1. Legal Notes
- 2. Overview
- 3. Module Settings
- 4. Class Loading
- 5. Configuration Files
- 5.1. Naming
- 5.2. Domains or Namespaces
- 5.3. Accessing an XML Based Resource
- 5.4. Location of Resource Files
- 5.5. Configure Additional Configuration Directory
- 5.6. XML Schemas
- 5.7. Reloading of XML based resources
- 5.8. Special Configurations - Service Activators
- 5.9. Working with Resources Stored on the Classpath
- 5.10. Dataset Definition
- 5.11. Table Definition
- 5.12. Payload Definition
- 6. Jobs and Queues
- 7. Outbound Integration Jobs
- 8. Inbound Integration Jobs
- 8.1. Configurable SOAP Web Services
- 8.2. Hosting SOAP Web Service
- 8.3. Directory / File Listener
- 8.4. JMS Listener / Message Receiver
- 8.5. RabbitMQ Listener / Message Receiver
- 8.6. Kafka Message Receiver
- 8.7. IBM MQ Listener / Message Receiver
- 8.8. Configurable RESTful Web Services
- 8.8.1. URL to a service
- 8.8.2. Context Path to REST services
- 8.8.3. Example Configuration
- 8.8.4. Configuration
- 8.8.5. Lifecycle of a Call
- 8.8.6. Credentials
- 8.8.7. Access
- 8.8.8. Id Locators
- 8.8.9. Operation
- 8.8.10. Payload Read Operation
- 8.8.11. File Read Operation
- 8.8.12. File Update Operation
- 8.8.13. Create new Job Operation
- 8.8.14. HTTP Status Codes
- 8.9. Hosting RESTful Web Service
- 8.10. Apache CXF Base Web Application
- 8.11. Reply Handler
- 8.12. Create / Update Integration
- 8.12.1. Contextual or Non-Contextual
- 8.12.2. Configuration File
- 8.12.3. Input Formats
- 8.12.4. Entry Point
- 8.12.5. Config
- 8.12.6. IdentityMatch
- 8.12.7. CreateValues
- 8.12.8. UpdateValues
- 8.12.9. CustomField
- 8.12.10. Connections
- 8.12.11. EmbeddedFiles
- 8.12.12. ExternalFiles
- 8.12.13. ValueMapper
- 8.12.14. Namespaces
- 8.12.15. Revising
- 8.12.16. Example Configuration
- 8.12.17. Trigger a Create/Update Integration via REST
- 8.12.18. Trigger a Create/Update Integration via JMS
- 8.12.19. Trigger a Create/Update Integration via Kafka
- 8.12.20. Trigger a Create/Update Integration via File
- 8.12.21. Extension Points
- 8.12.22. Debugging
- 9. Batch Jobs
- 10. Scheduled Jobs
- 11. Job Events
- 12. Miscellaneous Settings
1. Legal Notes
© Copyright 2003-2022 by TECHNIA AB
All rights reserved.
PROPRIETARY RIGHTS NOTICE: This documentation is proprietary property of TECHNIA AB. In accordance with the terms and conditions of the Software License Agreement between the Customer and TECHNIA AB, the Customer is allowed to print as many copies as necessary of documentation copyrighted by TECHNIA relating to the software being used. This documentation shall be treated as confidential information and should be used only by employees or contractors with the Customer in accordance with the Agreement.
This product includes software developed by the Apache Software Foundation. (http://www.apache.org/).
2. Overview
The ENOVIA/3DExperience connector is a module within TIF that knows about ENOVIA/3DExperience and how to connect with the ENOVIA/3DExperience database.
The ENOVIA/3DExperience connector is installed below the ${TIF_ROOT}/modules/enovia folder, from now on referred to as the module home directory.
Please also read the chapter "Installation Overview" in this document in order to understand the different connection alternatives. In case you don’t connect with ENOVIA/3DExperience in RIP mode (the default mode), then you need to configure the enovia host connection within the "tvc.custom.properties" file (see chapter below).
2.1. Directory Layout
Within the enovia module directory, you will have a number of sub-directories:
- etc
-
Contains for example
-
The properties file controlling the behavior of this module
-
The properties file used when initializing TVC.
-
Note that the ENOVIA/3DExperience Connector is built upon the TVC-Core framework. (TVC =Technia Value Components)
-
-
Configuration file for scheduled jobs.
-
- lib
-
The JAR files required by the ENOVIA/3DExperience connector. Custom jar files are stored in a sub folder of the
libfolder. - cfg
-
Holds the configuration files. Mainly XML configuration files, but others like XSLT/Freemarker templates/XML Schemas are also located here) that you are using inside your integration jobs.
Might for example be job-configurations, payload definitions, data-sets, tables, inquiries etc.
This directory contains the similar file as you use in the ordinary ENOVIA/3DExperience web-application below the
WEB-INF/tvcfolder (in case you are using TVC as a part of your ENOVIA/3DExperience application). - webapps
-
Contains custom web-applications, which this module has. By default, there are a couple of applications available like the administration UI, RESTful Webservice support and SOAP based Webservice support.
|
Never modify the original properties files that are part of the distribution. For example instead of changing the The customized properties file is propagated with the original file upon start up, and the customized file takes precedence over the original. |
2.2. JAR File Loading
Your integrations requires the same JAR files as you have in your ENOVIA/3DExperience application, such as the eMatrixServletRMI.jar among others.
Hence these JAR files must be available for the ENOVIA/3DExperience Connector in TIF in order to work correctly.
There are two options how to ensure that TIF uses these JAR files, namely:
-
In the start script to TIF, point out the root directory of your ENOVIA/3DExperience web-application. TIF will during start up scan the directories
WEB-INF/classesandWEB-INF/liband include the resources in the class-path automatically. -
Copy required JARs from the
WEB-INF/libandWEB-INF/classesinto thelib/customfolder.-
The minimum required JAR files are:
-
eMatrixServletRMI.jar
-
enoviaKernel.jar
-
FcsClient.jar
-
FcsClientLargeFile.jar
-
Mx_jdom.jar
-
-
The first alternative is the recommended approach since that reduces the risk of not having the content synchronized between the app-server and the TIF server.
If you for some reason cannot link directly to your ENOVIA/3DExperience web-application root directory, you can possibly copy the whole application to some place on the TIF server.
|
Never add your own JAR files into the |
2.3. Configure TVC Properties
If you need to change or apply some TVC specific setting (init parameter), then
you can do so by creating a file called tvc.custom.properties within the directory ${TIF_ROOT}/modules/enovia/etc.
In there you add the parameters using property file format (key = value).
2.4. Multiple Instances
| Before reading this, ensure that you also read this chapter. |
If you wish to configure things different per TIF instance, you should create a file
called ${TIF_ROOT}/modules/enovia/etc/${INSTANCE_ID}.properties and add the instance specific
configuration in there.
The order the properties files are read is:
-
${TIF_ROOT}/modules/enovia/etc/module.properties -
${TIF_ROOT}/modules/enovia/etc/module.custom.properties -
${TIF_ROOT}/modules/enovia/etc/${INSTANCE_ID}.properties
When setting up multiple instances of TIF you should consider for example if all instances should poll the default queue in ENOVIA/3DExperience for new jobs, or if all instances should listen to the same JMS/MQ/AMQP queues.
Also see the this chapter for additional information about reply handlers and use of JMS correlation id’s and IBM-MQ group id’s.
3. Module Settings
The settings for the ENOVIA/3DExperience Connector in TIF is found inside the file ${TIF_ROOT}/modules/enovia/etc/module.properties.
If you want to change or add something in this file, create an empty
file with name module.custom.properties in the same directory.
All your changes should go into the customized file.
|
Note also that you may apply instance specific properties. This may be important in case you have multiple TIF instances running and you need to configure the instances slightly different.
Read here for more details.
3.1. JAR Inclusion / Exclusion
In order to be able to connect to ENOVIA/3DExperience with the Java API, you
need some JAR files from the ENOVIA/3DExperience installation. One way to do this is to
set the WEBAPP_ROOT environment variable pointing to the root of your ENOVIA/3DExperience
web application when starting up TIF. Typically this is done within the
${TIF_HOME}/bin/setenv.sh script or similar.
Note that some JAR files that you might have in the web application you point out, may contain JAR files that is in conflict with what TIF is using. Hence, you need to be able to control what to include/exclude.
The following properties are used to control this.
-
include.jar.file.pattern.defaults
-
include.jar.file.pattern
-
exclude.jar.file.pattern.defaults
-
exclude.jar.file.pattern
The properties ending with .defaults contains a pre-defined list of JAR files to
either include or exclude provided by TIF. Generally, you should not override
or modify these properties.
Instead, to control what to be excluded OR included, use these properties within your custom configuration file.
-
include.jar.file.pattern
-
exclude.jar.file.pattern
Both of these properties contains a ; separated list of regular expressions
that are matched on the files in the web application (the lib directory).
| As of version 2020.1.0, a more restrictive strategy was introduced (the include pattern) due to increasing number of support tickets caused by including too many conflicting JAR files in TIF. |
Per default, TIF provides both a list of JARs to be included and a list of JARs to be excluded. And these are defined as follows:
exclude.jar.file.pattern.defaults=mx_axis.jar;\
slf4j-.*\.jar;\
logback-classic.jar;\
logback-core.jar;\
profiler-server.jar;\
tvc-collaboration-.*\.jar;\
tif-enovia-client-.*.jar;\
jsf-.*\.jar;\
jstl-.*\.jar;\
ehcache-.*\.jar;\
enoappmvc.jar;\
fasterxml-jackson.*.jar;\
jackson-.*.jar;\
javax.*.jar;\
.*rest.*.jar
exclude.jar.file.pattern=
include.jar.file.pattern.defaults=eMatrixServletRMI.jar;\
enoviaKernel.jar;\
FcsClient.jar;\
FcsClientLargeFile.jar;\
Mx_jdom.jar;\
search_common.jar
include.jar.file.pattern=Moreover, you can disable a pattern completely by using any of these properties
include.jar.file.pattern.enabled=true
exclude.jar.file.pattern.enabled=trueSo to revert back to pre-2020.1.0 behaviour, you can simply add this into your custom property file.
include.jar.file.pattern.enabled=true3.2. HTTP Support
There is support for HTTP inside TIF, for example running Webservices etc.
You may disable HTTP, or make configuration changes such as changing context paths. All of this is defined in the module.settings file.
3.3. Integration with Elastic Search
You can configure TIF to integrate with Elasticsearch in order to enhance the usage of the Admin UI.
This in turn will also reduce the load on the TIF server since some queries from the Admin UI adds a lot of work to the TIF server. E.g. CPU/memory can be used for job processing instead of running expensive Admin UI queries.
You need to install Elasticsearch as a separate service. We have tested TIF with versions 6.2 up-to 7.1 of Elasticsearch.
After setup of the Elasticsearch server, you need to configure some properties on the TIF side.
searchIndexer=elasticsearch
elasticSearch.hosts=http://name-of-host:9200There are plenty of other properties that plays a role, but by default you don’t need to deal with them.
You can read more about these properties within the module.properties file.
|
If you have multiple TIF instances in your production system, all of these should use the same Elasticsearch instance. TIF separates the data within the index by the tif-node-id AND tif-instance-id. But, don’t use the same Elasticsearch index for TEST instances as you use for your PRODUCTION instances. |
3.3.1. Search Index Synchronization
TIF has a routine for adding legacy data not yet being indexed, to the index by a Search Index Synchronizer.
|
If your database contains large amount of jobs and payload data, it may take some time to completely add all data into the index. The data is added to the index in chunks in order to not make the TIF server unresponsive. |
There is a background task running on the TIF server that takes care about this.
This task is configured by default like this:
searchIndexer.synchronizer.execute=0 0/5 * * * ?
searchIndexer.synchronizer.job.chunkSize=2000
searchIndexer.synchronizer.job.maxIterations=100
searchIndexer.synchronizer.payload.chunkSize=300
searchIndexer.synchronizer.payload.maxIterations=100E.g. every fifth minute, look for un-indexed data. On each run, run maximum 100 iterations and on each iteration try to index max 2000 jobs.
You may need to elaborate on these settings to your environment. It may also be wise to use different values during the initial period when all legacy data is being added to the index, and later change to run this routine less often.
The payload data will be added to the index AFTER all jobs have been added.
| The chunk size for payload may need to be changed depending on typical/average size of your payload data. |
If either chunk size or max iterations is set to a negative value, then no synchronization will be made for that type.
Un-indexed data is either job-data being created in the past OR job-data that is created during a period when TIF does not have contact with your Elasticsearch server.
3.4. Clean-up and Maintenance Routines
Cleaning up of expired integration data is performed by dedicated scheduled maintenance tasks. These scheduled tasks are called "cleansers".
The integration data consists of meta data that is persisted in the TIF database, and of payload data files that are saved in TIF’s data folder. The data expires according to service history settings that define how long jobs are kept in the database, and whether to store payloads. Service settings can be configured via TIF Admin UI. The default settings will be applied in case a service has no specific configuration.
The cleanser task configurations are defined in ${TIF_ROOT}/modules/enovia/etc/module.properties.
See also default service settings in Service settings.
| Make sure you configure suitable default history settings before enabling job/payload cleansers. |
In addition to the cleansers, there are also some other maintenance tasks, e.g. for updating search index and calculating some statistics.
3.4.1. Scheduled Maintenance Tasks
Below is a diagram illustrating the different maintenance tasks.
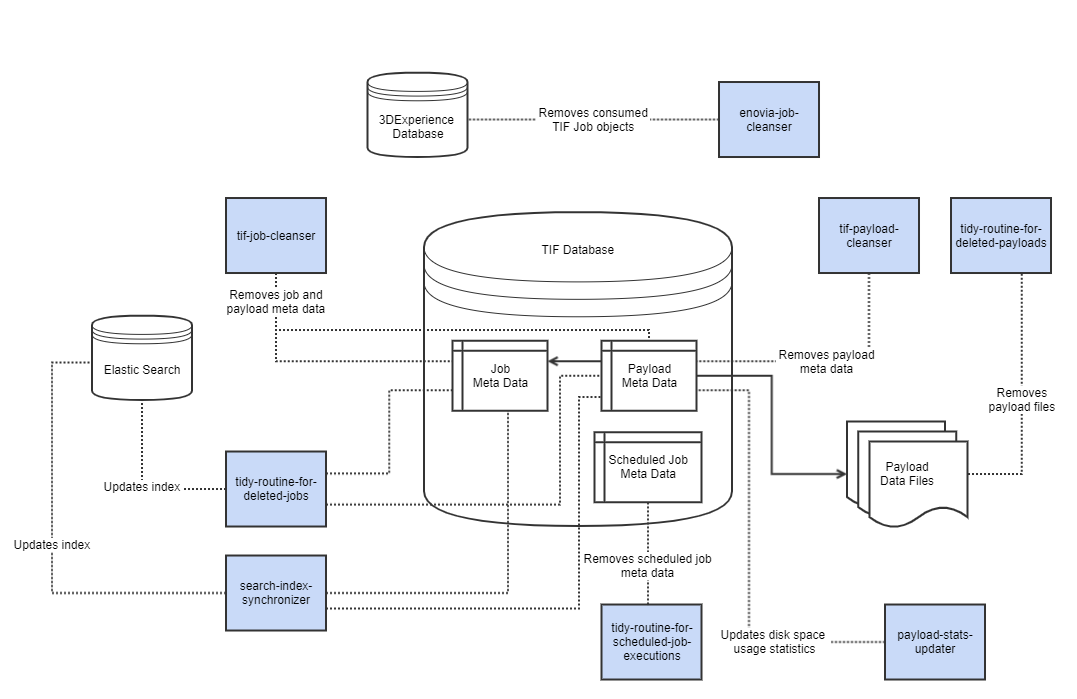
Figure 1. Cleansers
Job Cleanser (tif-job-cleanser)
The task tif-job-cleanser cleans up meta data of expired jobs. The meta data is persisted in the TIF database. Whenever a job is removed,
also associated payload meta data is removed.
Please note that tif-job-cleanser will only remove meta data from the TIF database, and does not remove actual payload data files that are stored outside the TIF database.
There are separate tasks tidy-routine-for-deleted-jobs and tidy-routine-for-deleted-payloads for removing payload files and updating search index
(if TIF is integrated with Elastic Search).
Payload Cleanser (tif-payload-cleanser)
The task tif-payload-cleanser cleans up payload meta data produced by services that are configured not to store payloads.
Deleted Job Cleanser (tidy-routine-for-deleted-jobs)
The task tidy-routine-for-deleted-jobs updates search index by cleaning up references to removed meta data.
Deleted Payload Cleanser (tidy-routine-for-deleted-payloads)
The task tidy-routine-for-deleted-payloads deletes payload data files. This
occurs after the payload meta data is removed from the database.
ENOVIA/3DExperience Job Cleanser (enovia-job-cleaner)
The task enovia-job-cleaner removes "TIF Job" business objects from the ENOVIA/3DExperience database.
Objects contain necessary parameters to trigger an outbound integration, and those are consumed by TIF server.
Scheduled Job Cleanser (tidy-routine-for-scheduled-job-executions)
Clean-up routine for old scheduled job executions is performed by scheduled job
tidy-routine-for-scheduled-job-executions under group "tif-internal-maintenance-jobs".
By default, the clean-up runs once per hour and keeps 20 newest execution entries in the log history.
The settings can be configured in ${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
Defaults are as follows:
scheduledJobCleanser.enabled=true
scheduledJobCleanser.execute=0 0 0-23 * * ?
scheduledJobCleanser.keepCount=203.4.2. Scheduling Cleansers
All cleanser tasks can be scheduled to be run periodically at fixed times, dates, or intervals.
Schedule is configured in execute property that expects a standard Cron expression (https://en.wikipedia.org/wiki/Cron)
For example:
jobCleanser.execute = 0 15 2 * * ?In the above example, cleanser will run at 02:15:00 am every day.
In some cases it might be necessary to adjust the schedule. There are some recommendations:
-
Make sure the cleansers are executed regularly in order to prevent the TIF database from growing too much. Although the database is initialized with internal indexing, cleaning up of a large database might affect to overall performance.
-
The cleansers might perform heavy database queries, so it is not recommended to schedule all tasks to be run in parallel.
-
If possible, consider executing tasks in a window when there are less integration activities.
-
In addition to the schedule, please notice it is also possible to adjust cleanser query parameters that might improve the performance, please see the next chapter.
3.4.3. Adjusting Cleanser Database Queries
The cleansers performs database select and update queries that might be consuming depending on the size of the database.
In order to prevent performance problems, you may configure cleansers to split queries and/or limit the query size.
For example:
jobCleanser.deleteLimit = 10000
jobCleanser.maxIterations = 5This configuration restricts a cleanser to delete maximum of 10000 jobs per one query and perform maximum of 5 queries per one execution. Thus, the cleanser can delete maximum of 50000 jobs in total per one execution.
In addition to deleteLimit and maxIterations you may also adjust the schedule to
control how often cleansers are executed.
To prevent the database from growing too much, a general guideline is to configure cleansers to clean up at least the same amount of expired jobs/payloads that are created by average.
4. Class Loading
How the class loading mechanism in TIF is working is important to understand if you will add customized code into TIF.
Below is a diagram showing the hierarchy:
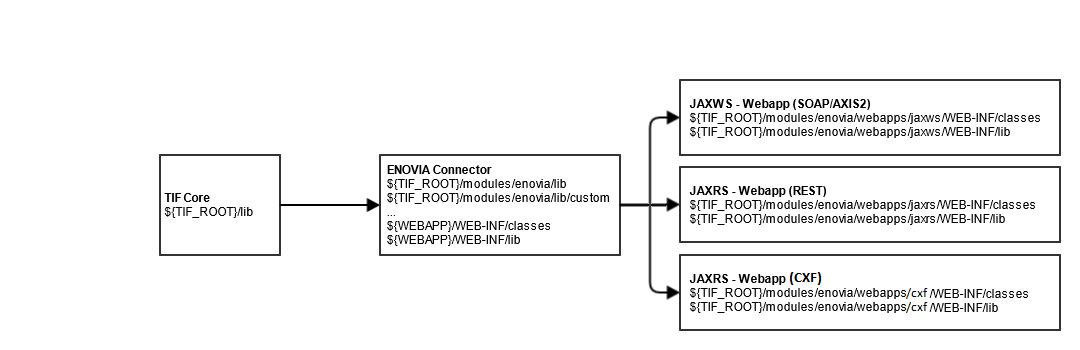
Figure 2. Classloader Hierarchy
The top level class loader contains the classes found from JAR files inside ${TIF_ROOT}/lib. These classes are visible for all modules in TIF.
The ENOVIA/3DExperience connector has it’s own class loader, with the TIF-core class-loader as parent.
This class-loader loads classes from the lib and lib/custom directories of that module by default as well as (if configured via start-script) the web-application resources (WEB-INF/lib, WEB-INF/classes).
Within the ENOVIA/3DExperience connector, there exists web-applications supporting SOAP, REST and Apache CXF based web services. Each of these is placed in a separate web-app using their own class loader. The folders WEB-INF/classes and WEB-INF/lib beneath each webapp is then part of the classpath.
The table below explains where to place custom classes:
| Folder | What to place |
|---|---|
|
Custom classes related to TIF core, such as custom destinations. |
|
Custom classes that customize behavior of ENOVIA/3DExperience connector related actions. |
|
Custom classes related to REST based web services |
|
Custom classes related to SOAP based web services |
|
Custom classes related to Apache CXF based web services |
5. Configuration Files
TIF allows a great amount of possibilities to configure your integration use cases instead of directly having to write Java code. This is accomplished by using XML definitions (or XML configurations) that contains the configuration details. In some cases, other kind of configuration files than XML files are used such as script files.
TIF is built upon the TVC (Technia Value Components) software and hence utilizes the resource/configuration loading capabilities provided by TVC Core. If you are familiar using TVC together with your ENOVIA/3DExperience web-application, you might already be aware of how to use these XML configurations.
Below is a list showing some commonly used XML configuration types within TIF.
- jobcfg
-
XML files describing a job e.g. job configuration
- payload
-
XML files defining how to create the payload data e.g. payload definition.
- xsd
-
XML schema files used for validation of XML data, for example when validating the generated payload data being sent to some destination.
- xslt
-
XSLT files used to transform XML files into different formats.
- table
-
XML files defining tables that are being used when extracting data from ENOVIA/3DExperience
- tablecolumn
-
Columns used across several tables can be placed in its own files in order to encourage reuse.
- dataset
-
XML files defining data-sets that defines what data to be included in the creation of the payload.
- createconfig
-
Configuration for the Create/Update integration.
- soapservice
-
Definition of a configurable SOAP service.
- restservice
-
Definition of a configurable REST service
- script
-
Script files containing script code being executed by the JVM.
- template
-
Template files used for generating payload. E.g Apache Freemarker templates
- xmlspec
-
XML Specification used to adapt the generated/raw XML as generated from the Java objects. The XML spec allows you to produce XML data that requires less transformation rules than otherwise is needed.
- directorylistener
-
Defines a directory/file listener used for performing actions on files
- jmslistener
-
Defines a JMS listener used for receiving messages from a JMS broker.
- rabbitmqlistener
-
Defines a Rabbit MQ listener used for receiving messages from a Rabbit MQ broker.
- mqlistener
-
Defines an IBM MQ listener that will receive messages from a MQ broker.
- replyhandler
-
Defines a handler being responsible for handling asynchronous replies. E.g responses to messages produced by an outbound integration job, typically messages obtained from a message broker or similar.
5.1. Naming
When referring to an XML based definition, one has to follow a special naming convention in order for TIF/TVC to recognize such a resource.
For example, if you somewhere in TIF wants to refer to a table that is defined in an XML file (and not a system table defined in the database), you may use the following naming convention to point to such resource:
tvc:table/EBOM.xml
5.2. Domains or Namespaces
It is also possible (and recommended) to use separate domains/namespaces for the resources. For example resources belonging to one domain of an application can be kept completely separate from another domain of an application. This is illustrated below:
tvc:table:sapintegration/EBOM.xml tvc:dataset:sapintegration/EBOMStructure.xml
In the example above we are referring to a table and a dataset stored in the namespace "sapintegration".
The number of configuration files tend to grow over time, and the domain/namespace concept allows arranging the configurations in relevance to a particular functionality or usecase.
| If you refer to a configuration file living in the "default" domain, you can in many cases omit the "tvc:<type>" prefix and only use the file name. |
5.3. Accessing an XML Based Resource
The table below illustrates how to correctly write the name of an XML based resource.
| Resource Type | Name Prefix |
|---|---|
Table |
tvc:table/MyTable.xml |
Table Column |
tvc:tablecolumn/MyColumn.xml |
Payload |
tvc:payload/PayloadExample.xml |
XSLT |
tvc:xslt/MyStylesheet.xslt |
When using domains, you have to apply the domain name after the resource type. For example:
tvc:table:mydomain/MyTable.xml
| It is not recommended to use a domain name, which is used for to represent a resource type. For example, you should not have a domain called "table", "payload", "dataset" etc. |
5.4. Location of Resource Files
The XML configuration files that are being used in many use cases in TIF are stored in the cfg folder under ${TIF_ROOT}/modules/enovia.
TIF uses the resource loading mechanism from TVC Core to resolve configuration files from this folder.
| In versions prior to 2016.2, the name of this directory was tvc-cfg. If this directory is present it will be added for convenience, however in some cases this may not work - especially for SOAP services defined in the "soapservice" directory due to limitations in the Axis2 deployer. |
If you are used to working with TVC in your ENOVIA/3DExperience application, the cfg folder corresponds to the WEB-INF/tvc folder.
The supported XML configuration types are the same as available in TVC with some additional configuration types provided by TIF, such as job-configurations, payload definitions, configurable web-services and others.
Once an XML resource is requested, the name of the resource is translated into a path, which points to the actual resource file. The list below shows the path for each resource type.
The translation of name to the actual file is:
${TIF_ROOT}/modules/enovia/cfg/${RESOURCETYPE}/${FILENAME}
| Resource Type | Location |
|---|---|
Table |
|
Table Column |
|
Payload |
|
XSLT |
|
When the resource refers to a resource under a specific domain, the name is translated according to the following rules:
${TIF_ROOT}/modules/enovia/cfg/${DOMAIN}/${RESOURCETYPE}/${FILENAME}
Below is a table showing some examples of paths translated
| Resource Type | Location |
|---|---|
Table |
|
Table Column |
|
Payload |
|
5.5. Configure Additional Configuration Directory
As mentioned in the previous chapter, configuration files are typically stored within ${TIF_ROOT}/modules/enovia/cfg.
Also, if your TIF start script points out the WEBAPP_ROOT_DIR, then the WEB-INF/tvc-ext and WEB-INF/tvc folders also will be added to the resource loader path.
In addition to this, there is also a Java system property called extraConfigDirectory that you could use to point out a custom directory,
from where additional configurations can be resolved.
If this property is present, the directory that is pointed out will be added first to the resource loader path.
In the Start script for TIF you could apply it like below:
export START_ARGS=-DextraConfigDirectory=/home/user/repos/test/cfg
...There are also some other properties (defined in module.properties) that you can use to control how the configuration files are being resolved.
| Name | Description |
|---|---|
configDirectory.webapp.enabled |
Can be used to disable loading configuration files from the webapplications WEB-INF/tvc folder (in case you reference the Web-app root dir in the start of TIF). |
configDirectory.default.enabled |
Can be used to disable loading configurations from the default "cfg" folder. |
5.6. XML Schemas
For most of the configuration files, there are XML schema files available for validation. These files will both be provided as a part of the TIF distribution and also available online.
The schema files are located under ${TIF_ROOT}/modules/enovia/schema
| Type | Local Schema File | Remote URL | Namespace |
|---|---|---|---|
jobcfg |
|
||
payload |
|
||
createconfig |
|
||
replyhandler |
|
||
restservice |
|
||
soapservice |
|
||
xmlspec |
|
||
table |
- |
||
tablecolumn |
- |
||
dataset |
- |
||
directorylistener |
|
||
jmslistener |
|
||
amqplistener |
|
||
mqlistener |
|
||
kafkalistener |
|
Example how to reference an XML schema from a configuration file:
<?xml version="1.0"?>
<tif:Job
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:tif="http://technia.com/TIF/JobCfg"
xmlns:common="http://technia.com/TIF/Common"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://technia.com/TIF/JobCfg http://products.technia.com/tif/schema/latest/JobCfg.xsd">
</tif:Job>5.7. Reloading of XML based resources
When a resource file is changed, for example a table is updated; TIF/TVC will (if TIF/TVC is started in development mode) reload the resource automatically, this is done by checking the modified timestamp on the file.
If TIF/TVC is started in PRODUCTION mode, you will need to clear the TVC cache in order to reflect the new changes, which could be done by connecting a JMX client to the JVM running TIF (there is a MBean available from TVC to clear the cache).
E.g. there is no need to restart the TIF server.
5.8. Special Configurations - Service Activators
Some configuration types in TIF corresponds to more complex deployment inside TIF. The configurations in question are listed below.
-
Directory Listener
-
JMS Listener
-
MQ Listener
-
AMQP Listener
-
Kafka Listener
-
Reply Handler
Instances of these configuration types are represented as service activators internally in TIF. They represent manageable functionality that can be started/stopped individually.
5.8.1. Hot Deployment of Service Activators
TIF allows hot deploying such configuration, meaning that creating, modifying or deleting such resource can be handled at runtime. Earlier in TIF, you had to restart the TIF server to handle changes in these configurations.
If you add a configuration of such type, a new service activator will be created and made available in TIF.
Same if you remove a configuration of this type, the corresponding service activator will be stopped and removed.
Changing a configuration of this type will, if the service activator is running, cause the service activator to restart with the configuration changes reflected in the service activator.
This feature is per default enabled but can be disabled via a setting in ${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
configChangeListener.enabled = false5.9. Working with Resources Stored on the Classpath
A resource can also be stored within the classpath (i.e. in a JAR file). To refer to such a resource, for example under /com/acme/resources/MyTable.xml, you have to write the name as:
tvc:table//com/acme/resources/MyTable.xmlIf you want to override the definition of the resource found in the classpath, you can then create a new file called MyTable.xml under the following directory:
${TIF_ROOT}/modules/enovia/cfg/table/com/acme/resources/MyTable.xmlThe internal resource handler in TVC will first look into such a directory and check if the resource exists there before retrieving it from the classpath.
5.10. Dataset Definition
Please goto this page.
5.11. Table Definition
Please goto this page.
5.12. Payload Definition
Please goto this page.
6. Jobs and Queues
Jobs executed on the TIF server may be initiated through some event within the ENOVIA/3DExperience web-application (or thick/rich client). You may for example configure a trigger that will initiate a job (for example promote event, create event etc.).
The kind of jobs that most typical is initiated in this way are Outbound Integration Jobs and/or Batch Jobs.
When this happens, then within the ENOVIA/3DExperience database a business object of type "TIF Job" in a separate vault dedicated to TIF is created. This job object holds the necessary information for the later execution of the Job on the TIF side. The Job object is then connected to a Queue object (type is "TIF Queue").
| These TIF Job business objects will after completion, at some point in the future, be deleted automatically by a scheduled task running at the TIF server. |
A job may be configured to be executed in one particular queue (if not defined, the default queue will be used). See chapter Create Trigger for some additional information. The reason for this might be to ensure that only certain TIF instances are processing certain jobs, and/or for scalability reasons.
A setup of TIF might look like the diagram below illustrates.
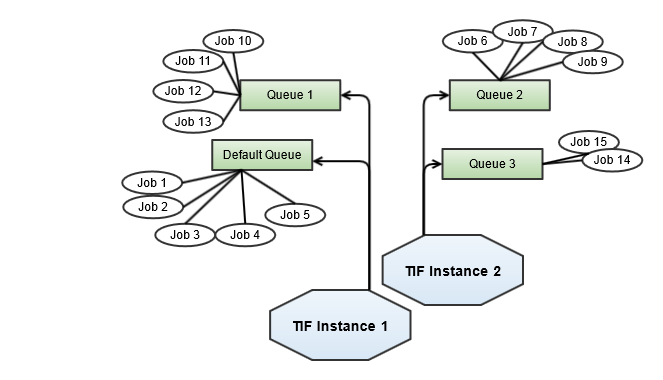
In this case we have four queues setup in ENOVIA/3DExperience and we are using two different TIF instances (TIF processes). TIF Instance 1 picks job from the default queue including the queue with name "Queue 1".
The second TIF instance processes jobs from "Queue 2" and "Queue 3".
To configure TIF for listening to a particular queue or configure it to NOT listen on the default queue, please look at the page Module Settings
6.1. Configuring Queues
In the module properties file you define which Queues you will listen to, e.g. what queues in ENOVIA/3DExperience you will process jobs for.
If you have setup several TIF instance, you may want to configure which instances that processes jobs from what queues.
By default, there is always a 'default queue' available in TIF. If you for example have multiple TIF instances running, each instance will by default process jobs from this default queue.
To disable listen on the default queue, you will use the following property
defaultQueueListener.enabled = falseMost common is to allocate jobs with the default queue. However, in some cases it might be useful to process certain jobs in its own queue. When you create the job object, you simply specify the name of the queue - this queue is automatically created if it doesn’t exist.
However, in order to process jobs from this queue, you need at least one TIF instance that listens on such queue.
In order to setup a listener for a particular queue, look at the example below:
queueListener.MyQueue.enabled = true
queueListener.MyQueue.name = My Queue
queueListener.MyQueue.threadCount = 5
queueListener.MyQueue.sleepInterval = 15000
queueListener.MyQueue.exclusive = false
The use of the prefix queueListener.MyQueue.
This prefix must be unique among your queues.
The name MyQueue may be whatever as long as the key itself is a valid Java property, however, recommended is to use something relevant for the queue in order to make debugging a bit easier.
|
The thread-count property defines how many worker threads will be used, e.g. how many concurrent jobs will be processed by this queue. Increasing this value will result in performance degradation.
The sleep-interval is a value in milliseconds defining how long time to sleep until next check (if no jobs were found in the queue in the previous check).
The exclusive flag should only be set if you are 100% sure that you don’t have any other TIF instance polling the same queue.
You may have the following optional properties:
queueListener.MyQueue.pickupDelay = 10It is possible to configure pickup delay in seconds. In practice, the queue listener reacts on created jobs with delay by not picking up jobs created within queueListener.MyQueue.pickupDelay.
The pickup delay works well in combination with exclusive jobs to prevent for example triggers from creating duplicate jobs.
It is also possible to configure pickup delay for jobs created in a certain queue OR for a certain job type via TVC init parameters. See the ENOVIA/3DExperience Client part of the documentation.
|
6.1.1. Create new Queue in ENOVIA/3DExperience
To setup a new queue in ENOVIA/3DExperience, use the following MQL code as base for so.
add bus "TIF Queue" "MyQueue" "" vault "TIF" policy "TIF Queue";6.1.2. Queue Polling
Jobs are polled from the queue in the order they are created. E.g. first in first out.
This is by default accomplished by performing an expansion of the Queue with limit 1.
There has been some issues reported related to returning of jobs in wrong order. This is caused by a bug in ENOVIA/3DExperience and to work around this issue - it is possible to change the polling strategy.
To change the polling strategy, use the property defaultQueuePollStrategy in module.properties.
Allowed values are
-
query-connection
-
expand-select
-
expand-iterator
-
expansion-iterator
-
mql-expand
-
mql-query
-
query
TIF will by default use either expand-iterator or expand-select depending on backend Database. But if you experience issues with job processing order, you should try changing this value to "query-connection".
7. Outbound Integration Jobs
An outbound integration job is a job that exports data from ENOVIA/3DExperience into another system (or systems) typically through some ESB (Enterprise Service Bus).
This kind of job is typically started based upon some event inside ENOVIA/3DExperience, for example a lifecycle promote event or new object revision event triggers the job. This kind of job may also be started on demand or via a scheduled event.
You can trigger a job manually from the ENOVIA/3DExperience-MQL client like this example shows
execute program TIFTrigger -method newJob 1.2.3.4 tvc:jobcfg/NAME_OF_CONFIG.xml;-
1.2.3.4is an ENOVIA/3DExperience object identifier -
You may for configurations in the default namespace omit the prefix
tvc:jobcfg/
| The jobs invoked in this manner are executed asynchronously, which is the normal usage pattern. If you need to invoke jobs in a synchronous way, please read this chapter. |
Read also this document for more information.
7.1. Transfer Data
An integration job that will extract data from the ENOVIA/3DExperience database and send it to some destination is called "Transfer Data Job".
To define this kind of job, you need to create a job definition/configuration that defines first how to extract the data (e.g. the payload) but also define the destinations, which the data is transferred to.
Transfer data jobs support job events for handling errors etc. Read more in the "Job Event" chapter.
Before digging into the details of the configuration format for such a job, we will start by showing an example of how such a configuration can look alike.
<Job>
<TransferData>
<Payload>tvc:payload/PartReleased.xml</Payload>
<Destinations>
<SysOut/>
<File id="fileDest1"/>
<Http id="httpDest1"/>
<RabbitMQ id="rabbitMQ1">
<RetryAttempts>10</RetryAttempts>
<RetryDelay>5000,10000,20000,30000,60000</RetryDelay>
<Header name="type" value="${job.rpe.TYPE}" type="string"/>
<HeaderProvider>name of class implementing com.technia.tif.enovia.job.destination.HeaderProvider</HeaderProvider>
</RabbitMQ>
</Destinations>
</TransferData>
<Events>
<Error>
<SendMail>
<TO>...</TO>
<CC>...</CC>
<Subject>...</Subject>
<Message>
message...
${STACK_TRACE}
</Message>
</SendMail>
</Error>
</Events>
</Job>The root tag in the definition is always <Job>. The first child element of the Job element defines the kind of job, in this case we will use the <TransferData> element to define the integration job.
Below the TransferData element, the following child elements are available.
<Payload>-
Defines the name of the payload definition that defines how the payload is being created.
<Destinations>-
Defines the destinations, to which the payload will be transferred.
<TransactionType>-
Defines the ENOVIA/3DExperience transaction type to be used during the job.
Each of these elements are defined in more detail in the sub-pages.
7.1.1. Payload
The Payload element points out the configuration that defines how to generate the payload (e.g. the data) from ENOVIA/3DExperience.
The value of the Payload element is either the XML configuration of type "payload" OR a Java class. See below for the two alternatives to define this.
Referencing a Payload Definition
Refer to payload configuration that contains the rules how to generate the payload.
<Job>
<TransferData>
<Payload>tvc:payload:namespace/ReleasedPart.xml</Payload>The referenced Payload configuration is the file cfg/namespace/payload/ReleasedPart.xml.
See page Payload Definition for details on how to define the payload definition.
Referencing a Custom Payload Generator
Refer to payload generator implemented in Java.
<Job>
<TransferData>
<Payload>java:com.acme.integration.MyPayloadGenerator</Payload>(1)| 1 | Note that we use the "java:" prefix. The class must implement the interface com.technia.tif.enovia.payload.Payload |
7.1.2. Destinations
The Destinations element within the <TransferData> parent element contains the target destination (or destinations),
which the generated Payload will be transferred to.
The connection specific details for a connection is specified in a centralized file. Please look at the page Configure Destinations for further details on this topic.
The table below shows the supported destination elements.
| Element | Descriptions | Supports Additional Headers | Supports Retry Attempt |
|---|---|---|---|
|
Useful during development to see the payload printed out to the system output. |
No |
No |
|
Sends the payload into a file. |
No |
No |
|
Sends the payload to a HTTP endpoint. |
Yes |
Yes |
|
Sends the payload to a SOAP service |
No |
Yes |
|
Sends the payload to a JMS queue or topic |
Yes |
Yes |
|
Sends the payload to an Rabbit MQ queue/topic (via AMQP) |
Yes |
Yes |
|
Sends the payload to a Native MQ destination |
Yes |
Yes |
|
Sends the payload to a email recipient |
No |
No |
|
Sends the payload to an Apache Kafka topic |
Yes |
No |
|
Defines a custom destination class. The class must extend from the base class |
- |
Yes (if class implements Retryable) |
|
The destination element(s) contains an "id" attribute, which refers to a corresponding destination definition within the However, the
|
Example
The example below will send the payload to:
-
the system-out (standard output)
-
file destination as configured with the ID "fileDest1" in the destinations.xml file
-
custom destination implemented by class "com.acme.integration.MyCustomDestination"
<Job>
<TransferData>
<Destinations>
<SysOut/>
<File id="fileDest1"/>
<SOAP id="webservice-test"/>
<Custom className="com.acme.integration.MyCustomDestination"/>
</Destinations>
</TransferData>
</Job>Conditionally Include Destination
You may specify conditions that must be met in order to transfer the payload to a certain destination.
Within the job configuration, the destination supports two different attributes called if and unless.
Here you specify the name (or names) of a property/parameter that must be OR must not be present on the Job itself in order to transfer the data to the destination in question.
Below is an example of using a conditionally inclusion of a destination:
<Job>
...
<TransferData>
...
<Destinations>
<Http id="http-1" if="send.to.1" />
<Http id="http-2" unless="send.to.1" />
</Destinations>
</TransferData>
</Job>JMS
The subchapters below describes the configuration aspects for a JMS destination.
JMS Reply To
You can specify a destination to which replies are generated. This is done via the replyTo attribute.
The value of this attribute must be the ID of an existing destination inside the destinations configuration file.
See chapter Configure Destinations for more information.
Below is an example how to configure the replyTo.
<JMS id="dest-id" replyTo="reply-dest-id" />And within the destinations.xml file:
<JMS id="dest-id"
initialContextFactory="org.apache.activemq.jndi.ActiveMQInitialContextFactory"
providerURL="tcp://172.16.16.141:61616">
<Queue name="part.info" jndiKey="queue.%s"/>
</JMS>
<JMS id="reply-dest-id"
initialContextFactory="org.apache.activemq.jndi.ActiveMQInitialContextFactory"
providerURL="tcp://172.16.16.141:61616">
<Queue name="part.info.reply" jndiKey="queue.%s"/>
</JMS>|
When you have set the attribute replyTo, then you should setup a so called reply-handler that is able to update TIF when the reply arrives in order to track whether or not the integration job failed or not. If you do not set up such reply handler, your jobs will stay in the state "Awaiting Reply". See chapter Reply Handler for further details. |
JMS Correlation ID
The correlation id of a message is by default set to:
${tif.instance.id}|${job.id}|${destination.id}This value contains macros, which during runtime are resolved to real values. The information in the correlation id is used for example by the reply handler to correlate a message back to its origin.
You may change this, but, please note that if you do then you must consider so in the reply-handler that you might use.
Below is an example how to configure the correlation id.
<JMS id="dest-id" correlationId="${job.id}/${destination.id}" />| The macros are described here |
JMS Type
You may specify a value for the JMS type property as shown below.
<JMS type="something" />
<JMS type="${macro}" />| The macros are described here |
JMS Priority
You may specify a value for the JMS message priority as shown below. The priority is a value between 0 and 9.
<JMS priority="4" />JMS Delivery Mode
You may specify persistent or non-persistent delivery modes by specifying this
in the deliveryMode attribute as shown below.
<JMS deliveryMode="non-persistent"/>
<JMS deliveryMode="persistent"/>JMS Message Type
When seding data to a JMS destination, TIF will by default use a StreamMessage when sending the content.
If you for some reason want to change the type, you can do so as shown below.
<JMS id="the-id" messageType="text"/>
<JMS id="the-id" messageType="byte"/>
<JMS id="the-id" messageType="stream"/>Additional Headers
Some destinations allow additional meta-data to be passed along with the payload itself. Such meta-data is called headers and consists of key/value pairs.
A header value can be static or dynamic. It is also possible to provide a custom class that provides the headers. These are exemplified below:
<Job>
<TransferData>
...
<Destinations>
<JMS ...>
<!-- Static parameter -->
<Header name="test1" value="bar"/>
<!-- Dynamic parameter, value taken from RPE (ENOVIA Runtime Program Env) -->
<Header name="test2" value="${job.rpe.TYPE}"/> (1)
<!-- Dynamic parameter, value taken from the additional arguments -->
<!-- passed via the trigger program object in ENOVIA for this job -->
<Header name="test3" value="${paramName}"/>
<!-- Define a custom header provider -->
<!-- Such class must implement the interface: -->
<!-- com.technia.tif.enovia.job.destination.HeaderProvider -->
<HeaderProvider>com.acme.foo.MyHeaderProvider</HeaderProvider>
</JMS>
...| 1 | The macros are described in this document |
Rabbit MQ / AMQP
The subchapters below describes the configuration aspects for a Rabbit MQ destination.
You can control the following aspects of a Rabbit MQ message:
-
Reply To
-
Correlation ID
-
Routing Key
-
Type
-
Priority
-
Delivery Mode
-
User ID
-
Application ID
Reply To
You can specify an exchange to which replies are generated.
This is done via the replyTo attribute.
The value of this attribute must be the name of an exchange in your Rabbit MQ broker.
Below is an example how to configure the replyTo.
<RabbitMQ id="rabbit-mq-dest-id" replyTo="NAME-OF-EXCHANGE" />If a job is sent to a Rabbit MQ destination whose replyTo has been set, the job will after being processed get the status "Awaiting Reply."
|
When you have set the attribute replyTo, then you should setup a so called reply-handler that is able to update TIF when the reply arrives in order to track whether or not the integration job failed or not. If you do not set up such reply handler, your jobs will stay in the state "Awaiting Reply". See this chapter for further details. |
Routing Key
The routing key can be defined in the destinations.xml file, but a more flexible approach is to define the routing key per use-case.
The routing key can be defined as macro, allowing to resolve dynamic value based upon some parameter etc.
Example:
<RabbitMQ id="rabbit-mq-dest-id"
routingKey="${job.param.NAME-OF-PARAM}" />| The macros are described here |
Correlation ID
The correlation id of a message is by default set to:
${tif.instance.id}|${job.id}|${destination.id}This value contains macros, which during runtime are resolved to real values. The information in the correlation id is used for example by the reply handler to correlate a message back to its origin.
You may change this, but, please note that if you do then you must consider so in the reply-handler that you might use.
Below is an example how to configure the correlation id.
<RabbitMQ id="rabbit-mq-dest-id"
replyTo="NAME-OF-EXCHANGE"
correlationId="${job.id}/${destination.id}" />| The macros are described here |
Type
You may specify a value for the type property as shown below.
<RabbitMQ type="something" />
<RabbitMQ type="${macro}" />| The macros are described here |
Priority
You may specify a value for the message priority as shown below. The priority is a value between 0 and 255.
<RabbitMQ priority="4" />Delivery Mode
You may specify persistent or non-persistent delivery modes by specifying this
in the deliveryMode attribute as shown below.
<RabbitMQ deliveryMode="non-persistent"/>
<RabbitMQ deliveryMode="persistent"/>IBM MQ (Native MQ)
The subchapters below describes the configuration aspects for a IBM MQ / Native MQ destination.
Reply To
You can specify a destination to which replies are generated. This is done via the replyTo attribute.
The value of this attribute must be the ID of an existing native-mq destination inside the destinations configuration file.
See chapter Configure Destinations for more information.
Below is an example how to configure the replyTo.
<NativeMQ id="mq-dest-id" replyTo="mq-reply-dest-id" />And within the destinations.xml file:
<NativeMQ id="mq-dest-id"
queueManagerName="QM_technia_mq"
hostName="172.16.16.141"
port="1414"
characterSet="1208"
encoding="546"
channel="S_technia_mq"
connectOptions="">
<Queue name="partdata_req" options="INPUT_AS_Q_DEF,OUTPUT"/>
</NativeMQ>
<NativeMQ id="mq-reply-dest-id"
queueManagerName="QM_technia_mq"
hostName="172.16.16.141"
port="1414"
characterSet="1208"
encoding="546"
channel="S_technia_mq"
connectOptions="">
<Queue name="partdata_resp" options="INPUT_AS_Q_DEF,OUTPUT"/>
</NativeMQ>|
When you have set the attribute replyTo, then you should setup a so called reply-handler that is able to update TIF when the reply arrives in order to track whether or not the integration job failed or not. If you do not set up such reply handler, your jobs will stay in the state "Awaiting Reply". See this chapter for further details. |
Correlation ID
The correlation id of a MQ message is by default set to and ID, which resolves to the ID of the transfer.
| A correlation id of a MQ message can only contain maximum 24 bytes. |
This value accepts macros, which during runtime are resolved to real values. The information in the correlation id is used for example by the reply handler to correlate a message back to its origin.
You may change this, but, please note that if you do then you must consider so in the reply-handler that you might use.
Below is an example how to configure the correlation id.
<NativeMQ id="dest-id" correlationId="${some.macro}" />See this section for more details regarding macros.
Group ID
A MQ Message sent from a TIF server contains per default the tif instance id as group id value. That information is used by reply handlers to only filter messages originating from a particular TIF instance.
If you only use one TIF instance, you may disable the use of group id’s.
To disable the use of group id’s, either specify this on the destination
element as shown below or globally in tif.custom.properties using the
property nativeMQ.defaultUseGroupId = false.
<NativeMQ id="..." setGroupId="false" />Message Type
There are different strategies available how to send the message. You may choose between one of the following
- string
-
The message read into a string and is sent using the
writeStringon the MQMessage - utfstring
-
The message read into a string and is sent using the
writeUTFon the MQMessage - byte
-
The message bytes are written using the
writemethod on the MQMessage.
You configure the strategy as shown below
<NativeMQ id="..." type="string" />The default strategy is byte.
Additional Settings
On the destination definition you may specify character-set, encoding, priority and expiracy. See this section for more details.
However, you may override these on the <NativeMQ> element per use case also.
Example:
<NativeMQ id="..."
encoding="546"
characterSet="1208"
priority="7"
expiracy="604800" />File
The File destination contains one configurable options, e.g. define whether or not the result is updated asynchronously.
Example:
<File id="file-1" asyncReply="true" />| If you utilize this feature you should configure a so called reply handler. You can read more about reply handlers here |
Kafka
The Kafka destination references the dito kafka-destination from the file ${TIF_ROOT}/etc/destinations.xml file using the id attribute.
See this document for more details.
General Usage
In your job configuration, you use the element <Kafka> to send data to a Kafka topic.
You can define the topic to transfer the data to using the topic attribute as shown below.
If you omit this attribute, the Kafka handler will try to resolve the topic from the destination with the given id.
<Job>
<TransferData>
<Payload>...</Payload>
<Destinations>
<Kafka id="kafka-1" (1)
topic="TIF-JOB-TEST" /> (2)
</Destinations>
</TransferData>
</Job>| 1 | Reference the destination via the id attribute |
| 2 | Here you define the topic to use. Note that you could define a topic in the core destination definition, and omit this one, or vice versa. The topic defined here takes precedence. |
Configure the Record Key
You can via the attribute keyMacro specify a macro that will resolve what key the produced Kafka record will use. Note that if you omit the keyMacro, then no key will be associated with the record.
Example below:
<Job>
<TransferData>
<Payload>...</Payload>
<Destinations>
<Kafka id="kafka-1" topic="TIF-JOB-TEST" keyMacro="${job.source.name}" />
</Destinations>
</TransferData>
</Job>This will use the name from the source object within ENOVIA, which the Job was created for.
Please see this document for details around using macros.
Asynchronous Replies
If you want to wait to complete the job after you have received a reply from Kafka, using a reply handler, you need to specify that the Kafka destination will produce a reply later.
This is controller via the asyncReply attribute.
<Kafka id="kafka-1" asyncReply="true" ... />Additional Headers
You can add headers also with the Kafka record that is being created.
First of all, any header specified within the used destination of ${TIF_HOME}/etc/destinations.xml will be added.
Additionally, you can specify extra headers per job configuration like shown below.
<Job>
<TransferData>
<Payload>...</Payload>
<Destinations>
<Kafka id="kafka-1" topic="TIF-JOB-TEST" keyMacro="${job.source.name}">
<Header name="replyTo" value="TIF-REPLY-TEST" />
<Header name="tifInstance" value="${tif.instance.id}" />
<Header name="jobId" value="${job.id}" />
<Header name="destinationId" value="${destination.id}" />
<Header name="sourceId" value="${job.source.id}" />
</Kafka>
</Destinations>
</TransferData>
</Job>As illustrated, the headers also supports macros to allow passing in dynamic values.
Another example shown below:
<Job>
<TransferData>
...
<Destinations>
<Kafka ...>
<!-- Static parameter -->
<Header name="test1" value="bar"/>
<!-- Dynamic parameter, value taken from RPE (ENOVIA Runtime Program Env) -->
<Header name="test2" value="${job.rpe.TYPE}"/> (1)
<!-- Dynamic parameter, value taken from the additional arguments -->
<!-- passed via the trigger program object in ENOVIA for this job -->
<Header name="test3" value="${paramName}"/>
<!-- Define a custom header provider -->
<!-- Such class must implement the interface: -->
<!-- com.technia.tif.enovia.job.destination.HeaderProvider -->
<HeaderProvider>com.acme.foo.MyHeaderProvider</HeaderProvider>
</Kafka>
...| 1 | The macros are described in this document |
The Email destination will by default include the content of the payload in the email as is (e.g. attachPayload is by default false). You can configure to attach the payload as a file to the mail instead, this is shown below.
<Email id="email-dest-1" attachPayload="true" attachAs="payload"/>The attachAs value is by default the static text payload, and you may change this to something more appropriate.
The value may be a macro that resolves to some dynamic string.
HTTP
The HTTP destination references the dito http-destination from the file ${TIF_ROOT}/etc/destinations.xml file using the id attribute.
See this document for more details.
The subchapter below describes the configuration aspects for an HTTP destination.
Macros in the URLs
In the ${TIF_ROOT}/etc/destinations.xml file, the url for the http destination is defined.
This URL may contain macros, which are resolved at runtime when the job is being executed.
The macro syntax is described in this document.
An example of this is shown below
<Destinations>
<Http id="http-1"
url="https://acme.org/z/service-a/${job.param.identifier}"
retryCount="1" retryDelay="1000" method="PUT">
</Destinations>Multipart
When transfering the payload to a destination, you can configure the Http request to send the file as a multipart request.
<Job>
...
<Destinations>
<Http id="system-x" multiPart="true" />
</Destinations>
</Job>Per default the file is send using the parameter file but the attribute multiPartFileParam can be used to change this to something else.
Also, the attribute multiPartFileName may be used to specify a custom file name when sending the file.
Success Status Codes
When data is transferred to an HTTP destination, the HTTP response status code is evaluated. By default, status code "2xx" is considered as success status code (e.g. any code between 200-299 inclusive).
To override the default behavior, you can configure a custom list of success status codes via <SuccessStatusCodes> configuration element. The element text must contain a comma separated list of codes.
Below is an example where "200 OK", "201 Created" and "202 Accepted" are considered as success status codes.
<Http id="my-http-dest">
<SuccessStatusCodes>200, 201, 202</SuccessStatusCodes>
</Http>Custom Status Evaluator
You may implement a custom Java class that can evaluate the HTTP response. The class must implement the interface com.technia.tif.enovia.job.destination.HttpStatusEvaluator.
The interface is defined as below:
package com.technia.tif.enovia.job.destination;
import com.technia.tif.core.annotation.API;
import com.technia.tif.core.io.http.HttpResponse;
import com.technia.tif.enovia.job.EnoviaJob;
@API
public interface HttpStatusEvaluator {
/**
* Evaluates the HTTP response.
*
* @param job Job object
* @param response HTTP response.
* @return Whether the status evaluates to true or false.
*/
boolean evaluate(EnoviaJob job, HttpResponse response);
}An example configuration:
<Http id="my-http-dest">
<StatusEvaluator className="com.acme.tif.MyStatusEvaluator" />
</Http>URL Provider
Sometimes it is not possible to configure the URL for HTTP destination in a static way, but it requires some input from the job being executed. To enable this, you may implement a custom Java class that can provide the URL.
The class must implement the interface com.technia.tif.enovia.job.destination.URLProvider.
The interface is defined as below:
package com.technia.tif.enovia.job.destination;
import com.technia.tif.core.annotation.API;
import com.technia.tif.enovia.job.EnoviaJob;
@API
public interface URLProvider {
/**
* Provides URL. The implementation is responsible for possible URL
* encoding.
*
* @param job Job object
* @param destUrl URL configured in destination config
* @return URL
*/
String provide(EnoviaJob job, String destUrl);
}An example configuration:
<Http id="my-http-dest">
<UrlProvider className="com.acme.tif.urlprovider.MyUrlProvider" />
</Http>Custom Destination
The subchapter below describes the configuration aspects for a custom destination.
Transfer Properties
When tranferring data to a custom destination, it might be useful to store information related to the transfer and view it in Admin UI afterwards.
This is possible by annotating field(s) containing the information with the annotation com.technia.tif.core.transfer.TransferProperty.
|
The overall size of the information to be stored in TIF database is limited to 128k. |
For example:
import com.technia.tif.core.transfer.TransferProperty;
import com.technia.tif.enovia.job.TransferHandler;
public class MyDestination extends TransferHandler {
@TransferProperty
private int SomeField = 12345;
@TransferProperty
private String OtherField = "Hello World";
...
}In addition, you may also return an object containing transfer properties by overriding the method getTransferProperties() in the class that implements the custom destination.
The returned object is also available in the method transfer() via argument TransferHandlerContext.
For example:
import com.technia.tif.enovia.job.EnoviaJob;
import com.technia.tif.enovia.job.TransferHandler;
import com.technia.tif.enovia.job.TransferHandlerContext;
public class MyDestination extends TransferHandler {
@Override
public Object getTransferProperties(EnoviaJob job) {
return new MyProperties();
}
}and
import com.technia.tif.enovia.job.EnoviaJob;
import com.technia.tif.enovia.job.TransferHandler;
public class MyProperties {
@TransferProperty
final boolean AnotherField = true;
}Retryable Destination
The destinations that supports being retryable if the transfer fails are listed in the table above. Such destination can be configured like shown below:
<Job>
<TransferData>
...
<Destinations>
<JMS ...>
<RetryAttempts>20</RetryAttempts>
<RetryDelays>1000,5000,10000</RetryDelays>The <RetryAttempts> element defines how many times TIF will try to resend the payload to the destination.
The time to wait between two attempts is defined within the <RetryDelays> element. This value contains comma separated integer values where each value defines a period in milliseconds.
In the example above, TIF will wait 1 second between the 1:st and 2:nd attempt; 5 seconds between the 2:nd and 3:rd attempt and 10 seconds between the 3:rd and all attempts up to the 20:th. If the destination fails after the max count has been exceeded, the job will be marked as failed.
The default values are:
Retry Attempts: 10
Retry Delays: 1000,5000,10000,20000,40000,60000
7.1.3. Transaction Type
During the execution of the integration job of type "transfer data", TIF will by default start a READ transaction inside the ENOVIA/3DExperience database.
If you for some reason want to change this, you can do so like the example below illustrates.
<Job>
<TransferData>
<!-- used for read transaction (default) -->
<TransactionType>read</TransactionType>(1)
<!-- To start an update transaction -->
<TransactionType>update</TransactionType>(2)
<!-- To not start a transaction at all, use the value of none or inactive -->
<TransactionType>none</TransactionType>(3)
</TransferData>
</Job>| 1 | Starts a read transaction |
| 2 | Starts an update transaction |
| 3 | Does not start a transaction |
7.2. Launch External Process
This kind of integration job is used for launching one or more external processes(es), with input that could consist of files that are checked-out from the ENOVIA/3DExperience database and/or just meta data created via a payload configuration.
The output from the external processing can either be checked back into the ENOVIA/3DExperience, for example if you perform conversion of files, or you can collect the output and send it to a destination, such as FTP or Webservice etc.
Before digging into the details of the configuration format for such a job, we will start by showing an example of how such a configuration can look alike.
The example below illustrates how to utilize the external process to convert files inside ENOVIA/3DExperience into different formats. For readability, only one conversion is included. It is however possible to run several executions to create multiple different output variants.
<Job>
<ExternalProcess>
<Prepare>
<MkDir dir="input" id="in" />
<MkDir dir="output" id="out" />
<Checkout format="generic" file="*.png,*.jpg,*.gif" into="${path:in}/${filename}" id="src-file" />
</Prepare>
<Exec forEachFileRef="src-file">
<Executable>/usr/bin/magick</Executable>
<Arguments>
<Arg>${path:src-file}</Arg>
<Arg>-resize</Arg>
<Arg>120x120</Arg>
<Arg>${path:out}${separator}${filename:src-file}</Arg>
</Arguments>
<PostActions>
<Checkin
src="${path:out}${separator}${filename:src-file}"
format="Thumbnail"
fileName="${filename:src-file}"
overwrite="true" />
</PostActions>
</Exec>
</ExternalProcess>
<Events>
<Error>
<SendMail>
<TO>...</TO>
<CC>...</CC>
<Subject>...</Subject>
<Message>
message...
${STACK_TRACE}
</Message>
</SendMail>
</Error>
</Events>
</Job>Another example illustrating how to generate some output that later is transferred to another system is shown below:
<Job>
<ExternalProcess>
<Prepare>
<SetParam name="currentState" select="current" />
<SetParam name="someAttribute" select="attribute[Some Attribute]" />
<ExtractPayload id="payload" config="MyPayloadConfig.xml" into="data.xml" />
<Checkout id="src-file" format="generic" fileName="*.abc" into="${filename}" />
</Prepare>
<Exec>
<Executable>/usr/bin/app</Executable>
<Arguments>
<Arg>${path:payload}</Arg>
<Arg>${currentState}</Arg>
<Arg>${someAttribute}</Arg>
</Arguments>
</Exec>
<Output stdout="true" stderr="true">
<Match dir="/" name="*.*" />
</Output>
<Destinations>
<File id="..." />
</Destinations>
</ExternalProcess>
</Job>Many configuration aspects are the same as for transfer data.
The main difference is the <ExternalProcess> element, which is described in the next chapter.
7.2.1. Configuration Details
The <ExternalProcess> element allows the following content
<Prepare>-
Defines any preparations required. For example checkout files from ENOVIA/3DExperience, extract some payload data, set some parameters or create directories.
<Exec>-
Describes what external process to execute, and what argument to pass. You can define multiple
<Exec>elements if you need to invoke different processes or invoke with different arguments. <Output>-
Optional element used to describe what output to collect from the external process. This is often used together with
<Destinations>. <Destinations>-
Defines destinations. Please read more here.
Each of these elements are defined in more detail in the next chapters.
7.2.2. Prepare
Preparing the external process execution is normally required. You may for example do any of the below:
- Create directory or directories
-
Whenever you launch an external process, a dedicated working directory is created and the process is launched with that directory as working dir. You can create additional subdirectories here-in. That is accomplished by the
<MkDir>element. - Checkout of files
-
You may checkout one or more files from the object, which you launch the job for. That is done via the
<Checkout>element. - Creation of Payload data
-
You can also create meta data content using a payload definition. This is accomplished via the
<ExtractPayload>element. - Set parameters
-
You can also set additional job-parameters that are available during the job execution. This is accomplished via the
<SetParam>element.
|
For each of the prepare actions, you need to specify an id, which later is used when referencing the file or directory. The id is used in many macros, to resolve its path, absolute path, name or extension. Example:
|
| Element | Attributes | Description | ||
|---|---|---|---|---|
|
|
Creates a directory within the working dir. The dir attribute specifies the name of the directory. |
||
|
|
Checks out one or more files from ENOVIA.
The The |
||
|
|
Extracts the payload for the current object using the specified configuration and store the result in the specified file. |
||
|
|
Can be used to set job parameters resolved from the current object, which the job is executed around. In some cases when you only need one or a few attributes from the source object available, then it is easier to resolve these via the SetParam instead of using the ExtractPayload. The latter should be used when you have more data to be extracted. |
7.2.3. Exec
The <Exec> element defines what to execute and what arguments to supply to the external process.
This element supports the following attributes:
| Attribute | Description |
|---|---|
forEachFileRef |
Defines an optional ID that refers to a file or files, which is provided by a prepare action. If the file reference ID refers to a collection of files, the executable will be executed for each of them. |
processTimeout |
Defines a timeout in milliseconds, which if exceeded will cause the external process to be stopped. Note that by default, no limit is specified. |
And the supported child elements are
| Element | Attributes | Description |
|---|---|---|
|
- |
Defines the executable to be invoked. Example: |
|
|
Defines additional environment variables to be set while during the process execution. |
|
- |
Defines the arguments to pass to the external process (see below). |
|
- |
Defines optional post actions to be performed. Currently, only Checkin is a supported post operation. |
The <Arguments> element allows nested <Arg> elements.
Each occurrence of such child element will result in an argument to be passed at the same position.
The <Arg> element may contain macros, which can be used to resolve against the file-ids from the preparation tasks OR against job parameters.
See: this document for more info around job macros.
|
To reference file/directory information created by the preparation actions, see the table below for information:
| Example | Description |
|---|---|
|
Resolves the path relative from the working dir to the file with the specified ID. |
|
Resolves the absolute path to the file with the specified ID |
|
Returns the file name of the file with the specified ID |
|
Returns the file name excluding its suffix of the file with the specified ID |
|
Returns the suffix of the file with the specified ID |
Other supported macros:
| Example | Description |
|---|---|
|
The path separator for the current platform |
|
The separator for the current platform |
|
The ID of the current business object |
|
The workdir for the current execution (the absolute path) |
The currently supported post actions defined below <PostActions> are shown below:
| Element | Attributes | Description |
|---|---|---|
|
|
Checks in the source file into ENOVIA. |
7.2.4. Output
The <Output> element is used when you want to collect the output from your external process.
The output will typically be a ZIP file unless you only want to collect the standard output OR standard error from the external process.
| To get standard output or standard error as output without being zipped, set either attribute "stdout" OR "stderr" true, not both. Do not include any Match child elements. |
This element supports the following attributes:
| Attribute | Description |
|---|---|
stdout |
Defines if to include standard output. Default is false. |
stderr |
Defines if to include standard error. Default is false. |
returnFirstMatch |
An option that allows by-passing the creation of a ZIP file and just return the first found file according to the match instructions.
Note that setting this to TRUE also requires at least one nested |
And the supported child elements are
| Element | Attributes | Description |
|---|---|---|
|
|
Defines what content to include in the generated ZIP file. |
The <Match> element will define what files to be included in the generated ZIP file.
Use wildcards on the name attribute to match more than one file.
Configuration example:
<Output stdout="true">
<Match dir="${path:out-dir}" name="*.png" />
<Match dir="${path:out-dir}" name="*.gif" />
</Output>7.3. Defining a Custom Job
You may in some cases need to create a job having customized logic. This is done by defining the class implementing the custom job logic inside the Executor tag as shown below.
<Job>
<Executor>com.acme.integration.executor.MyJobExecutor</Executor>
</Job>The class must implement the interface com.technia.tif.enovia.job.JobExecutor.
This interface is defined like below.
package com.technia.tif.enovia.job;
import com.technia.tif.core.ConfigurationException;
import com.technia.tif.core.ExtractionException;
import com.technia.tif.core.ValidationException;
import com.technia.tif.core.annotation.API;
/**
*
* @author Technia
* @since 31 okt 2012
*/
@API
public interface JobExecutor {
/**
* Executes the job using the provided data as input for the execution
*
* @param job The job to be executed
* @throws ConfigurationException May be thrown to indicate error in the
* configuration
* @throws ExtractionException May be thrown to indicate error while
* extracting data
* @throws ValidationException May be thrown to indicate error when
* validating the data being used/sent.
*/
void perform(EnoviaJob job) throws ExtractionException,
ConfigurationException,
ValidationException;
}Custom jobs support job events for handling errors etc. Read more in the Job Events chapter.
7.3.1. Transaction Type
By default, TIF does NOT start a transaction inside the ENOVIA/3DExperience database for the custom executor.
To change it, you can do so like the example below illustrates.
<Job>
<Executor className="com.acme.MyExecutor">
<TransferData>
<!-- used for read transaction -->
<TransactionType>read</TransactionType>(1)
<!-- To start an update transaction -->
<TransactionType>update</TransactionType>(2)
<!-- To not start a transaction at all, use the value of none or inactive (default) -->
<TransactionType>none</TransactionType>(3)
</TransferData>
</Executor>
...
</Job>| 1 | Starts a read transaction |
| 2 | Starts an update transaction |
| 3 | Does not start a transaction |
7.3.2. Store Payload
It is possible to store outbound payload that is visible in Admin UI. Use com.technia.tif.enovia.job.log.Logger.
For example:
import com.technia.tif.enovia.job.EnoviaJob;
import com.technia.tif.enovia.job.JobExecutor;
import com.technia.tif.enovia.job.log.Logger;
import com.technia.tif.enovia.payload.PayloadUtils;
public class MyJobExecutor implements JobExecutor {
@Override
public void perform(EnoviaJob job) {
Logger.storeOutboundPayload(job, new PayloadDataBuffer().append("Hello World!"));
}
}7.3.3. Access Input Payload
Input payload provided by parent job can be accessed using com.technia.tif.enovia.payload.PayloadUtils utility class.
Example code:
package com.acme.tif.executor;
import com.technia.tif.core.ExtractionException;
import com.technia.tif.enovia.job.EnoviaJob;
import com.technia.tif.enovia.job.JobExecutor;
import com.technia.tif.enovia.payload.PayloadData;
import com.technia.tif.enovia.payload.PayloadUtils;
import java.io.IOException;
import java.io.InputStream;
import org.apache.commons.io.IOUtils;
public class MyJobExecutor implements JobExecutor {
@Override
public void perform(EnoviaJob job) throws ExtractionException {
PayloadData data = PayloadUtils.getInputPayload(job);
try (InputStream in = data.getInputStream()) {
// TODO: Do something with the input stream, e.g:
String string = IOUtils.toString(in, data.getEncoding());
} catch (IOException e) {
throw new ExtractionException(e);
}
}
}7.4. File Package Creation
If you have a license to the "TVC File Manager" component, you are maybe familiar with the feature called File Package Download.
This feature lets you configure the creation of a ZIP package containing files checked-in to objects in ENOVIA/3DExperience, files containing meta-data from ENOVIA/3DExperience and/or other files.
The File Package configuration format is described in the "TVC File Manager" documentation.
The File Package job works in the same way as the <TransferData> job, the only
difference is that you for the <FilePackage> element need to define the file package
creation rules.
7.4.1. JAR + License
Note that the File Package feature requires both a valid "TVC File Manager" license and that TIF are using the "tvc-filemanager-nnn.jar" file.
The latter can be fulfilled by one of the below two ways:
-
You configure the TIF start-script to include the ENOVIA/3DExperience webapplication
-
And this webapplication contains the JAR file under the WEB-INF/lib directory
-
-
You manually copy the "tvc-filemanager-nnn.jar" file to the
$TIF_ROOT/modules/enovia/lib/customfolder
7.4.2. Create Package Using a FPD Configuration
One way to create a file package is to point out a File Package configuration. The format of such configuration is defined in the TVC File Manager documentation.
Below is an example how to accomplish this:
<Job>
<Name>PDX Creation</Name>
<FilePackage>
<Config>tvc:fpd:tvx:enc/PDX.xml</Config> (1)
<Destinations>
<File id="file-dest-3"/>
</Destinations>
</FilePackage>
</Job>| 1 | Point out the FPD configuration |
The <FilePackage> element supports one attribute called transferZIP.
This attribute accepts a boolean value and if set to false, each file in the package will be transferred individually.
|
7.4.3. Create Package with TIF handler
A special TIF handler is provided as a part of the product. This handler can be used to specify what data to be included such as files and payload content into the generated package.
An example is shown below:
<Job>
<Name>PDX Creation</Name>
<FilePackage>
<Content>
<Files dataSet="tvc:dataset/PartSpecifications.xml"
saveIn="specifications/${id}/${format}">
<FileFilter>
<Exclude>
<Name>*.exe</Name>
<Name>*.sh</Name>
<Name>*.abc</Name>
<Format>format_JT</Format>
<Format>format_Secret</Format>
</Exclude>
</FileFilter>
</Files>
<Files dataSet="tvc:dataset/RefDocs.xml"
saveIn="refdocs/${id}/${format}">
<FileFilter>
<Include>
<Name>*.docx</Name>
<Name>*.xlsx</Name>
<Name>*.doc</Name>
<Name>*.xls</Name>
<Name>*.pdf</Name>
</Include>
</FileFilter>
</Files>
<Payload config="tvc:payload/BOM.xml" saveIn="data" saveAs="bom.xml" />
<Payload config="tvc:payload/Specs.xml" saveIn="data" saveAs="specs.xml" />
<Payload config="tvc:payload/RefDocs.xml" saveIn="data" saveAs="ref-docs.xml" />
</Content>
<Destinations>
<File id="file-dest-3"/>
</Destinations>
</FilePackage>
</Job>Within the <Content> element you may declare elements of type <Files> and <Payload>,
which will define the files to be added to the package including what payload/meta-data
to be included.
For the Files element you need to point out a data-set, which should return business objects that contains files. Each of the files found from these objects will be added, unless any exclusion/inclusion rules denies so, to the package.
Inclusion/Exclusion can be specified with either a file-name pattern or based upon format.
The <FileFilter> can be shortened, and be written like these examples:
<FileFilter includeFormats="a,b,c" /> <FileFilter excludeFileNames="*.exe,*.dll" /> <FileFilter excludeFormats="a,b,c" /> <FileFilter includeFileNames="*.exe,*.dll" />
Note that the files found should be saved in a way, which prevents them from overwriting each other.
Typically you need to use object-id and format as a part of the folder name. The default saveIn value
unless specified is files/${id}/${format}.
For Payload data inclusion, you need to specify the payload configuration as minimum.
Optionally, you can specify the folder to save the data in with the saveIn attribute.
The saveAs attribute specifies the file name of the payload data. By default, the
file name is constructed using this file name format payload_%03d.xml. The format
will get the payload sequence number as input. E.g the %03d will then be converted
to "000" for the first payload.
7.4.4. Create Package Programmatically
A simpler configuration allows pointing out a so called File Package Download handler directly, without having to specify a FPD config that in turn points out the handler.
See below for an example:
<Job>
<Name>PDX Creation</Name>
<FilePackage>
<Handler className="com.acme.fpd.MyFPDHandler" /> (1)
<Destinations>
<File id="file-dest-3"/>
</Destinations>
</FilePackage>
</Job>| 1 | Define the class name inline |
7.5. Synchronous Integration
From a performance perspective one should avoid using synchronous integrations, since that may block the user from working with the ENOVIA/3DExperience system in a smooth way. However, in some situations it is necessary to run a job synchronously.
|
Remember that TIF is running in a different process than your ENOVIA/3DExperience app. If you have started a transaction and within that transaction performs a synchronous call to TIF, you need to extract the data you need (the payload) on the TIF server before you do the TIF call. Otherwise, you may due to transaction isolation not be able to read the correct data OR you may in worst case cause a deadlock. |
|
On the caller side, you typically use the method |
7.5.1. Configuration
In order for the client to know where the TIF server is located, you need to set some environment variables.
- TIF Server URL
-
The URL to the TIF server is resolved in the following order:
-
Java system parameter:
System.getProperty("tif.server.url") -
TVC Init parameter:
tif.server.url(set in web.xml or /WEB-INF/classes/tvc.properties). -
ENOVIA/3DExperience RPE Parameter:
TIF_SERVER_URL -
ENOVIA/3DExperience Ini Parameter:
TIF_SERVER_URL -
Environment Variable:
TIF_SERVER_URL
-
- Context Path
-
The default is /enovia/tif-internal. Unless you have changed this via the module settings file, you do not need to set this. Otherwise, this value is resolved in the same order as above:
-
Java system parameter:
System.getProperty("tif.server.contextPath") -
TVC Init parameter:
tif.server.contextPath(set in web.xml or /WEB-INF/classes/tvc.properties). -
ENOVIA/3DExperience RPE Parameter:
TIF_SERVER_CONTEXTPATH -
ENOVIA/3DExperience Ini Parameter:
TIF_SERVER_CONTEXTPATH -
Environment Variable:
TIF_SERVER_CONTEXTPATH
-
7.5.2. Programatically Invoke
You can embed the invocation of a synchronous job in your own code by using the TIF classes like shown below:
...
import com.technia.tif.enovia.api.synch.InvokeJobResponse;
import com.technia.tif.enovia.client.synch.SynchCreateNewJob;
...
Map<String, String[]> paramMap = ...
SynchCreateNewJob req = new SynchCreateNewJob();
req.setJobCfg(jobCfg);
req.setParamMap(paramMap);
//req.setPayload(aString);
InvokeJobResponse response;
try {
response = req.run();
} catch (XMLException | IOException e) {
throw new AppException("Unable to run integration", e);
}
if (response.getHasError()) {
throw new AppException(response.getErrorMessage());
}
String firstResult = response.getFirstResult().getResponse();
...7.5.3. Built-in TVC Form Processor
If you use the TVC Structure Browser component within your ENOVIA/3DExperience web application, you can use a built-in processor for name-allocation from an external system.
Please look into this tutorial for additional information and usage.
8. Inbound Integration Jobs
Inbound integration jobs in TIF are based upon some external event resulting in some kind of job taking place at the TIF server.
Such job typically performs some update to the ENOVIA/3DExperience database, for example creates or updates business objects and/or connections between business objects. It may however also be a job that only fetches data from ENOVIA/3DExperience, for example some external system requests some data from ENOVIA/3DExperience via a JMS message or a Webservice request.
The use cases varies. The child pages describes the current possibilities to handle this within the TIF server.
8.1. Configurable SOAP Web Services
TIF includes an Apache Axis2 installation in order to support SOAP based web-services.
In addition to the standard distribution of Apache Axis2, TIF provides some extended Axis2 functionality that supports creation and deployment of some different kind of SOAP based web-services solely defined in XML file. E.g. no need to implement the webservice in Java, compile and package it as a AAR file.
The kind of configurable web-services you can use in the current TIF release are:
-
Export of data from business object(s).
-
The configuration format allows specifying criteria used to find the business object(s) to export
-
Also, you configure what data to be exported for these objects.
-
It is also possible to point out a Payload Definition that defines the returned meta-data
-
-
-
Update of business object(s) data
-
The configuration format allows specifying criteria used to find the business object(s) to update
-
Also, you configure what fields / attributes the web-service client may update and some rules for the values.
-
The first service is called "configurable export service" and the second is called "configurable update service".
These are described in more detail in the child pages.
8.1.1. Location of Configurable Web Service’s
A configurable web-service is defined in an XML file that should be put inside the following folder:
${TIF_ROOT}/modules/enovia/cfg/soapservice
By default, TIF has enabled hot-deployment and hot-update of the Axis2 application meaning that you can add new configurable web-services or update existing at runtime of TIF.
8.1.2. From Definition to Implementation
The web-service definition is defined by you and consists of an XML file. When this file is put into the directory "soapservice", the TIF deployer in Axis2 will pick up the file and scan it. The following actions will take place then:
-
Parse and validate definition
-
Generate a WSDL
-
Compile the WSDL into Axis Data Binding classes (ADB)
-
Generate Java code implementing the service classes.
-
Compiles all source code.
-
Packages all compiled artifacts along with necessary resource into a so called AAR file (Axis archive).
-
The AAR file is deployed into Apache Axis2.
-
Service is ready for use
The final AAR files are stored internally under the following folder inside TIF:
${TIF_ROOT}/data/${TIF_INSTANCE_ID}/axis2/services
8.1.3. Common Settings
There are some common settings possible to define on a configurable web service. These are defined as attributes on the root-element in the XML definition.
The attributes are:
| Attribute Name | Description | Required |
|---|---|---|
namespace |
Used to specify the namespace of the schema in the WSDL. |
No |
package |
Unless defined, a default package name for the generated Java classes will be used. Note that if you define your package name, ensure that it is unique and will not collide with existing web-service’s. |
No |
keepSource |
A boolean flag that may be used to keep the generated source files. This might be useful for debugging purposes. |
No |
debug |
If set to true the source code is generated with some debug information. |
No |
serviceDescription |
Gives the service a more human friendly description. Unless specified, the service description will be the same as the service name. |
No |
8.1.4. URL to a Configurable Web Service
The URL to a configurable web service depends on what hostname your TIF server uses, the port TIF will be using (8181 is default), the context path to the jaxws application and finally the name of the XML definition that defines the webservice.
Assuming your configurable webservice is defined in a file called ProductQueryService.xml and the default configurations are used, the URL becomes
http(s)://tif-server:8181/enovia/jaxws/services/ProductQueryServiceTo obtain the WSDL file for this service, just append the ?wsdl at the end of the URL.
Axis2 Installation Details
The Apache Axis2 installation is part of the TIF installation. The place where the Axis2 related files are installed is:
${TIF_ROOT}/modules/enovia/webapps/jaxws|
TIF has made some changes into the Axis2 configuration files. If you do any changes in the Axis2 configuration files, ensure that you don’t remove or destroy the TIF specific additions. |
8.1.5. Configurable Export Service
The configurable export web-service support is used to quickly setup a SOAP based web-service that can be used by a client to export business object meta data.
Each configuration results in one web-service to be exposed. This kind of web service may have one or two operations (or methods) that can be invoked remotely, namely:
-
Extracting data based upon a list of object id’s
-
Extracting data from object(s) based upon query parameters deciding what object’s to be exported
Below is a sample configuration illustrating some concepts.
<ExportServiceDefinition>
<Credentials required="true" />
<ObjectId max="100" />
<Query>
<Params>
<Limit min="1" max="50" />
<Name allowWildCard="true" />
</Params>
<Defaults>
<Limit>25</Limit>
<Type>type_Product</Type>
<Vault>vault_eServiceProduction</Vault>
<Revision>*</Revision>
<Where>current matchlist 'Release,Obsolete' ','</Where>
</Defaults>
</Query>
<Extract payload="tvc:payload/ProductDetails.xml"/>
</ExportServiceDefinition>The root element of this file must be <ExportServiceDefinition>.
The available child elements are listed in the table below.
| Child Element | Description | Example |
|---|---|---|
|
Defines if the client of this web-service must provide a user name / password for an ENOVIA/3DExperience user. If the definition does not contain this element or has the attribute required set to false, the query and data extract will be performed with super-user privileges. |
No but recommended. |
|
Defines if an operation in the web-service called "getDataForObjectId" should be available. This method allows passing in ENOVIA/3DExperience object-id’s to the service in order to extract data. Note that the service will not perform any check of the validity of these object-id’s. For example, a client might pass object-id’s pointing to for example business objects of type Part to a service that normally deals with Products. |
No but either this or the <Query> element must be present. |
|
Defines if an operation in the web-service called "query" should be available. Depending on the content of this element, the query method can accept a wide range of different input. See below for further details. |
No but either this or the <ObjectId> element must be present. |
|
Defines what to be extracted from this web-service. You may point out a payload configuration or define selectables directly in the configuration. |
Yes |
|
Defines a custom Java class OR a custom Script file that can be used to perform additional validations. |
No |
Credentials
If this element is omitted or if the attribute required is set to false then the operations or methods of this web service will be executed with admin privileges.
Example:
<ExportServiceDefinition>
<Credentials required="true"/>If credentials is required, the user calling the web-service operation is required to enter a valid ENOVIA/3DExperience user id / password combination.
It is also possible to use container managed authentication (basic authentication). See [Container Managed Credentials] for more information.
ObjectId
If the <ObjectId> element is present, this will result in that an operation called getDataForObjectId() is available on the web service.
This element may have one attribute defined called "max". This attribute may be used to limit the number of object-id’s that are allowed to pass in to the operation.
The default value is "-1", meaning that there is no upper limit.
Example:
<ExportServiceDefinition>
...
<ObjectId max="-1"/Query
If the <Query> element is present, this will result in that an operation called "query" is available on the web service.
The query method will accept some input arguments, which are defined by the definition. Lets take a closer look what child elements you may have for the <Query> element:
| Child Element | Description | Required |
|---|---|---|
|
Defines what parameters the client may pass in. See below for details. |
No, but probably always used. |
|
Defines some default settings for the query, such as default where expression or default type pattern etc. |
No, but for security reasons recommended as you may not want the client to be able to search upon any data inside the ENOVIA/3DExperience database. |
These child elements are described below.
Params
The <Params> element defines what input arguments the client may pass in.
The possible child elements are shown in the table below:
| Child Element | Description | Attributes | Required | Example |
|---|---|---|---|---|
|
Used to allow the client to define a query limit. You may also say what the min and max value for the limit can be. |
min max value |
No |
|
|
If present, allows the client to define a type pattern for the query. The attribute "wildcardAllowed" may be used to specify if characters such as * and/or ? may be used in the pattern. The attribute "name" may be used to give this parameter a different name. |
wildcardAllowed name |
No |
|
|
Same as |
See above |
No |
|
|
Same as |
See above |
No |
|
|
Same as |
See above |
No |
|
|
Same as |
See above |
No |
|
|
Defines an argument that affects the where clause of the query. The Arg element has a child element called The name attribute is used to provide this argument a valid name. The required attribute specifies if the client must provide this value or not. The type attribute may be one of: string, integer, decimal, boolean The rangeLoader attribute may be used to point out a custom range value provider.
The class must implement the interface: |
name required type rangeLoader |
No |
|
Arg / Where
Within the where clause of the argument, you use the %s (String.format is used for this) to be replaced with the real value. Note that you might use other format options if you are familiar with the Formatter / String.format in Java.
Defaults
The <Defaults> element defines the default search criteria.
The possible child elements are shown in the table below:
| Child Element | Description | Required | Example |
|---|---|---|---|
|
Specifies the default find/query limit |
No |
|
|
Defines a type in the type pattern. Each type in the pattern is defined inside it’s own Type tag. |
No |
|
|
See |
No |
|
|
See |
No |
|
|
See |
No |
|
|
See |
No |
|
|
Defines the default part of the where clause. Note: This where expression will be added first to the where clause, before any custom arguments. |
No |
|
Extract
The <Extract> element defines what data to be extracted for the objects found via the query (or the objects provided by the getDataForObjectId() operation).
You have two different options to perform the extract, either point out a payload definition that specifies what data to be extracted, or define it in this configuration.
For the first alternative, e.g. using a payload definition, you configure that scenario like shown below:
<ExportServiceDefinition>
<Extract payload="tvc:payload/MyPayload.xml" />or
<Extract payload="MyPayload.xml"/>For the other alternative, the possible child elements are shown in the table below:
| Child Element | Description | Attributes | Required | Example |
|---|---|---|---|---|
|
Defines that the basic data from the business object(s) may be part of the extracted data, if the client wants it. You may define certain basic properties to be excluded by using the The name attribute is default set to "basics". The default attribute is default set to "include". |
name default |
No |
|
|
Defines that the attributes from the business object(s) may be part of the extracted data, if the client wants it. You may define certain attributes to be excluded by using the <Exclude> child element The name attribute is default set to "attributes". The default attribute is default set to "include". |
name default |
No |
|
|
Defines custom extraction arguments. See details below. |
name default dataType select |
No |
|
Arg
The <Arg> element is used to specify custom extract arguments. E.g. one argument may map to one or multiple select expressions. You may also refer to a "table column definition", which defines complex data extraction rules.
The following table shows the available attributes on the <Arg> element.
| Attribute Name | Description | Example |
|---|---|---|
select |
Defines a single select expression |
|
dataType |
Defines the data type of the returned data. One of:
|
|
multiple |
A boolean indicating if the returned data contains one or multiple values. If a select expression starts with "from[", "to[" or "relationship[", this value will by default be set to true. |
|
The possible child elements are shown in the table below:
| Child Element | Description | Required | Example |
|---|---|---|---|
|
Defines a select expression that should be used for extraction of the data |
No |
|
|
Defines a table column that is used for extraction of the data |
No |
|
Handler
The handler element allows pointing out a custom Java class or a custom script for validation/custom handling of the web service. The latter is a convenient way to quickly implement custom validation without having to compile any code.
To define a custom Java class, configure it like shown below:
<ExportServiceDefinition>
<Handler>com.acme.integrations.ws.ProductDataExportHandler</Handler>This class must either implement the interface com.technia.tif.enovia.jaxws.api.export.QueryServiceHandler or extend from the default implementation com.technia.tif.enovia.jaxws.api.export.DefaultQueryServiceHandler.
The default implementation is implemented like shown below:
import java.util.Map;
import com.technia.tif.enovia.jaxws.api.Value;
import com.technia.tif.enovia.jaxws.api.Webservice;
import com.technia.tvc.core.db.Query;
public class DefaultQueryServiceHandler implements QueryServiceHandler {
public void validateInput(Webservice service, Object input) {
}
public void validateQuery(Webservice service, Query query) {
}
public void handleBasicsMap(Webservice service, Map<String, Value> valueMap) {
}
public void handleAttributesMap(Webservice service, Map<String, Value> valueMap) {
}
public boolean isAuthorized(Webservice service, String userId) {
return true;
}
}If you want to implement the same handler in a script file, for example a Javascript file you can point out such script like shown below (different syntaxes shown).
<ExportServiceDefinition>
<Handler>script:MyHandler.js</Handler>
<Handler>tvc:script/MyHandler.js</Handler>
<Handler>script:tvc:script/MyHandler.js</Handler>
<Handler>tvc:script:acme/MyHandler.js</Handler>The first three variants all refers to the same script file, e.g. ${TIF_ROOT}/modules/enovia/cfg/script/MyHandler.js
The last example refers to the file: ${TIF_ROOT}/modules/enovia/cfg/acme/script/MyHandler.js
You may chose what functions to implement in your script, below is an example:
function validateInput(service, input) {
var qp = input.getQueryParams();
var arg1 = qp.getArg1(), arg2 = qp.getArg2();
if (arg1 == "1" && arg2 == "1") {
throw "Arg1 and Arg2 may not both be set to 1";
}
}
function isAuthorized(service, uid) {
if (uid == "creator") {
return false;
}
return true;
}8.1.6. Configurable Update Service
The configurable update web-service support is used to quickly set up a SOAP based web-service that can be used by a client to update business object metadata in ENOVIA/3DExperience.
Each configuration results in one web-service to be exposed. This kind of web service will have one operation that can be invoked remotely. This method is called "update".
Below is a sample configuration illustrating some concepts.
<UpdateServiceDefinition>
<Credentials required="true" />
<Query>
<Params>
<Arg name="unitOfMeasure" required="true" type="String">
<Where>${attribute[attribute_UnitofMeasure]} == "%s"</Where>
</Arg>
</Params>
<Defaults>
<Limit>100</Limit>
<Type>type_Part</Type>
<Vault>vault_eServiceProduction</Vault>
</Defaults>
</Query>
<Update>
<Field
name="unitOfMeasure"
type="string"
attribute="attribute_UnitofMeasure"/>
<Field
name="test"
type="string"
required="false"
java="com.technia.tif.enovia.jaxws.api.update.TestUpdater"/>
</Update>
<ReturnFormat>
<OnSucess>
<Status>OK:${COUNT}</Status>
</OnSucess>
<OnError>
<Status>FAILED</Status>
<Message>${ERROR}</Message>
</OnError>
</ReturnFormat>
</UpdateServiceDefinition>The root element of this file must be <UpdateServiceDefinition>.
The available child elements are listed in the table below.
| Child Element | Description | Required |
|---|---|---|
|
Defines if the client of this web-service must provide a user name / password for an ENOVIA/3DExperience user. If the definition does not contain this element or has the attribute |
No but recommended |
|
Defines the query parameters, e.g. the query that returns the objects which is subject for being updated. |
Yes |
|
Defines what to be updated, e.g. what input the client must provide and what this input maps to. |
Yes |
|
Defines the response/return value from the service. You may configure the success message and error message / status. |
No |
|
Defines a custom Java class OR a custom Script file that can be used to perform additional validations. |
No |
Credentials
If this element is omitted or if the attribute required is set to false then the operations or methods of this web service will be executed with admin privileges.
Example:
<UpdateServiceDefinition>
<Credentials required="true"/>
...If credentials is required, the user calling the web-service operation is required to enter a valid ENOVIA/3DExperience user id / password combination.
It is also possible to use container managed authentication (basic authentication). See [Container Managed Credentials] for more information.
Query
The details of the <Query> element is described within the Configurable Export Service chapter.
Update
The <Update> element defines what to be updated.
The following table shows the possible child elements of this element.
| Child Element | Description | Required | Example |
|---|---|---|---|
<Field> |
Defines the "fields" that contains the update settings |
At least one present |
|
Field
The <Field> element has a number of attributes used to control the behavior of the field. The following table shows the available attributes on the <Field> element.
| Attribute Name | Description | Example | Required |
|---|---|---|---|
name |
Defines the name of the field. Note that the name must only contain the characters a-z and or A-Z or digits. The first character must be a letter. |
|
Yes |
type |
Defines the data-type for the value sent by the client. The possible values are:
|
|
No, defaults to String |
attribute |
Specifies an attribute, which the field maps to. |
|
- |
basic |
Specifies a basic property, which the field maps to. |
|
- |
java |
Specifies a Java class, which the field maps to. See below for details |
|
- |
script |
Specifies a Script file, which the field maps to. See below for details |
|
- |
| Exactly one of the attributes "attribute", "basic", "java" and "script" must be set. |
The Java attribute, if used, must contain the fully qualified classname of a class implementing the interface com.technia.tif.enovia.jaxws.api.update.Updater.
This interface is defined as below:
package com.technia.tif.enovia.jaxws.api.update;
import com.technia.tif.enovia.jaxws.api.Webservice;
/**
* The updater interface used by the configurable update webservice.
* @author Technia
*/
public interface Updater {
/**
* Performs the update of the field.
*
* @param service The service, which is calling this updater.
* @param objectId The id of the object to update
* @param field The field name to be updated
* @param value The value sent by the client.
* @throws Exception If unable to perform the update operation, for some reason.
*/
void update(Webservice service, String objectId, String field, Object value) throws Exception;
}Using the script attribute lets you define the update logic inside a script file instead. Below is an example of such:
importClass(com.technia.tvc.core.db.BusinessObjectUtils);
function update(service, objectId, field, value) {
var type = BusinessObjectUtils.select(objectId, "type.kindof");
if (type == "Part") {
if (value < "1") {
throw "Invalid value: " + value;
}
BusinessObjectUtils.setAttribute(objectId, "Target Cost", value);
}
}ReturnFormat
The <ReturnFormat> element allows defining how the response should look alike when the web-service has been invoked.
You can control the success status and the error status and message. See below for syntax:
<UpdateServiceDefinition>
<ReturnFormat>
<OnSucess>
<Status>OK:${COUNT}</Status>
</OnSucess>
<OnError>
<Status>FAILED</Status>
<Message>${ERROR}</Message>
</OnError>
</ReturnFormat>
</UpdateServiceDefinition>The ${COUNT} macro refers to the number of objects being updated.
The ${ERROR} macro may be used in the <OnError> section to include the error message.
Handler
The <Handler> element is described in the Configurable Export Service chapter.
8.1.7. Credentials
The <Credentials> element contains the following attributes:
- containerManaged
-
A boolean value. Specifies if authentication is carried out via the servlet container. See chapter below how to configure this.
- runAs
-
A string value. Defines the name of the ENOVIA/3DExperience user that we will run the service as.
- runAsSuperUser
-
A boolean value. Useful together when
containerManaged=trueand you want to run the service as a super-user, while authentication is required. - handler
-
The fqn name of a class that implements the interface
com.technia.tif.enovia.security.ContextProviderHandler. See further down in this document for more details.
Valid child elements are defined in the table below
| Element | Description | Mandatory |
|---|---|---|
|
Used for defining the ENOVIA/3DExperience security context. See below how to configure this. |
No |
|
In case container managed authentication is enabled, you may define additional roles, which the authenticated user must have in order to gain access. These roles are typically not ENOVIA/3DExperience roles, in case of Kerberos authentication these will be roles from your Active Directory. Note that if you specify multiple roles, the user is only required to have one of the listed roles in order to get access. Example below: |
No. |
|
Specify additional ENOVIA/3DExperience assignments the user must have in order to proceed. Example below: |
No |
Custom Context Provider Handler
In some cases you may need some more fine-tuned control over what ENOVIA/3DExperience Context to be used.
The handler attribute is used to point out the class implementing the interface com.technia.tif.enovia.security.ContextProviderHandler.
| If you have enabled container managed authentication, the servlet container (the Jetty engine) have already done some authentication. In case you are using "enovia" as the login-service you will in that case has a "Context" set already. This Context Provider Handler cannot override/by-pass the container managed logic - if this is needed then you should disable the container managed security and take care about this in your custom ContextProviderHandler. |
public class MyContextProviderHandler implements ContextProviderHandler {
@Override
public ContextProvider apply(AuthorizationContext ctx, CredentialsConfig config) {
// Principal available in case container-managed-security is enabled. Otherwise, null.
Principal p = ctx.getPrincipal();
// EXAMPLE: Use the ENOVIA user credentials directly.
if (principal instanceof EnoviaUserPrincipal) {
EnoviaUserPrincipal eup = (EnoviaUserPrincipal) principal;
if (eup.isValid()) {
return eup;
}
}
// EXAMPLE: Get headers
List<String> headerNames = ctx.getHeaderNames();
for (String header : headerNames) {
System.out.printf("Header>>> %30s : %s%n", header, ctx.getHeaderValues(header));
}
// EXAMPLE: Get parameters
List<String> paramNames = ctx.getParameterNames();
for (String param : paramNames) {
System.out.printf("Parameter>>> %30s : %s%n", param,
StringUtils.concat(ctx.getParameterValues(param), "|"));
}
// EXAMPLE: Get other request based properties
if (ctx instanceof RequestBasedAuthorizationContext) {
RequestBasedAuthorizationContext rctx = (RequestBasedAuthorizationContext) ctx;
System.out.printf("Request URI>> %s%n", rctx.getHttpServletRequest().getRequestURI());
}
// EXAMPLE: Run as specific user
String runAs = ctx.getHeaderValue("x-run-as");
return ContextProviders.getRunAs(runAs);
}
}| In the above example we are not considering if the Credentials have been configured with Security Context nor Authorization rules. If you want to do this you can see below how to do so. |
import com.technia.tif.enovia.security.DefaultContextProviderHandler;
...
ContextProvider contextProvider = ...;
return DfaultContextProviderHandler.getInstance().apply(ctx, credentials, contextProvider);Security Context
Via the <SecurityContext> element you define what security context to use.
You may do the following.
-
Point out a mapping file
-
Or use a default mapping file
-
-
Specify a named security context
-
Or use the "default" security context as configured for the ENOVIA/3DExperience user
To point out a mapFile use the syntax below.
The file is relative to ${TIF_ROOT}/modules/enovia/etc
|
<SecurityContext mapFile="sec-mapping.xml" />Use the default mapping file.
The default file is specified via the property securityMapping.defaultFile, and the default value is security-context-mapping.xml.
The file is relative to ${TIF_ROOT}/modules/enovia/etc
|
<SecurityContext useDefaultMapFile="true" />The format of the mapping file is shown below:
<Contexts>
<Context name="Design Engineer.Company Name.GLOBAL">
<User is="user1" />(1)
<User is="user2" />
<User is="user3" />
<Role is="engineer" /> (2)
<Role is="designer" />
<Parameter name="test" is="something" /> (3)
<Parameter name="x" is="y" />
</Context>
<Context name="...">...</Context>
<Context name="...">...</Context>
</Contexts>NOTE that specifying user and role requires having enabled container managed authentication (Kerberos or Basic Authenticaton etc.)
| 1 | Specifies certain users to match against |
| 2 | Specifies additional roles the user should have |
| 3 | Specifies additional parameters and value to be evaluated In case of a REST service, the parameters are the request parameters passed to the service. |
The evaluation logic is:
-
User list is EMPTY or user is in list
-
Role list is EMPTY or user have one of the roles in the list
-
Parameter list is EMPTY or one of the parameters have the expected value
If A AND B AND C is satisfied, then use the security context defined for this "rule".
To use a specific Security Context:
<SecurityContext use="Design Engineer.Company Name.GLOBAL" />Specify using the default security context.
<SecurityContext useDefault="true" />Container Managed Security
You can enable security on the servlet container level and either use Kerberos/SPNego authentication OR use Basic authentication and authenticate against the ENOVIA/3DExperience database.
Configure Security Realm
Within the ${TIF_ROOT}/modules/enovia/etc/module.custom.properties, you need
to specify what login service to be used including its realm and optionally some
extra parameters.
The login services currently supported are
- enovia
-
A login service that will authenticate the remote user against the ENOVIA/3DExperience database.
- ldap
-
A login service that will authenticate the remote user against a LDAP directory (for example Active Directory)
- spnego
-
A login service supporting Single Sign On against Active Directory.
| In order to use Spnego authentication, also read this document in order to setup the core parts of Spnego/Kerberos. |
LDAP Authentication
If the "loginService" is set to "ldap", TIF will authenticate users against a LDAP directory.
http.webapp.jaxws.loginService=ldap
http.webapp.jaxws.realm=WebservicesThe second value defines the "realm". (See https://www.ietf.org/rfc/rfc2617.txt for more information about realms and basic authentication).
There are some additional LDAP settings required to be defined. You can specify global LDAP parameters and/or web application specific LDAP parameters. In most cases you will be fine with only global LDAP settings.
For convenience, the application specific parameters will be merged with the global LDAP parameters. Hence you only need to override/define the parameters that is different on the application level.
Please see the table below.
The global parameter name is ldap., while the application specific parameter
are named like http.webapp.<APP_NAME>.ldap.
|
| Parameter | Description | Required |
|---|---|---|
ldap.server |
Defines the server or list of LDAP servers. Separate with space if using multiple. |
Yes |
ldap.rootDN |
Defines the root dn, where all LDAP searches starts from. If we can start a search starting at a sub-node (as opposed to root), you get a better performance because it narrows down the scope of a search. This field specifies the DN of such a subtree. |
No |
ldap.userSearchBase |
The relative DN (From the root DN) that further narrow down searches to the sub-tree. If you do specify this value, the field normally looks something like "ou=people". |
No |
ldap.userSearchFilter |
This field determines the query to be run to identify the user record. The query is almost always "uid={0}" as per defined in RFC 2798, so in most cases you should leave this field empty and let this default kick in. If your LDAP server doesn’t have uid or doesn’t use a meaningful uid value, try "mail={0}", which lets people login by their e-mail address. If you do specify a different query, specify an LDAP query string with marker token "{0}", which is to be replaced by the user name string entered by the user. |
Yes |
ldap.groupMembershipAttribute |
If the user entry in the LDAP tree contains an attribute with the group membership, then specify that attribute here. Otherwise we need to query for the groups a user belongs to. |
Either this or the groupSearchBase / groupSearchFilter needs to be defined. |
ldap.groupSearchBase |
This field determines the query to be run to identify the organizational unit that contains groups. The query is almost always "ou=groups" so try that first, though this field may be left blank to search from the root DN. |
Not needed, but if the groupMembershipAttribute is undefined you can use this to make the group query faster. |
ldap.groupSearchFilter |
Defines the search filter for groups. In case we need to search the LDAP tree for group membership this needs to be defined. The marker token "{0}" is replaced with the current user’s DN. Example:
|
Yes unless groupMembershipAttribute is defined. |
ldap.managerDN |
If your LDAP server doesn’t support anonymous binding, then we would have to first authenticate itself against the LDAP server. A DN typically looks like It can be any valid DN as long as LDAP allows this user to query data. |
Probably Yes |
ldap.managerSecret |
The password for the manager DN |
Probably Yes |
ldap.displayNameLDAPAttribute |
The attribute holding the display name. Per default we use the CN of the user entry. |
No |
ldap.emailAddressLDAPAttribute |
The attribute holding the email value. Per default we use the field This field is currently not used so you can leave it blank. |
No |
ldap.pooled |
Whether or not to pool the LDAP connections |
No |
Example setup below for Active Directory.
ldap.server=ldapserver.yourdomain.com:3268
ldap.rootDN=DC=yourdomain,DC=com
ldap.managerDN=CN=nameofuser,CN=groupforuser,DC=yourdomain,DC=com
ldap.managerSecret=the_very_secret_string
ldap.userSearchBase=
ldap.userSearchFilter=(&(objectClass=person)(|(sAMAccountName={0})(userPrincipalName={0}@*)))
ldap.emailAddressLDAPAttribute=mail
ldap.displayNameLDAPAttribute=displayName
ldap.groupMembershipAttribute=memberOf
#ldap.groupSearchBase=OU=groups
#ldap.groupSearchFilter=(&(member={0})(objectClass=group))|
The managerSecret value can either be defined in plain text, or you can encrypt the password from an MQL client using the "mql encrypt" feature.
The encrypted value can be used in the configuration file if you add the prefix
Eg.
|
ENOVIA/3DExperience Authentication
If the "loginService" is set to "enovia", TIF will authenticate users against the ENOVIA/3DExperience database.
http.webapp.jaxws.loginService=enovia
http.webapp.jaxws.realm=WebservicesThe second value defines the "realm". (See https://www.ietf.org/rfc/rfc2617.txt for more information about realms and basic authentication).
Spnego Authentication
Secondly, an example for spnego:
http.webapp.jaxws.loginService=spnego
http.webapp.jaxws.spnego.targetName=HTTP/tifserver.exampledomain.com
http.webapp.jaxws.realm=Webservices| Instead of specifying the targetName you may instead point out a property file that holds that value under the key targetName. See below: |
http.webapp.jaxws.loginService=spnego
http.webapp.jaxws.spnego.config=${tif.home}/etc/kerberos/spnego.properties
http.webapp.jaxws.realm=WebservicesThe spnego.properties defines the targetName like this:
${tif.home}/etc/kerberos/spnego.properties
targetName = HTTP/tifserver.exampledomain.comConfigure Security Constraints in WEB.XML
Within the "web.xml" file (webapps/jaxws/WEB-INF/web.xml) you need to setup the rules for the application.
If you have not started TIF, you will not find the web.xml file, instead
it will be found under webapps/jaxws/WEB-INF/web.xml.template. Upon start, TIF
will copy over the template file unless the web.xml file is found.
|
Below is an example when using ENOVIA/Basic authentication and how such might look like.
Note that in this example, each user that is supposed to use the web-services must have the role "WS-Integration-User". Note that depending on login service used (ldap or enovia), the role is either a LDAP role or an ENOVIA/3DExperience role.
<security-constraint>
<web-resource-collection>
<web-resource-name>blocked</web-resource-name>
<url-pattern>/service/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>WS-Integration-User</role-name>
</auth-constraint>
<user-data-constraint>
<transport-guarantee>NONE</transport-guarantee>
</user-data-constraint>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>Webservices</realm-name>
</login-config>Below is an example for Spnego:
<security-constraint>
<web-resource-collection>
<web-resource-name>blocked</web-resource-name>
<url-pattern>/service/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>EXAMPLEDOMAIN.COM</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>SPNEGO</auth-method>
<realm-name>Webservices</realm-name>
</login-config>8.2. Hosting SOAP Web Service
TIF allows deploying custom SOAP Webservice’s.
8.2.1. Custom Axis Archive (AAR)
If you have built a Webservice and packaged it as an AAR file, you can simply drop your AAR file with in the directory:
${TIF_ROOT}/modules/enovia/webapps/jaxws/WEB-INF/services
These services are then automatically deployed during startup.
8.2.2. @WebMethod Annotated Classes (JSR 181)
It is also possible host web services that are implemented by JSR 181 annotated Java classes.
The web service classes needs to be compiled with the help of the Apache Axis2 libs in to a JAR file.
The web service is deployed by dropping the compiled JAR file into ${TIF_ROOT}/modules/enovia/webapps/jaxws/WEB-INF/servicejars.
For example:
package com.acme.tif;
import javax.jws.WebMethod;
import javax.jws.WebParam;
import javax.jws.WebService;
import javax.jws.soap.SOAPBinding;
@SOAPBinding(style = SOAPBinding.Style.RPC)
@WebService(serviceName = "MyWebService", targetNamespace = "http://technia.com")
public class MyWebService {
@WebMethod(operationName = "myMethod")
public String myMethod(@WebParam(name = "yourString") String yourString) {
return yourString + " received";
}
}8.2.3. Custom Web-application
An alternative to use Apache Axis and AAR files, is to use Apache CXF and host the CXF application inside TIF.
You deploy custom webapps by creating a new folder below ${TIF_ROOT}/modules/enovia/webapps.
By default, the URL to such webapp is following this format
http://hostname:8181/enovia/name-of-folder/...
Note that you can customize the context path per webapp via ${TIF_ROOT}/modules/enovia/etc/module.custome.properties.
8.2.4. Apache CXF Base Web Application with Logging Support
There is a Apache CXF base webapp under ${TIF_ROOT}/modules/enovia/webapps/cxf that can be used as base/template for CXF based web services.
There are own servlet filters for SOAP and RESTFul web services that can be used for logging web service calls to TIF DB. See web.xml for filter details. Also, there is cxf-servlet.xml that contains configurations for example web services.
| If you have not started TIF, you will not find the web.xml or cxf-template.xml file, instead there are template files. Upon start, TIF will copy over the template file unless the web.xml or cxf-template.xml file is found. |
8.2.5. Logging
Hosted SOAP web service is automatically logged in the TIF database. It appears as a SOAP service in Admin UI.
For example, http://localhost:8181/enovia/jaxws/services/myService is visible in Admin UI as "myService" SOAP service.
Limiting Logged Payload
There are configurable webapp init parameters to set maximum length for logged inbound (request) and outbound (response) payloads. Parameters help to limit usage of heap memory and storage by preventing to persist too large payloads to TIF DB.
See parameters "inboundPayloadMaxLength" and "outboundPayloadMaxLength" in web.xml.
|
Default value for parameters is 1 000 000 bytes, if not defined. |
8.3. Directory / File Listener
Some legacy systems communicate with each other by creating files in certain directories in the file system. TIF provides built-in support for setting up one or several listeners that will listen to changes in a directory (or directories) in the file-system and then perform some action.
You can listen to events in the file system like CREATE or MODIFY. By default, a directory listener will react upon the CREATE event.
When a directory listener receives an event, the processing of the file will take place a few moments later according to the configured pickup-delay (default is 3000 ms.). This pickup delay will ensure that we do not react upon multiple events for the same file, which may be the case on some Operating Systems (Windows using file-shares for example).
8.3.1. Configuration Details
You can set-up several directory listeners, each will then listen to different directories within the file-system.
| Do not configure multiple listeners that will listen to the same or a sub-directory as another directory listeners is configured for. |
The preferred way of configuring such listener is to use the XML configuration format.
E.g. adding a file within the directory ${TIF_ROOT}/modules/enovia/cfg/directorylistener.
By default, this directory is scanned upon startup and all configured listeners therein will be registered automatically.
You can configure this behaviour within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties via the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
resources.directorylistener.autoRegister |
boolean |
True |
Use this property to disable the auto registration |
resources.directorylistener.excluded |
Comma separated list |
Comma separated list of resources to be excluded. |
|
resources.directorylistener.included |
Comma separated list |
Comma separated list of resources to be included. |
By default, auto registration is enabled and no resources are excluded.
XML Configuration Format
The root element is <DirectoryListener>. The table below lists the allowed child elements:
| Element | Required | Description | Example |
|---|---|---|---|
|
Yes |
Defines a user friendly name of this configuration |
|
|
No |
Defines the pickup delay in milliseconds. Default is 3000. |
|
|
No |
Can be used to define a File Destination that defines the directory where to listen from. Either this is defined OR the |
|
|
Yes, unless a |
Defines input/output/error paths. |
See below. |
|
No |
Define file system events to react upon. Default is CREATE event only. |
|
No |
Defines if to establish an ENOVIA/3DExperience context |
|
|
Yes |
Defines the handler containing your businesslogic that is processing the message |
|
|
The <Paths> element supports the following attributes.
- recurse
-
A boolean specifying if to register to sub-directories also. Default is true
- processExistingOnStartup
-
A boolean specifying if to process files in the input directory upon startup. Default is true.
- registerNewDirectories
-
A boolean specifying if to register new directories created within the monitored file-area. Default is true.
- delete
-
Whether or not to delete the file after it has been processed.
If donePath and/or errorPath has been set then the file is moved instead of being deleted, even if delete flag is set to true.
|
The <Paths> element supports the following child elements.
| Element | Required | Description | Example |
|---|---|---|---|
|
Yes |
Defines input directory. Use multiple |
|
|
No |
Defines a directory, which files are moved to upon successful processing |
|
|
No |
Defines a directory, which files are moved to upon an error |
|
The <Events> element supports the following child elements.
| Element | Required | Description |
|---|---|---|
|
No |
React upon create events |
|
No |
React upon modify events |
|
No |
React upon delete events |
| Leaving the Events out implies reacting upon Create events. |
The <WithContext> element supports the following attributes.
| Attribute | Required | Description |
|---|---|---|
user |
No |
If omitted, the super user will be used |
securityContext |
No |
Defines the security context to be used |
useDefaultSecurityContext |
No |
If set to true, the default security context for the user will be used. The used user must have a default security context otherwise an error will be raised. |
The <Handler> element supports one of these three attributes
- className
-
The name of a class implementing
com.technia.tif.enovia.file.WatcherHandler. See chapter below. - script
-
Name of a script resource. Example:
script="tvc:script/MyHandler.js". See chapter below. - type
-
Name of a pre-defined type. Example:
type="SomePredefinedType"
Example configuration:
<tif:DirectoryListener
xmlns:tif="http://technia.com/TIF/DirectoryListener"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://technia.com/TIF/DirectoryListener file:///C:/apps/tif-server/modules/enovia/schema/DirectoryListener.xsd">
<tif:Name>Test Listener</tif:Name>
<tif:Paths>
<tif:Input>/test/a/input</tif:Input>
<tif:Output>/test/a/done</tif:Output>
<tif:Error>/test/a/error</tif:Error>
</tif:Paths>
<tif:WithContext />
<tif:Handler className="com.acme.integrations.part.DefaultMessageReceiver" />
</tif:AMQPListener>|
When TIF is running in development mode, you can edit, create or delete configurations at runtime and those will be hot deployed automatically without the need to restart the TIF instance or take any further action. However, in production mode, you can only edit a definition at runtime, but in order to take the changes into use you need to restart the corresponding service activator from within the Administration UI. Add or delete configurations is not supported. See also this chapter for more info |
Registration via Module Properties
The recommended way of registering a directory listener is to use the XML configuration format as described in the previous chapter.
However, you may still register a listener from with the module properties file. E.g. using the file
${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
Below is an example configuration:
directoryListener.0.enabled = true
directoryListener.0.name = A User Friendly Name
directoryListener.0.directories = /var/integration/erp
directoryListener.0.recurse = true
directoryListener.0.className = com.acme.integrations.ERPDirectoryListener
directoryListener.0.context = true
directoryListener.0.context.user = ...
directoryListener.0.context.securityContext = ..
directoryListener.0.context.useDefaultSecurityContext = true|falseThe prefix of a directory listener is directoryListener.<ID>. where <ID> is a unique identifier containing letters and/or digits.
The available property suffices are shown in the table below.
| Property Suffix | Description | Required | Default |
|---|---|---|---|
name |
Defines a user friendly name of the service, used for example in the Admin UI |
No |
Default the name is equal to the ID |
enabled |
Defines if the directory listener should be enabled or not. |
No |
True |
directories |
The directories to listen for changes in. Use ";" (semi-colon) on Windows to separate multiple directories and ":" (colon) on UNIX. |
Yes |
|
recurse |
Whether or not if to recursively listen to changes in directories below the specified. |
No |
True |
deleteFile |
Whether or not to delete the file after it has been processed. Note that if the |
No |
False |
donePath |
Specifies a directory, to which successfully processed files will be moved into |
No |
|
errorPath |
Specifies a directory, to which processed files that failed will be moved into |
No |
|
events |
Specifies a comma separated list of events that we should react upon. Possible values are
|
No |
create |
pickupDelay |
Specifies the delay in milliseconds to delay the processing of the file |
No |
3000 |
processExistingOnStartup |
Specifies if to process existing files in the directories we watch upon startup. Note that this flag should not be set to true in case you choose to NOT delete the files nor move it after processing. Otherwise the same files will be processed every time you start TIF, or restart the particular service. |
No |
True |
registerNewDirectories |
Specifies if to register new directories being added as being watched. Note that this will only have effect if also the recurse flag is set to true. |
No |
True |
context |
A boolean value indicating if an ENOVIA/3DExperience context object should be allocated when the handler is invoked. |
No. |
False. |
context.user |
An optional name of a ENOVIA/3DExperience user (used if context = true). May be omitted to indicate that the default ENOVIA/3DExperience system-user should be used. |
No |
Defaults to the system user. |
context.securityContext |
Specify ENOVIA/3DExperience security context. |
No |
|
context.useDefaultSecurityContext |
Specify to use the default security context on the user. |
No |
False |
className |
Defines a fully qualified class name of a Java class implementing "com.technia.tif.enovia.file.WatcherHandler". See below. |
One of the attributes |
|
script |
A script that implements the same functionality as a corresponding Java class. See below. |
Example registration:
${TIF_ROOT}/modules/enovia/etc/module.custom.properties
directoryListener.0.enabled = true
directoryListener.0.directories = /var/integration/erp
directoryListener.0.recurse = false
directoryListener.0.context = true
directoryListener.0.donePath = /var/integration/erp/succeeded
directoryListener.0.errorPath = /var/integration/erp/failed
directoryListener.0.className = com.acme.tif.FileProcessor8.3.2. Java Class
The Java class pointed out via the className attribute must implement the interface com.technia.tif.enovia.file.WatcherHandler in TIF. This Watcher-Handler API looks like:
package com.technia.tif.enovia.file;
import java.nio.file.Path;
/**
* @author Technia
*/
public interface WatcherHandler {
/**
* @param event The event causing this call
* @param p The path
*/
void handleEvent(WatchEvent event, Path p);
}The first argument to the "handleEvent" is an enum instance, which may have the following values:
WatchEvent.CREATE WatchEvent.MODIFY WatchEvent.DELETE
8.3.3. Script
Instead of implementing the WatcherHandler as a traditional Java class you may implement this in a script file.
Scripts are stored and handled as a XML resource file, described in chapter [XXX].
Example:
directoryListener.TEST.script = DirectoryListener.js
or
directoryListener.TEST.script = tvc:script/DirectoryListener.js
or
directoryListener.TEST.script = tvc:script:domain/DirectoryListener.js
A directory listener implemented as a script has the same method signature as the corresponding Java-class implementation.
function handleEvent(type, path) {
if (type == "CREATE") {
} else if (type == "DELETE") {
} else if (type == "MODIFY") {
}
}The last argument is an object of type java.nio.file.Path
8.4. JMS Listener / Message Receiver
You may want to listen to a JMS queue or topic from TIF. This page describes how to set-up a so called JMS Message Receiver in TIF.
8.4.1. Configuration Details
You can set-up several JMS listeners, each will then listen to different queues or topics.
The preferred way of configuring such listener is to use the XML configuration format.
E.g. adding a file within the directory ${TIF_ROOT}/modules/enovia/cfg/jmslistener.
By default, this directory is scanned upon startup and all configured listeners therein will be registered automatically.
You can configure this behavior within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties via the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
resources.jmsListener.autoRegister |
boolean |
True |
Use this property to disable the auto registration |
resources.jmsListener.excluded |
Comma separated list |
Comma separated list of resources to be excluded. |
|
resources.jmsListener.included |
Comma separated list |
Comma separated list of resources to be included. |
By default, auto registration is enabled and no resources are excluded.
XML Configuration Format
The root element is <JMSListener>. The table below lists the allowed child elements
| Element | Required | Description | Example |
|---|---|---|---|
|
Yes |
Defines a user friendly name of this configuration |
|
|
Yes |
Defines what destination to listen from |
|
|
No |
Defines if to establish an ENOVIA/3DExperience context |
|
|
Yes |
Defines the handler containing your business logic that is processing the message |
|
|
No |
Can be used to specify a selector, which then will limit the messages based upon the criteria in the selector. |
|
|
No |
Defines number of concurrent consumers. Typically used with destination listening to a queue. |
|
|
No |
Boolean defining if to share connection per destination with other JMS listeners. The common default value can be configured with property |
|
|
Yes |
Defines a user friendly name of this configuration |
|
The <WithContext> element supports the following attributes.
| Attribute | Required | Description |
|---|---|---|
user |
No |
If omitted, the super user will be used |
securityContext |
No |
Defines the security context to be used |
useDefaultSecurityContext |
No |
If set to true, the default security context for the user will be used. The used user must have a default security context otherwise an error will be raised. |
The <Handler> element supports one of these three attributes
- className
-
The name of a class implementing
com.technia.tif.enovia.jms.MessageReceiver. See chapter below. - script
-
Name of a script resource. Example:
script="tvc:script/MyMessageReceiver.js". See chapter below. - type
-
Name of a pre-defined type. Example:
type="SomePredefinedType"
Example configuration:
<tif:JMSListener
xmlns:tif="http://technia.com/TIF/JMSListener"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://technia.com/TIF/JMSListener file:///C:/apps/tif-server/modules/enovia/schema/JMSListener.xsd">
<tif:Name>Test Listener</tif:Name>
<tif:Destination id="part-from-erp" />
<tif:WithContext />
<tif:Handler className="com.acme.integrations.part.DefaultMessageReceiver" />
</tif:JMSListener>|
When TIF is running in development mode, you can edit, create or delete configurations at runtime and those will be hot deployed automatically without the need to restart the TIF instance or take any further action. However, in production mode, you can only edit a definition at runtime, but in order to take the changes into use you need to restart the corresponding service activator from within the Administration UI. Add or delete configurations is not supported. See also this chapter for more info |
| Too high consumer count will result in performance degradation. |
Registration via Module Properties
The recommended way of registering a JMS listener is to use the XML configuration format as described in the previous chapter.
However, you may still register a listener from with the module properties file. E.g. using the file
${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
Below is an example configuration:
jmsListener.0.enabled = true jmsListener.0.className = com.technia.tif.enovia.jms.TestReceiver jmsListener.0.destination = jms-1 jmsListener.0.context = true jmsListener.0.name = Service Name
The prefix of a JMS listener is jmsListener.<ID>. where <ID> is a unique identifier containing only letters and/or digits.
The available property suffices are shown in the table below.
| Property Suffix | Description | Required |
|---|---|---|
enabled |
Defines if the directory listener should be enabled or not. |
No. Default is true |
destination |
The ID of a JMS destination defined in the "destination.xml" file. See Configure Destinations for details how to register destinations. |
Yes |
context |
A boolean value indicating if an ENOVIA/3DExperience context object should be allocated when the message receiver is invoked. |
No. Default is false. |
context.user |
An optional name of a ENOVIA/3DExperience user (used if context = true). May be omitted to indicate that the default ENOVIA/3DExperience system-user should be used. |
No. Defaults to the system user. |
context.securityContext |
Specify ENOVIA/3DExperience security context. |
No |
context.useDefaultSecurityContext |
Specify to use the default security context on the user. |
No |
name |
Name of the service. Used in the Admin UI. |
No. |
messageSelector |
Optional string used for selecting messages. See this page for additional information. |
No. |
className |
Defines a fully qualified class name of a Java class either:
See below. |
One of the attributes className or script must be defined. |
script |
A script that implements the same functionality as a corresponding Java class. See below. |
8.4.2. Java Class
The Java class pointed out via the className attribute must implement the interface MessageReceiver in TIF. This API looks like:
package com.technia.tif.enovia.jms;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.Session;
import com.technia.tif.core.annotation.API;
/**
*
* @author Technia
* @since 2 maj 2013
*/
@API
public interface MessageReceiver {
/**
* Called prior to the JMS connection and session is closed. Note that there
* is no guarantee that this method is invoked, however, you can implement
* this method if you need to release any resource you have opened.
*/
void close();
/**
* @return True if to use transactions.
*/
boolean isTransacted();
/**
* @return The acknowledgemode. Must be any of the integer constants defined
* in the Session class.
*/
int getAcknowledgeMode();
/**
* Called when a new message appears.
*
* @param message The message to handle
* @throws Exception
*/
void onMessage(Message message) throws Exception;
/**
* If an exception occurs, this method is called.
*
* @param exception The JMS exception
*/
void onException(JMSException exception);
/**
* Called upon creation of a response message.
*
* @param session
* @param message
* @return
* @throws JMSException
* @since 2015.3.0
*/
Message createResponseMessage(Session session, Message message) throws JMSException;
}For convenience, there is an adapter class available called com.technia.tif.enovia.jms.MessageReceiverAdapter that can be used instead. This adapter class only has one abstract method, namely "onMessage". This adapter class returns false for the "isTransacted" and "Session.AUTO_ACKNOWLEDGE" for the acknowledge mode as default.
For incoming messages that has a replyTo destination set, TIF will call the createResponseMessage method, which allows you to create the proper message to be re-delivered back to the sender.
|
8.4.3. Script
Instead of implementing the MessageReceiver as a traditional Java class you may implement this in a script file.
Scripts are stored and handled as a XML resource file, described at [XXX].
Examples:
jmsListener.TEST.script = JMSListener.js (1) jmsListener.TEST.script = tvc:script/JMSListener.js (2) jmsListener.TEST.script = tvc:script:domain/JMSListener.js (3)
| 1 | refers to the file cfg/script/JMSListener.js |
| 2 | refers to the file cfg/script/JMSListener.js |
| 3 | refers to the file cfg/domain/script/JMSListener.js |
The script you write must as a minimum implement the "onMessage" method, and you may implement the others defined in the interface. The default value for "isTransacted" is FALSE and "Session.AUTO_ACKNOWLEDGE" for the "acknowledge mode".
Example:
function onMessage(msg) {
// do something
}
function isTransacted() {
return false;
}8.5. RabbitMQ Listener / Message Receiver
You may want to receive messages from a Rabbit MQ message broker. This page describes how to set-up a so called RabbitMQ Message Receiver in TIF allowing you to do so.
8.5.1. Configuration Details
You can set-up several RabbitMQ listeners, each will then listen to different queues or topics.
The preferred way of configuring such listener is to use the XML configuration format.
E.g. adding a file within the directory ${TIF_ROOT}/modules/enovia/cfg/rabbitmqlistener.
By default, this directory is scanned upon start-up and all configured listeners therein will be registered automatically.
You can configure this behaviour within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties via the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
resources.rabbitmqlistener.autoRegister |
boolean |
True |
Use this property to disable the auto registration |
resources.rabbitmqlistener.excluded |
Comma separated list |
Comma separated list of resources to be excluded. |
|
resources.rabbitmqlistener.included |
Comma separated list |
Comma separated list of resources to be included. |
By default, auto registration is enabled and no resources are excluded.
XML Configuration Format
The root element is <AMQPListener>. The table below lists the allowed child elements
| Element | Required | Description | Example |
|---|---|---|---|
|
Yes |
Defines a user friendly name of this configuration |
|
|
Yes |
Defines what destination to listen from |
|
|
No |
Defines if to establish an ENOVIA/3DExperience context |
|
|
Yes |
Defines the handler containing your business logic that is processing the message |
|
|
No |
Some handlers might accept arguments. |
|
The <WithContext> element supports the following attributes.
| Attribute | Required | Description |
|---|---|---|
user |
No |
If omitted, the super user will be used |
securityContext |
No |
Defines the security context to be used |
useDefaultSecurityContext |
No |
If set to true, the default security context for the user will be used. The used user must have a default security context otherwise an error will be raised. |
The <Handler> element supports one of these three attributes
- className
-
The name of a class implementing
com.technia.tif.enovia.rabbitmq.MessageReceiver. See chapter below. - script
-
Name of a script resource. Example:
script="tvc:script/MyMessageReceiver.js". See chapter below. - type
-
Name of a pre-defined type. Example:
type="SomePredefinedType"
Example configuration:
<tif:AMQPListener
xmlns:tif="http://technia.com/TIF/AMQPListener"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://technia.com/TIF/AMQPListener file:///C:/apps/tif-server/modules/enovia/schema/AMQPListener.xsd">
<tif:Name>Test Listener</tif:Name>
<tif:Destination id="part-from-erp" />
<tif:WithContext />
<tif:Handler className="com.acme.integrations.part.DefaultMessageReceiver" />
</tif:AMQPListener>|
When TIF is running in development mode, you can edit, create or delete configurations at runtime and those will be hot deployed automatically without the need to restart the TIF instance or take any further action. However, in production mode, you can only edit a definition at runtime, but in order to take the changes into use you need to restart the corresponding service activator from within the Administration UI. Add or delete configurations is not supported. See also this chapter for more info |
Registration via Module Properties
The recommended way of registering a Rabbit-MQ listener is to use the XML configuration format as described in the previous chapter.
However, you may still register a listener from with the module properties file.
E.g. using the file ${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
Below is an example configuration:
rabbitmqListener.0.enabled = true rabbitmqListener.0.className = com.technia.tif.enovia.rabbitmq.TestReceiver rabbitmqListener.0.destination = rabbitmq-1 rabbitmqListener.0.context = true rabbitmqListener.0.name = Service Name
The prefix of a RabbitMQ listener is rabbitmqListener.<ID>. where <ID> is a unique identifier containing only letters and/or digits.
The available property suffices are shown in the table below.
| Property Suffix | Description | Required |
|---|---|---|
enabled |
Defines if the directory listener should be enabled or not. |
No. Default is true |
destination |
The ID of a RabbitMQ destination defined in the "destination.xml" file. See Configure Destinations for details how to register destinations. |
Yes |
context |
A boolean value indicating if an ENOVIA/3DExperience context object should be allocated when the message receiver is invoked. |
No. Default is false. |
context.user |
An optional name of a ENOVIA/3DExperience user (used if context = true). May be omitted to indicate that the default ENOVIA/3DExperience system-user should be used. |
No. Defaults to the system user. |
context.securityContext |
Specify ENOVIA/3DExperience security context. |
No |
context.useDefaultSecurityContext |
Specify to use the default security context on the user. |
No |
name |
Name of the service. Used in the Admin UI. |
No. |
className |
Defines a fully qualified class name of a Java class that implements "com.technia.tif.enovia.rabbitmq.MessageReceiver". See below. |
One of the attributes className or script must be defined. |
script |
A script that implements the same functionality as a corresponding Java class. See below. |
8.5.2. Java Class
The Java class pointed out via the className attribute must implement the interface MessageReceiver in TIF. This API looks like:
package com.technia.tif.enovia.rabbitmq;
/**
* This interface must be implemented to handle messages received by RabbitMQ
* listener.
*
* @since 2015.3.0 Initial version
* @since 2020.2.0 Refactored to support better message control
*/
public interface MessageReceiver {
/**
* Called when a new message appears.
*
* @param msg The message to handle
* @return The result of the operation. Depending on the result, the message
* will either be acknowledged (with multiple flag set or not),
* not-acknowledged (rejected) (with multiple flag set or not) or
* nothing is done.
* @throws Exception If a failure occurs.
*/
Result onMessage(Message msg) throws Exception;
/**
* If an exception occurs, this method is called. The default implementation
* does nothing and returns a {@link Result#NACK} value.
*
* @param e The exception
* @param msg The message
*/
default Result onException(Exception e, Message msg) {
return Result.NACK;
}
}The return value enum constants are described below.
- DO_NOTHING
-
Do nothing
- ACK
-
Acknowledges the current message
- NACK
-
Rejects the current message
- NACK_REQUEUE
-
Rejects the current message and requeues it
- ACK_MULTIPLE
-
Acknowledges multiple messages, e.g. all messages that have not yet been ack/nack’ed
- NACK_MULTIPLE
-
Rejects multiple messages.
- NACK_MULTIPLE_REQUEUE
-
Rejects multiple messages and requeues all.
8.5.3. Script
Instead of implementing the MessageReceiver as a traditional Java class you may implement this in a script file.
Scripts are stored and handled similar to any other configuration resource file, e.g. below the cfg folder.
The scripts goes into the folder script, e.g. ${TIF_HOME}/modules/enovia/cfg/script.
You may also use domains, as for the other configuration files. See below:
Examples:
rabbitmqListener.TEST.script = RabbitMQListener.js (1) rabbitmqListener.TEST.script = tvc:script/RabbitMQListener.js (2) rabbitmqListener.TEST.script = tvc:script:domain/RabbitMQListener.js (3)
| 1 | refers to the file cfg/script/RabbitMQListener.js |
| 2 | refers to the file cfg/script/RabbitMQListener.js |
| 3 | refers to the file cfg/domain/script/RabbitMQListener.js |
The script you write must implement "onMessage" and "onException" methods.
Example:
function onMessage(msg) {
// Logic goes here.
return com.technia.tif.enovia.rabbitmq.Result.ACK;
}
//Override if needed to handle exception
//function onException(e, msg) {
//
// return com.technia.tif.enovia.rabbitmq.Result.NACK;
//}8.6. Kafka Message Receiver
You may want to listen for records (messages) from an Apache Kafka topic. This page describes how to set-up a so called kafka message listener in TIF.
8.6.1. Configuration Details
The preferred way of configuring a kafka listener is to use the XML configuration format.
E.g. adding a file within the directory ${TIF_ROOT}/modules/enovia/cfg/kafkalistener.
By default, this directory is scanned upon startup and all configured listeners therein will be registered automatically.
You can configure this behavior within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties via the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
resources.kafkalistener.autoRegister |
boolean |
True |
Use this property to disable the auto registration |
resources.kafkalistener.excluded |
Comma separated list |
Comma separated list of resources to be excluded. |
|
resources.kafkalistener.included |
Comma separated list |
Comma separated list of resources to be included. |
By default, auto registration is enabled and no resources are excluded.
XML Configuration Format
The root element is <KafkaListener>. The table below lists the allowed child elements
| Element | Required | Description | Example |
|---|---|---|---|
|
Yes |
Defines a user friendly name of this configuration |
|
|
Yes |
Defines one or more topics to subscribe to. Use separate tags in case you subscribe to multiple topics. |
|
|
Yes |
Defines the consumer group this consumer belongs to |
|
|
No |
Defines a custom client identifier |
|
|
No |
Defines what should happen in case of an error occurs while processing a record. Per default, TIF will stop processing further records if this happens. Otherwise the record would be committed and it would be difficult to recover from such state. You can however specify that TIF should continue work with future records by setting this to "continue". |
|
|
Yes |
Defines what destination to listen from |
|
|
No |
Defines if to establish an ENOVIA/3DExperience context |
|
|
Yes |
Defines the handler containing your business logic that is processing the message |
|
|
No |
Some handlers might accept arguments. |
|
The <WithContext> element supports the following attributes.
| Attribute | Required | Description |
|---|---|---|
user |
No |
If omitted, the super user will be used |
securityContext |
No |
Defines the security context to be used |
useDefaultSecurityContext |
No |
If set to true, the default security context for the user will be used. The used user must have a default security context otherwise an error will be raised. |
The <Handler> element supports one of these three attributes
- className
-
The name of a class implementing
com.technia.tif.enovia.kafka.MessageReceiver. See chapter below. - script
-
Name of a script resource. Example:
script="tvc:script/MyMessageReceiver.js". See chapter below. - type
-
Name of a pre-defined type. Example:
type="SomePredefinedType"
Example configuration:
<tif:KafkaListener
xmlns:tif="http://technia.com/TIF/KafkaListener"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://technia.com/TIF/KafkaListener file:///C:/apps/tif-server/modules/enovia/schema/KafkaListener.xsd">
<tif:Name>Test Listener</tif:Name>
<tif:Topic>TIF-JOB-TEST</tif:Topic>
<tif:GroupId>TEST_GROUP</tif:GroupId>
<tif:OnError>continue</tif:OnError>
<tif:Destination id="kafka-dest-001" />
<tif:WithContext />
<tif:Handler className="com.acme.integrations.DefaultMessageReceiver" />
</tif:KafkaListener>|
When TIF is running in development mode, you can edit, create or delete configurations at runtime and those will be hot deployed automatically without the need to restart the TIF instance or take any further action. However, in production mode, you can only edit a definition at runtime, but in order to take the changes into use you need to restart the corresponding service activator from within the Administration UI. Add or delete configurations is not supported. See also this chapter for more info |
Registration via Module Properties
The recommended way of registering a KAfka listener is to use the XML configuration format as described in the previous chapter.
However, you may still register a listener from with the module properties file. E.g. using the file
${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
This is configured within the "module.properties" file within the etc folder. See page this page for details how to modify this file.
Below is an example configuration:
kafkalistener.test.enabled = false
kafkalistener.test.destination = kafka-1
kafkalistener.test.topic = TIF-JOB-TEST
kafkalistener.test.groupId = TEST_GROUP
#kafkalistener.test.className = com.technia.tif.enovia.kafka.service.DefaultMessageReceiver
kafkalistener.test.type = CreateUpdateIntegration
kafkalistener.test.configuration = Part_from_ERP.xmlThe prefix of a kafka listener is kafkaListener.<NAME>. where <NAME> is a unique name containing only letters and/or digits.
The available property suffices are shown in the table below.
| Property Suffix | Description | Required |
|---|---|---|
enabled |
Defines if the kafka listener should be enabled or not. |
No. Default is true |
destination |
The ID of a kafka destination defined in the "destination.xml" file. See Configure Destinations for details how to register destinations. |
Yes |
context |
A boolean value indicating if an ENOVIA/3DExperience context object should be allocated when the message receiver is invoked. |
No. Default is false. |
context.user |
An optional name of a ENOVIA/3DExperience user (used if context = true). May be omitted to indicate that the default ENOVIA/3DExperience system-user should be used. |
No. Defaults to the system user. |
context.securityContext |
Specify ENOVIA/3DExperience security context. |
No |
context.useDefaultSecurityContext |
Specify to use the default security context on the user. |
No |
name |
Name of the service. Used in the Admin UI. |
No. |
className |
Defines a fully qualified class name of a Java class that implements |
One of the attributes className or script must be defined. |
script |
A script that implements the same functionality as a corresponding Java class. See below. |
|
topic |
Defines the topic to subscribe to. For multiple topic subscription, separate with a comma. |
Yes |
groupId |
Defines the consumer group to which this listener is a member of |
Yes |
clientId |
Defines an arbitrary client identifier |
No |
onError |
Defines behavior for the listener if an exception occurs. Per default, onError is set to stop but can be changed to continue if desired |
No |
8.6.2. Java Class
The Java class pointed out via the className attribute and must
implement the interface com.technia.tif.enovia.kafka.MessageReceiver.
Example skeleton below:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import com.technia.tif.enovia.kafka.MessageReceiver;
import com.technia.tif.enovia.kafka.MessageContext;
import com.technia.tif.enovia.kafka.Result;
public class MyConsumer implements MessageReceiver {
@Override
public Result onMessage(MessageContext ctx) {
ConsumerRecord record = ctx.getRecord();
// ...
return result;
}
}8.6.3. Script
Instead of implementing the MessageReceiver as a traditional Java class you may implement this in a script file.
Scripts are stored and handled as a XML resource file, described at [XXX].
Examples:
kafkaListener.TEST.script = TestListener.js (1) kafkaListener.TEST.script = tvc:script/TestListener.js (2) kafkaListener.TEST.script = tvc:script:domain/TestListener.js (3)
| 1 | refers to the file cfg/script/TestListener.js |
| 2 | refers to the file cfg/script/TestListener.js |
| 3 | refers to the file cfg/domain/script/TestListener.js |
The script you write must implement at least the "onMessage" method.
Example:
function onMessage(ctx) {
var record = ctx.getRecord();
// do something
return ...;
}8.7. IBM MQ Listener / Message Receiver
You may want to listen for messages from a IBM MQ queue from TIF. This page describes how to set-up a so called IBM-MQ/NativeMQ/WebsphereMQ Message Listener in TIF.
8.7.1. Configuration Details
You can set-up several MQ listeners, each will then listen to different queues or topics.
The preferred way of configuring such listener is to use the XML configuration format.
E.g. adding a file within the directory ${TIF_ROOT}/modules/enovia/cfg/mqlistener.
By default, this directory is scanned upon startup and all configured listeners therein will be registered automatically.
You can configure this behavior within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties via the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
resources.mqlistener.autoRegister |
boolean |
True |
Use this property to disable the auto registration |
resources.mqlistener.excluded |
Comma separated list |
Comma separated list of resources to be excluded. |
|
resources.mqlistener.included |
Comma separated list |
Comma separated list of resources to be included. |
By default, auto registration is enabled and no resources are excluded.
XML Configuration Format
The root element is <MQListener>. The table below lists the allowed child elements
| Element | Required | Description | Example |
|---|---|---|---|
|
Yes |
Defines a user friendly name of this configuration |
|
|
Yes |
Defines what destination to listen from |
|
|
No |
Defines if to establish an ENOVIA/3DExperience context |
|
|
Yes |
Defines the handler containing your business logic that is processing the message |
|
|
No |
Some handlers might accept arguments. |
|
The <WithContext> element supports the following attributes.
| Attribute | Required | Description |
|---|---|---|
user |
No |
If omitted, the super user will be used |
securityContext |
No |
Defines the security context to be used |
useDefaultSecurityContext |
No |
If set to true, the default security context for the user will be used. The used user must have a default security context otherwise an error will be raised. |
The <Handler> element supports one of these three attributes
- className
-
The name of a class implementing
com.technia.tif.enovia.nativemq.MessageReceiver. See chapter below. - script
-
Name of a script resource. Example:
script="tvc:script/MyMessageReceiver.js". See chapter below. - type
-
Name of a pre-defined type. Example:
type="SomePredefinedType"
Example configuration:
<tif:MQListener
xmlns:tif="http://technia.com/TIF/MQListener"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://technia.com/TIF/MQListener file:///C:/apps/tif-server/modules/enovia/schema/MQListener.xsd">
<tif:Name>Test Listener</tif:Name>
<tif:Destination id="part-from-erp" />
<tif:WithContext />
<tif:Handler className="com.acme.integrations.part.DefaultMessageReceiver" />
</tif:MQListener>|
When TIF is running in development mode, you can edit, create or delete configurations at runtime and those will be hot deployed automatically without the need to restart the TIF instance or take any further action. However, in production mode, you can only edit a definition at runtime, but in order to take the changes into use you need to restart the corresponding service activator from within the Administration UI. Add or delete configurations is not supported. See also this chapter for more info |
Registration via Module Properties
The recommended way of registering a Rabbit-MQ listener is to use the XML configuration format as described in the previous chapter.
However, you may still register a listener from with the module properties file. E.g. using the file
${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
This is configured within the "module.properties" file within the etc folder. See page this page for details how to modify this file.
Below is an example configuration:
wmqListener.0.enabled = true wmqListener.0.className = com.technia.tif.enovia.nativemq.TestReceiver wmqListener.0.destination = mq-1 wmqListener.0.context = true wmqListener.0.name = Service Name
The prefix of a MQ listener is wmqListener.<NAME>. where <NAME> is a unique name containing only letters and/or digits.
The available property suffices are shown in the table below.
| Property Suffix | Description | Required |
|---|---|---|
enabled |
Defines if the mq listener should be enabled or not. |
No. Default is true |
destination |
The ID of a NativeMQ destination defined in the "destination.xml" file. See Configure Destinations for details how to register destinations. |
Yes |
context |
A boolean value indicating if an ENOVIA/3DExperience context object should be allocated when the message receiver is invoked. |
No. Default is false. |
context.user |
An optional name of a ENOVIA/3DExperience user (used if context = true). May be omitted to indicate that the default ENOVIA/3DExperience system-user should be used. |
No. Defaults to the system user. |
context.securityContext |
Specify ENOVIA/3DExperience security context. |
No |
context.useDefaultSecurityContext |
Specify to use the default security context on the user. |
No |
name |
Name of the service. Used in the Admin UI. |
No. |
className |
Defines a fully qualified class name of a Java class that implements |
One of the attributes className or script must be defined. |
script |
A script that implements the same functionality as a corresponding Java class. See below. |
8.7.2. Java Class
The Java class pointed out via the className attribute must either
implement the interface com.technia.tif.enovia.nativemq.MessageReceiver
or extend the class com.technia.tif.enovia.nativemq.MessageReceiverAdapter.
Example skeleton below:
import com.ibm.mq.MQMessage;
public class TestReceiver extends MessageReceiverAdapter {
@Override
public void onMessage(MQMessage message) {
}
}8.7.3. Script
Instead of implementing the MessageReceiver as a traditional Java class you may implement this in a script file.
Scripts are stored and handled as a XML resource file, described at [XXX].
Examples:
wmqListener.TEST.script = MQListener.js (1) wmqListener.TEST.script = tvc:script/MQListener.js (2) wmqListener.TEST.script = tvc:script:domain/MQListener.js (3)
| 1 | refers to the file cfg/script/MQListener.js |
| 2 | refers to the file cfg/script/MQListener.js |
| 3 | refers to the file cfg/domain/script/MQListener.js |
The script you write must implement at least the "onMessage" method.
Example:
function onMessage(msg) {
// do something
}8.8. Configurable RESTful Web Services
RESTful web services are created with XML configuration files. The services are used to expose information available in ENOVIA/3DExperience.
8.8.1. URL to a service
The base URL for services are (by default):
http://server:8181/enovia/jaxrs/service
| The example above uses the default context path /enovia/jaxrs. This path may be different in your environment since it can be configured. See the next chapter for more information how to change this. |
A list of available services can be retrieved by accessing the base URL. Services are listed in JSON format. Example using cUrl:
curl -X GET http://server:8181/enovia/jaxrs/service
Every service has a unique service name which is used when accessing it.
For example, a service with the name part is available on:
http://server:8181/enovia/jaxrs/service/part
Any information after the service name in the URL is interpreted as PathParameters. Example of URL using PathParameters:
http://server:8181/enovia/jaxrs/service/part/Resistor/1200-0001/1
8.8.2. Context Path to REST services
By default, the context path to the REST applications is /enovia/jaxrs/.
Within the file ${TIF_ROOT}/modules/enovia/etc/modules.custom.properties,
this can be changed using the property below.
http.webapp.jaxrs.contextPath = /enovia/jaxrs
^^^^^
As an alternative you could also change the path for all applications by using the below example.
http.webapp.contextPath.default = /tif/%2$s
The %2$s refers to the name of the webapp folder.
8.8.3. Example Configuration
A configurable REST service is stored below the folder ${TIF_HOME}/modules/enovia/cfg/restservice.
Note that you can also divide your configurations within domains so the restservice folder might not be placed
directly under the cfg directory.
<Rest>
<DisplayName>Part</DisplayName>
<ServiceName>part</ServiceName>
<IdLocator type="tnr">
<AllowWildcards>false</AllowWildcards>
</IdLocator>
<Read payload="tvc:payload:tix/PartData.xml" />
<Events>...</Events>
</Rest>8.8.4. Configuration
Configuration files are stored in the folder restservice. The root element of
the XML file is <Rest>. The available child elements are listed in the table
below.
| Element | Description | Mandatory | ||
|---|---|---|---|---|
|
User friendly name of the service. Used for instance the Admin UI. |
No, but recommended. |
||
|
Defines the name of the service. It is used by clients to access the service.
The name must be unique across all services. It may only consist of alfanumerical characters and forward slashes (/). |
No |
||
Defines how to find the object/s the client is interested in. Read more in the IdLocator chapter. |
No |
|||
Defines how to read data. Read more in the Read Operation chapter. |
Yes |
|||
See page Job Events for details. |
No |
|||
Defines the credentials that will be used when running the REST service. Read more in the Credentials chapter. |
Yes. |
|||
|
Defines the type of transaction to use while running the REST service. The possible values are:
|
No. An inactive (no transaction) is used. |
||
|
May be used to define additional access rules on the REST service. Example; only allow this REST service to operate on objects in a particular state, or in a particular vault. Or, restrict access to users assigned to a particular role or group. Read more in the Access chapter. |
No. |
If the <ServiceName> element is omitted, the name of the service is calculated based on its location in the filesystem.
For example, if a RestService is stored in the folder cfg/restservice/foo/bar/test.xml then its service name / path is calculated to foo/bar/test.
And in case a RestService is stored in the folder cfg/restservice/part-data.xml then its service name / path is calculated to part-data.
8.8.5. Lifecycle of a Call
-
Client sends HTTP request. The request include information about which service that is of interest along with addtional PathParameters/QueryParamters.
-
The RESTful web services corresponding to the request is located. TIF maintains a registry of all configurable services.
-
Optional: The IdLocator is executed. It is responsible for finding the object the client is requesting based on the PathParamters/QueryParameters.
-
The operation is executed. For example, extracting information for the Part found by the IdLocator.
-
The response is sent back to the client.
8.8.6. Credentials
The <Credentials> element contains the following attributes:
- containerManaged
-
A boolean value. Specifies if authentication is carried out via the servlet container. See chapter below how to configure this.
- runAs
-
A string value. Defines the name of the ENOVIA/3DExperience user that we will run the service as.
- runAsSuperUser
-
A boolean value. Useful together when
containerManaged=trueand you want to run the service as a super-user, while authentication is required. - handler
-
The fqn name of a class that implements the interface
com.technia.tif.enovia.security.ContextProviderHandler. See further down in this document for more details.
Valid child elements are defined in the table below
| Element | Description | Mandatory |
|---|---|---|
|
Used for defining the ENOVIA/3DExperience security context. See below how to configure this. |
No |
|
In case container managed authentication is enabled, you may define additional roles, which the authenticated user must have in order to gain access. These roles are typically not ENOVIA/3DExperience roles, in case of Kerberos authentication these will be roles from your Active Directory. Note that if you specify multiple roles, the user is only required to have one of the listed roles in order to get access. Example below: |
No. |
|
Specify additional ENOVIA/3DExperience assignments the user must have in order to proceed. Example below: |
No |
Custom Context Provider Handler
In some cases you may need some more fine-tuned control over what ENOVIA/3DExperience Context to be used.
The handler attribute is used to point out the class implementing the interface com.technia.tif.enovia.security.ContextProviderHandler.
| If you have enabled container managed authentication, the servlet container (the Jetty engine) have already done some authentication. In case you are using "enovia" as the login-service you will in that case has a "Context" set already. This Context Provider Handler cannot override/by-pass the container managed logic - if this is needed then you should disable the container managed security and take care about this in your custom ContextProviderHandler. |
public class MyContextProviderHandler implements ContextProviderHandler {
@Override
public ContextProvider apply(AuthorizationContext ctx, CredentialsConfig config) {
// Principal available in case container-managed-security is enabled. Otherwise, null.
Principal p = ctx.getPrincipal();
// EXAMPLE: Use the ENOVIA user credentials directly.
if (principal instanceof EnoviaUserPrincipal) {
EnoviaUserPrincipal eup = (EnoviaUserPrincipal) principal;
if (eup.isValid()) {
return eup;
}
}
// EXAMPLE: Get headers
List<String> headerNames = ctx.getHeaderNames();
for (String header : headerNames) {
System.out.printf("Header>>> %30s : %s%n", header, ctx.getHeaderValues(header));
}
// EXAMPLE: Get parameters
List<String> paramNames = ctx.getParameterNames();
for (String param : paramNames) {
System.out.printf("Parameter>>> %30s : %s%n", param,
StringUtils.concat(ctx.getParameterValues(param), "|"));
}
// EXAMPLE: Get other request based properties
if (ctx instanceof RequestBasedAuthorizationContext) {
RequestBasedAuthorizationContext rctx = (RequestBasedAuthorizationContext) ctx;
System.out.printf("Request URI>> %s%n", rctx.getHttpServletRequest().getRequestURI());
}
// EXAMPLE: Run as specific user
String runAs = ctx.getHeaderValue("x-run-as");
return ContextProviders.getRunAs(runAs);
}
}| In the above example we are not considering if the Credentials have been configured with Security Context nor Authorization rules. If you want to do this you can see below how to do so. |
import com.technia.tif.enovia.security.DefaultContextProviderHandler;
...
ContextProvider contextProvider = ...;
return DfaultContextProviderHandler.getInstance().apply(ctx, credentials, contextProvider);Security Context
Via the <SecurityContext> element you define what security context to use.
You may do the following.
-
Point out a mapping file
-
Or use a default mapping file
-
-
Specify a named security context
-
Or use the "default" security context as configured for the ENOVIA/3DExperience user
To point out a mapFile use the syntax below.
The file is relative to ${TIF_ROOT}/modules/enovia/etc
|
<SecurityContext mapFile="sec-mapping.xml" />Use the default mapping file.
The default file is specified via the property securityMapping.defaultFile, and the default value is security-context-mapping.xml.
The file is relative to ${TIF_ROOT}/modules/enovia/etc
|
<SecurityContext useDefaultMapFile="true" />The format of the mapping file is shown below:
<Contexts>
<Context name="Design Engineer.Company Name.GLOBAL">
<User is="user1" />(1)
<User is="user2" />
<User is="user3" />
<Role is="engineer" /> (2)
<Role is="designer" />
<Parameter name="test" is="something" /> (3)
<Parameter name="x" is="y" />
</Context>
<Context name="...">...</Context>
<Context name="...">...</Context>
</Contexts>NOTE that specifying user and role requires having enabled container managed authentication (Kerberos or Basic Authenticaton etc.)
| 1 | Specifies certain users to match against |
| 2 | Specifies additional roles the user should have |
| 3 | Specifies additional parameters and value to be evaluated In case of a REST service, the parameters are the request parameters passed to the service. |
The evaluation logic is:
-
User list is EMPTY or user is in list
-
Role list is EMPTY or user have one of the roles in the list
-
Parameter list is EMPTY or one of the parameters have the expected value
If A AND B AND C is satisfied, then use the security context defined for this "rule".
To use a specific Security Context:
<SecurityContext use="Design Engineer.Company Name.GLOBAL" />Specify using the default security context.
<SecurityContext useDefault="true" />Container Managed Security
You can enable security on the servlet container level and either use Kerberos/SPNego authentication OR use Basic authentication and authenticate against the ENOVIA/3DExperience database.
Configure Security Realm
Within the ${TIF_ROOT}/modules/enovia/etc/module.custom.properties, you need
to specify what login service to be used including its realm and optionally some
extra parameters.
The login services currently supported are
- enovia
-
A login service that will authenticate the remote user against the ENOVIA/3DExperience database.
- ldap
-
A login service that will authenticate the remote user against a LDAP directory (for example Active Directory)
- spnego
-
A login service supporting Single Sign On against Active Directory.
| In order to use Spnego authentication, also read this document in order to setup the core parts of Spnego/Kerberos. |
LDAP Authentication
If the "loginService" is set to "ldap", TIF will authenticate users against a LDAP directory.
http.webapp.jaxrs.loginService=ldap
http.webapp.jaxrs.realm=WebservicesThe second value defines the "realm". (See https://www.ietf.org/rfc/rfc2617.txt for more information about realms and basic authentication).
There are some additional LDAP settings required to be defined. You can specify global LDAP parameters and/or web application specific LDAP parameters. In most cases you will be fine with only global LDAP settings.
For convenience, the application specific parameters will be merged with the global LDAP parameters. Hence you only need to override/define the parameters that is different on the application level.
Please see the table below.
The global parameter name is ldap., while the application specific parameter
are named like http.webapp.<APP_NAME>.ldap.
|
| Parameter | Description | Required |
|---|---|---|
ldap.server |
Defines the server or list of LDAP servers. Separate with space if using multiple. |
Yes |
ldap.rootDN |
Defines the root dn, where all LDAP searches starts from. If we can start a search starting at a sub-node (as opposed to root), you get a better performance because it narrows down the scope of a search. This field specifies the DN of such a subtree. |
No |
ldap.userSearchBase |
The relative DN (From the root DN) that further narrow down searches to the sub-tree. If you do specify this value, the field normally looks something like "ou=people". |
No |
ldap.userSearchFilter |
This field determines the query to be run to identify the user record. The query is almost always "uid={0}" as per defined in RFC 2798, so in most cases you should leave this field empty and let this default kick in. If your LDAP server doesn’t have uid or doesn’t use a meaningful uid value, try "mail={0}", which lets people login by their e-mail address. If you do specify a different query, specify an LDAP query string with marker token "{0}", which is to be replaced by the user name string entered by the user. |
Yes |
ldap.groupMembershipAttribute |
If the user entry in the LDAP tree contains an attribute with the group membership, then specify that attribute here. Otherwise we need to query for the groups a user belongs to. |
Either this or the groupSearchBase / groupSearchFilter needs to be defined. |
ldap.groupSearchBase |
This field determines the query to be run to identify the organizational unit that contains groups. The query is almost always "ou=groups" so try that first, though this field may be left blank to search from the root DN. |
Not needed, but if the groupMembershipAttribute is undefined you can use this to make the group query faster. |
ldap.groupSearchFilter |
Defines the search filter for groups. In case we need to search the LDAP tree for group membership this needs to be defined. The marker token "{0}" is replaced with the current user’s DN. Example:
|
Yes unless groupMembershipAttribute is defined. |
ldap.managerDN |
If your LDAP server doesn’t support anonymous binding, then we would have to first authenticate itself against the LDAP server. A DN typically looks like It can be any valid DN as long as LDAP allows this user to query data. |
Probably Yes |
ldap.managerSecret |
The password for the manager DN |
Probably Yes |
ldap.displayNameLDAPAttribute |
The attribute holding the display name. Per default we use the CN of the user entry. |
No |
ldap.emailAddressLDAPAttribute |
The attribute holding the email value. Per default we use the field This field is currently not used so you can leave it blank. |
No |
ldap.pooled |
Whether or not to pool the LDAP connections |
No |
Example setup below for Active Directory.
ldap.server=ldapserver.yourdomain.com:3268
ldap.rootDN=DC=yourdomain,DC=com
ldap.managerDN=CN=nameofuser,CN=groupforuser,DC=yourdomain,DC=com
ldap.managerSecret=the_very_secret_string
ldap.userSearchBase=
ldap.userSearchFilter=(&(objectClass=person)(|(sAMAccountName={0})(userPrincipalName={0}@*)))
ldap.emailAddressLDAPAttribute=mail
ldap.displayNameLDAPAttribute=displayName
ldap.groupMembershipAttribute=memberOf
#ldap.groupSearchBase=OU=groups
#ldap.groupSearchFilter=(&(member={0})(objectClass=group))|
The managerSecret value can either be defined in plain text, or you can encrypt the password from an MQL client using the "mql encrypt" feature.
The encrypted value can be used in the configuration file if you add the prefix
Eg.
|
ENOVIA/3DExperience Authentication
If the "loginService" is set to "enovia", TIF will authenticate users against the ENOVIA/3DExperience database.
http.webapp.jaxrs.loginService=enovia
http.webapp.jaxrs.realm=WebservicesThe second value defines the "realm". (See https://www.ietf.org/rfc/rfc2617.txt for more information about realms and basic authentication).
Spnego Authentication
Secondly, an example for spnego:
http.webapp.jaxrs.loginService=spnego
http.webapp.jaxrs.spnego.targetName=HTTP/tifserver.exampledomain.com
http.webapp.jaxrs.realm=Webservices| Instead of specifying the targetName you may instead point out a property file that holds that value under the key targetName. See below: |
http.webapp.jaxrs.loginService=spnego
http.webapp.jaxrs.spnego.config=${tif.home}/etc/kerberos/spnego.properties
http.webapp.jaxrs.realm=WebservicesThe spnego.properties defines the targetName like this:
${tif.home}/etc/kerberos/spnego.properties
targetName = HTTP/tifserver.exampledomain.comConfigure Security Constraints in WEB.XML
Within the "web.xml" file (webapps/jaxrs/WEB-INF/web.xml) you need to setup the rules for the application.
If you have not started TIF, you will not find the web.xml file, instead
it will be found under webapps/jaxrs/WEB-INF/web.xml.template. Upon start, TIF
will copy over the template file unless the web.xml file is found.
|
Below is an example when using ENOVIA/Basic authentication and how such might look like.
Note that in this example, each user that is supposed to use the web-services must have the role "WS-Integration-User". Note that depending on login service used (ldap or enovia), the role is either a LDAP role or an ENOVIA/3DExperience role.
<security-constraint>
<web-resource-collection>
<web-resource-name>blocked</web-resource-name>
<url-pattern>/service/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>WS-Integration-User</role-name>
</auth-constraint>
<user-data-constraint>
<transport-guarantee>NONE</transport-guarantee>
</user-data-constraint>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>Webservices</realm-name>
</login-config>Below is an example for Spnego:
<security-constraint>
<web-resource-collection>
<web-resource-name>blocked</web-resource-name>
<url-pattern>/service/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>EXAMPLEDOMAIN.COM</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>SPNEGO</auth-method>
<realm-name>Webservices</realm-name>
</login-config>8.8.7. Access
The access restriction can be defined based upon following:
-
Role Assignment
-
Group Assignment
-
Person (A named user)
-
Access Mask (Access mask for the current object)
-
Access Program (A JPO that evaluates the access rights)
-
Access Expression (MQL expression that evaluates the access)
The example below illustrates how you can construct the access restriction:
<Access>
<Role>role_FirstRole</Role>
<Role>role_SecondRole</Role>
<Group>group_SomeGroup</Group>
<Mask>modify,checkout</Mask>
</Access>Or use an access program:
<Access>
<Program name="MyJPO" method="checkAccess"/>
</Access>Or use an access expression:
<Access>
<Expression><![CDATA[owner == context.user]]></Expression>
</Access>| The expression will only be possible to utilize on service’s that operates on one (1) business object. If your service would use an ID locator that returns multiple objects, the expression has no affect. |
8.8.8. Id Locators
The IdLocator is responsible for locating the object the client is requesting. This is done by using the PathParameters and/or QueryParameters associated in the request. For example, the parameters includes type, name and revision of the object or interest.
There are a number of built-in strategies for locating the object. It is also possible to write a custom IdLocator.
| IdLocators are optional. For example, a service returning all countries in the system does not require an IdLocator. |
The configuration element <IdLocator> supports following attributes:
| Name | Description | Mandatory | Default |
|---|---|---|---|
notFoundStrategy |
Defines what to do if IDs are not found. The valid values are
|
No |
|
Dataset
Uses a dataset to locate the object/s. The PathParameters/QueryParameters and the requested mimetype is available when using parameterized datasets. More information about parameterized datasets is available in the TVC Core Admin Guide.
The first PathParameter is available with the key pathparam_0, second one with
key pathpararm_1 and so on. The QueryParameters are available with the same
key as in the request to the service. The requested mime type uses the key mimetype.
- Example REST Config
<Rest>
<ServiceName>product</ServiceName>
<IdLocator dataset="tvc:data/ProductInStateFinder.xml" />
...
</Rest>- Example Dataset Config
<DataSet>
<LatestInState>
<State>$(pathparam_1,empty=false)</State>
<Query>
<NamePattern>
<Name>$(pathparam_0,empty=false)</Name>
</NamePattern>
<Limit>1</Limit>
</Query>
</LatestInState>
</DataSet>TNR
- Name
-
tnr
- Required PathParamters
-
3 (type/name/revision)
- Description
-
Uses type, name and revision to identify the object. A query is used in the background to find the matching object.
- Settings
| Name | Description | Default |
|---|---|---|
AllowWildcards |
Defines if wildcards are allowed in the paramters. |
false |
Limit |
Maximum number of objects that can be found |
100 |
Where |
Where clause to use in query.
Example: |
- Example Config
<Rest>
<ServiceName>product</ServiceName>
<IdLocator type="tnr">
<Where>revision==last"</Where>
<Limit>1</Limit>
</IdLocator>
...
</Rest>Value
- Name
-
value
- Required PathParamters
-
1 (value)
- Description
-
Identifies the object using a value on an attribute/basic. Uses a query in the background to find the matching object. For example, it can be a unique product number stored in an attribute.
- Settings
| Name | Description | Default |
|---|---|---|
Limit |
Maximum number of objects that can be found |
100 |
Match |
Defines what attribute/basic to use to find the object of interest. This setting is mandatory. Example: |
|
Type |
Defines a type that object must be of. |
* |
Where |
Where clause to use in query. Example: |
- Example Config
<Rest>
<ServiceName>product</ServiceName>
<IdLocator type="value">
<Match>$<attribute[attribute_ProductId]></Match>
</IdLocator>
...
</Rest>- Example URL
http://server-name:8181/enovia/jaxrs/service/product/9857847
Object Id
- Name
-
objectid
- Required PathParamters
-
1 (objectid)
- Description
-
Uses an object id to locate the object.
- Example Config
<Rest>
<ServiceName>product</ServiceName>
<IdLocator type="objectid" />
...
</Rest>- Example URL
http://server-name:8181/enovia/jaxrs/service/product/1234.5678.9123.4567
Custom IdLocator
Specify the qualified java class name in the attribute className. The java class must implement the interface com.technia.tif.enovia.jaxrs.service.idlocator.IdLocator.
/**
* Responsible for identifying objects requested by the client of a configurable
* REST web service.
*
* @since 2015.3.0
*/
public interface IdLocator {
/**
* Locates object id/s based on the provided input.
*
* @param ctx Information about this REST call
* @return The object id/s
* @throws IdLocatorException Thrown if problem occur. For example, if no
* object was found.
* @since 2015.3.0
*/
Collection<String> locateIds(ExecutionCtx ctx) throws IdLocatorException;
}
Implement the interface com.technia.common.xml.XMLReadable if your id locator support configuration settings.
|
8.8.9. Operation
The operation is the actual job to perform. For example, read information about an object.
8.8.10. Payload Read Operation
The payload read operation extracts information from ENOVIA/3DExperience for the object/s. Note that object id/s only are available in case the REST service contains an IdLocator.
To read payload, configure attribute type with value payload.
In addition, specify a payload using the attribute payload.
See page Payload Definition for details on how to define the payload definition.
Example
<Rest>
...
<Read type="payload" payload="tvc:payload/Product.xml" />
</Rest>Produce XML / JSON
The read operation supports generating content in XML or JSON format. The Accept header is used to determine which format to use.
| Accept Header Value | Description |
|---|---|
application/xml |
Generates content in XML format. This is the default, if no format is specified. |
application/json |
Generates content in JSON format. |
To disable automatic payload transform based on the Accept header, set attribute autoTransform to false.
Example
<Rest>
...
<Read type="payload" payload="tvc:payload/Product.xml" autoTransform="false" />
</Rest>| It is also possible to define response content type explicitly in payload configuration. See Payload Definition. |
8.8.11. File Read Operation
The file read operation can be used to extract files that are checked into an object. The extraction is done from one object per request. Therefore, exactly one object id is required. Object id is specified by an IdLocator.
To extract files, configure attribute type with value file. In addition, it can be configured with the following attributes which files should be included or excluded.
| Attribute | Description |
|---|---|
|
A comma separated list of file formats that should be used to include files. |
|
A comma separated list of file names that should be used to include files. Wildcards can be used. The wildcard matcher uses the characters '?' and '*' to represent a single or multiple wildcard characters. This is the same as often found on Dos/Unix command lines. The check is case-insensitive by default. |
|
A comma separated list of file names that should be used to exclude files. Wildcards can be used. The wildcard matcher uses the characters '?' and '*' to represent a single or multiple wildcard characters. This is the same as often found on Dos/Unix command lines. The check is case-insensitive by default. |
|
Defines if the extraction result should be compressed into a ZIP file if the result contains only one file. If there are more than one file, the result will compressed into a ZIP file regardless of this setting. Use values "true" or "false". Default is "false", if not configured. |
|
Configures "Content-Disposition" header in the response. Valid values are Value Default is |
Example
<Rest>
...
<Read type="file"
includeFormats="generic,zip"
includeFileNames="text*.txt,package*.zip"
excludeFileNames="*.doc"
zipOnlyFile="true"/>
</Rest>Client may also add one or more request specific query parameters, that can be used to include or exclude files even more detailed per request. It should noticed that request specific filters cannot be used to extract files that configured filters do not allow. The following query parameters are supported.
| Query Parameter | Description |
|---|---|
|
File format that should be used. |
|
Name of file that should be included. Wildcards can be used. The wildcard matcher uses the characters '?' and '*' to represent a single or multiple wildcard characters. This is the same as often found on Dos/Unix command lines. The check is case-insensitive by default. |
|
Name of file that should be exluded. Wildcards can be used. The wildcard matcher uses the characters '?' and '*' to represent a single or multiple wildcard characters. This is the same as often found on Dos/Unix command lines. The check is case-insensitive by default. |
|
Can be used to override default content disposition configuration. See previous table for details. |
Client may also pass a list of filters by using multiple parameters.
- Example Query
http://server-name:8181/enovia/jaxrs/service/product/Sales+Item/1200-1000/A?includeFormat=generic&includeFileName=*123.txt&excludeFileName=*.zip
8.8.12. File Update Operation
The file update operation can be used to check in files to an object. Check in can be done to one object per request. Therefore, exactly one object id is required. Object id is specified by an IdLocator.
A request should be done with method "PUT" and using multipart/form-data encoding.
To check in files, configure attribute type with value file.
Example
<Rest>
...
<Update type="file"
format="generic"
existStrategy="newversion"
append="true"
useCDM="true"
unzip="false" />
</Rest>In addition, it should be configured with the following attributes how files are checked in.
| Attribute | Description | Required |
|---|---|---|
|
Defines what should happen if a file with same name is already checked in. Use value "fail" if the operation should cause the request to fail. Use value "overwrite" if file should be overwritten. Use value "newversion" if new version of file should be created. In this case attribute "useCDM" must be "true". |
Yes |
|
Defines in which format file is checked in. |
Yes |
|
Defines if file should be appended to the object. If "false", then other files in same format are removed from object. Use value "true" or "false". If disabled, attribute "useCDM" or "unzip" cannot be "true". |
No, default is "true". |
|
Defines if Common Document Model or CDM is applied. Use value "true" or "false". If enabled, attribute "append" cannot be "false". |
No, default is "false". |
|
Defines if zipped uploaded files are extracted and their contents are checked in instead. Files are retrieved from the root level of ZIP package. Use value "true" or "false". If enabled, attribute "append" cannot be "false". |
No, default is "false". |
8.8.13. Create new Job Operation
The create new job operation can be used to execute/run a new integration job. The request may be done context-less or in context of one or more objects; this all depends on how you have configured your REST job regarding IdLocator.
Example Configuration
<Rest>
...
<NewJob jobcfg="TheJobCfgName.xml" />
</Rest>| When using this operation, you will see a minimum of two log entries in the Admin UI. One is for the actual REST job itself and the other is for the job(s) that you execute. |
A request should be done with the "POST" method. Example:
curl -X POST http://server:8181/enovia/jaxrs/service/new-job-from-rest/Part/EV-000001/A
The following attributes can be used on the <NewJob> element
| Attribute | Description | Required |
|---|---|---|
|
Defines the Job configuration name to be used |
True |
|
This flag defines if the REST job should wait for the job to complete. Default is TRUE, e.g. do not wait for completion. Note that if your configuration resolves to multiple context objects, the job will be executed asyncronously anyway. |
No |
|
This flag can be used to specify that you want to return the generated payload from the job execution. Setting this to true, requires you to run the job synchronously.
E.g. the |
No |
8.8.14. HTTP Status Codes
HTTP status codes are used to communicate the status of the call to the client.
In case an error occurs a status code other than 200 is returned along with a description of the problem.
| Code | Description |
|---|---|
200 |
All ok |
400 |
One of the following:
|
415 |
Unsupported media type. The service is unable to produce content on the media type requested by the client. |
404 |
No object found. The provided PathParameters/QueryParameters didn’t match any object in ENOVIA/3DExperience. |
500 |
Unexpected error. View the response for details. |
501 |
Unsupported operation. The requested operation is not supported. |
8.9. Hosting RESTful Web Service
TIF allows deploying RESTful Webservice’s.
8.9.1. Deployment
You have to package your RESTful services in a JAR file together with a special file within the "META-INF/" folder of the JAR file that defines what packages TIF should scan for the annotated RESTful service classes.
The file inside the META-INF folder should have the name jax-rs-packages.properties and this file should contain the package names (one per line in the file).
- jax-rs-packages.properties
com.acme.integrations.erp.rest
com.acme.integrations.sap.restThe JAR file should be dropped into the ${TIF_ROOT}/modules/enovia/webapps/jaxrs/WEB-INF/lib directory. Upon startup of TIF, the REST services will be initialized.
Custom Resource and Provider Classes
Custom resource and provider classes can be registered by creating file jax-rs-classes.properties into "META-INF/" folder. It should contain the class names one per line in the file.
- jax-rs-classes.properties
com.acme.provider.MyProvider
com.acme.resource.MyResource
JAR file(s) containing registered classes must be dropped into the ${TIF_ROOT}/modules/enovia/webapps/jaxrs/WEB-INF/lib directory.
|
8.9.2. Accessing a RESTful Service
The default context URL to a RESTful service is shown below.
- JAXRS default context URL
The port number may be different, see this page for details how to change it.
The context path to a web-application may be changed, see Module Settings for more info.
Use the example JAXRS bundled with TIF to test that everything is correctly setup. The current date will be returned in case all is okay.
- URL to example JAXRS
8.9.3. Logging
Hosted RESTful web service is automatically logged in the TIF database. It appears as a REST service in Admin UI with display name that is a combination of invoked web service class and method name. The unique service name is constructed based on the values of Path annotation in both class and method. The service name is not visible in Admin UI, but it is used to identify the service.
For example:
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
@Path("/example")
public class MyExample {
@Path("/{param}")
@GET
public String success(@PathParam("param") String param) {
return param;
}
}Considering the above example, the service display name would be "MyExample/success" and service name is "example/{param}".
Limiting Logged Payload
There are configurable webapp init parameters to set maximum length for logged inbound (request) and outbound (response) payloads. Parameters help to limit usage of heap memory and storage by preventing to persist too large payloads to TIF DB.
See parameters "inboundPayloadMaxLength" and "outboundPayloadMaxLength" in web.xml.
|
Default value for parameters is 1 000 000 bytes, if not defined. |
8.10. Apache CXF Base Web Application
There is a Apache CXF base webapp under ${TIF_ROOT}/modules/enovia/webapps/cxf that can be used as base/template for CXF based web services.
There are own servlet filters for SOAP and RESTFul web services that can be used for logging web service calls to TIF DB. See web.xml for filter details. Also, there is cxf-servlet.xml that contains configurations for example web services.
| If you have not started TIF, you will not find the web.xml or cxf-template.xml file, instead there are template files. Upon start, TIF will copy over the template file unless the web.xml or cxf-template.xml file is found. |
8.10.1. Logging RESTFul Web Services
When using the CXF logger filter for RESTful web services, the web service call is logged in the TIF database. It appears as a REST service in Admin UI with display name that is a combination of invoked web service class and method name. The unique service name is constructed based on the values of Path annotation in both class and method. The service name is not visible in Admin UI, but it is used to identify the service.
For example:
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
@Path("/example")
public class MyExample {
@Path("/{param}")
@GET
public String success(@PathParam("param") String param) {
return param;
}
}Considering the above example, the service display name would be "MyExample/success" and service name is "example/{param}".
8.10.2. Logging SOAP Web Services
When using the CXF logger filter for SOAP web services, the web service call is logged in the TIF database. It appears as a SOAP service in Admin UI.
See the filter settings in ${TIF_ROOT}/modules/enovia/webapps/cxf/web.xml for details how the service name (visible in Admin UI) is constructed.
8.10.3. Limiting Logged Payload
There are configurable webapp init parameters to set maximum length for logged inbound (request) and outbound (response) payloads. Parameters help to limit usage of heap memory and storage by preventing to persist too large payloads to TIF DB.
See parameters "inboundPayloadMaxLength" and "outboundPayloadMaxLength" in web.xml.
|
Default value for parameters is 1 000 000 bytes, if not defined. |
8.11. Reply Handler
A reply handler is responsible for handling asynchronous replies from other systems and update the status of the job (which is the source for the reply) inside TIF. This is a crucial mechanism if you are interested in receiving events upon completion or failure of a integration job.
A typical use case is when you transfer data to a messaging queue and you expect a reply from the "other" system onto a reply-queue, then you need some functionality that consumes messages from the reply-queue in order to update the job status in TIF; e.g. mark the job as succeeded or failed.
Currently, you may handle replies using a configurable reply handler from following sources:
- File system
-
Support for receiving events from the OS when a file is changed/added in a directory may be used to communicate reply status.
- JMS
-
Consume messages from a particular JMS queue used for replies
- IBM/Native MQ
-
Consume messages from an IBM MQ queue used for replies
- RabbitMQ/AMQP
-
Consume messages from a Rabbit MQ queue
- Kafka
-
Consume messages from a Kafka topic
A reply handler will take care about most of the details regarding receiving the reply and perform the internal calls inside TIF but provide extension points were necessary. For example, allow evaluating if the reply represents a positive or negative response.
A reply handler works like this
-
Get/obtain message from some source
-
From the message and its source - map to the originating Job / Transfer
-
This is typically done either via correlation id or through some custom evaluation
-
-
Based upon the content of the message, evaluate if the response is successful or failing
-
This is the place were you will need to plugin some code that does this evaluation.
-
-
Update the TIF internally
8.11.1. Configuration Location
A reply handler is defined in an XML resource within the ${TIF_ROOT}/modules/enovia/cfg directory of type "replyhandler".
Example:
${TIF_ROOT}/modules/enovia/cfg/replyhandler/MyReplyHandler.xml
${TIF_ROOT}/modules/enovia/cfg/domain/replyhandler/MyReplyHandler.xmlthese configuration files are referenced as
tvc:replyhandler/MyReplyHandler.xml
tvc:replyhandler:domain/MyReplyHandler.xml8.11.2. Configuration Format
A configuration defines the following aspects:
-
The source
-
How the mapping between message and Job id is made
-
How to evaluate the status
-
If you need an ENOVIA/3DExperience context available during the execution. (default none is allocated)
Lets look at the configuration format. Note that this is not a valid example it just illustrates all configuration aspects.
<ReplyHandler>
<Source>
<JMS id="eco-reply" /> (1)
<NativeMQ id="mq-eco-reply" />
<RabbitMQ id="rabbitmq-eco-reply" />
<Kafka id="kafka-reply" />
<File id="file-in-1" replyFor="file-out-1"/>
</Source>
<JobIdLocator className="com.acme.custom.MyJobLocator" /> (2)
<JobIdLocator script="MyIDLocator.js" />
<JobIdLocator script="tvc:script/MyIDLocator.js" />
<JobIdLocator script="tvc:script:domain/AnotherIDLocator.js" />
<JobIdLocator>
importClass(com.technia.tif.enovia.job.reply.config.JobIDLocator.ID);
function locate(msg) {
...
return new ID(UUID.fromString(jobId), transferId);
}
</JobIdLocator>
<StatusEvaluator className="com.acme.custom.MyStatusEvaluator" /> (3)
<StatusEvaluator script="MyStatusEvaluator.js" />
<StatusEvaluator script="tvc:script/MyStatusEvaluator.js" />
<StatusEvaluator script="tvc:script:domain/AnotherStatusEvaluator.js" />
<StatusEvaluator>
function evaluate(ctx) {
ctx.setResult(true, "OK");
}
</StatusEvaluator>
<WithContext /> (4)
</ReplyHandler>| 1 | Either one of these sources can be used per reply handler |
| 2 | The JobID locator |
| 3 | The StatusEvaluator |
| 4 | Optionally element that, if present, will allocate a context for you. |
The <WithContext> element supports the following attributes.
| Attribute | Required | Description |
|---|---|---|
user |
No |
If omitted, the super user will be used |
securityContext |
No |
Defines the security context to be used |
useDefaultSecurityContext |
No |
If set to true, the default security context for the user will be used. The used user must have a default security context otherwise an error will be raised. |
Both the job-id locator and status-evaluator may be implemented in a few different ways:
-
A Java class implementing either
com.technia.tif.enovia.job.reply.config.JobIDLocatorfor JobIdLocator andcom.technia.tif.enovia.job.reply.config.StatusEvaluatorfor StatusEvaluator. -
A script stored inside its own file using the script resource type.
-
An inline script.
| In some cases you may not need a JobID locator. See next chapter(s). |
|
If you are using Java 8, the internal Java Script engine has been changed so you may need to change your old legacy scripts written prior to Java 8 by adding the following at the top of your script:
|
8.11.3. JMS Source
The supported attributes on the JMS element are shown in the table below
| Attribute | Description | Required |
|---|---|---|
id |
The id of the corresponding destination |
Yes |
messageSelector |
A message selector that filters messages. See below for details |
No |
transacted |
Boolean defining transaction mode |
No. Default is false |
ackMode |
One of "auto","client" or "dups_ok" |
No. Default is auto |
consumerCount |
Defines number of concurrent consumers. Typically used with destination listening to a queue. |
No. Default is 1 |
shareConnection |
Boolean defining if to share connection per destination with other JMS listeners. The common default value can be configured with property |
No |
For handling of replies from a JMS messaging systems the correlation id is used to correlate the message to its "source" in TIF.
| If you have changed the format of the correlation id in the outgoing message, you need to apply changes in the reply handler. |
By default, the message selector that is used for a JMS Source is set to
JMSCorrelationID like '${tif.instance.id}|%'The macro is resolved at runtime to the id of the TIF instance.
This means that only messages matching this correlation id will be fetched for the TIF instance in question. This is particularly useful in situations where you have multiple TIF instances listening to the same queues. In such case it is important that only the TIF instance that sent the original message will receive the reply.
If you are using the default correlation id on the outgoing JMS message, you do not need to define a JobIdLocator at all since the mapping can be done automatically.
Example config for JMS source were response message is of type TextMessage and the status is provided as a property on the message object.
<ReplyHandler>
<Source>
<JMS id="eco-reply" />
</Source>
<StatusEvaluator>
function evaluate(ctx) {
var msg = ctx.getMessage().getText();
var succeeded = ctx.getMessge().getBooleanProperty("success");
ctx.setResult(succeeded, msg);
}
</StatusEvaluator>
</ReplyHandler>8.11.4. Rabbit MQ Source
The supported attributes on the RabbitMQ element are shown in the table below
| Attribute | Description | Required |
|---|---|---|
id |
The id of the corresponding destination |
Yes |
Replies from a Rabbit MQ messaging system uses the correlation id of the message to correlate the message to its "source" in TIF.
| If you have changed the format of the correlation id in the outgoing message, you need to apply changes in the reply handler. |
By default, outgoing messages from TIF to RabbitMQ uses a correlation id that contains the following information
-
TIF instance id
-
Job id
-
Transfer id
The TIF instance id is needed in order to be able to correlate messages to the correct TIF instance. E.g ensure that the same TIF instance that sent the original message will handle the reply.
If you are using the default correlation id on the outgoing Rabbit MQ message,
you do not need to define a JobIdLocator at all since the mapping can be done automatically.
Example config.
<ReplyHandler>
<Source>
<RabbitMQ id="eco-reply" />
</Source>
<StatusEvaluator>
function evaluate(ctx) {
var msg = ctx.getMessage().getBodyAsString();
var succeeded = ctx.getProperties().getHeaders().get("status");
ctx.setResult(succeeded, msg);
}
</StatusEvaluator>
</ReplyHandler>8.11.5. Native MQ Source
The supported attributes on the NativeMQ element are shown in the table below
| Attribute | Description | Required |
|---|---|---|
id |
The id of the corresponding destination |
Yes |
defaultMatchGroupId |
Whether or not if to match on group id’s. Note that per default this attribute is based upon the TIF setting See also this chapter. By default TIF will match messages based upon their group-id’s. |
No |
messageId |
Used to specify match option on the message-id |
No |
correlationId |
Used to specify match option on the correlation-id |
No |
groupId |
Used to specify match option on the group-id |
No |
seqNumber |
Used to specify match option on the sequence number |
No |
For handling of replies from a JMS messaging systems the correlation id is used to correlate the message to its "source" in TIF.
| If you have changed the format of the correlation id in the outgoing message, you need to apply changes in the reply handler. |
Example config for Native MQ source.
<ReplyHandler>
<Source>
<NativeMQ id="MQ.QM1.M3.REPLY" />
</Source>
<StatusEvaluator>
function evaluate(ctx) {
....
ctx.setResult(succeeded, msg);
}
</StatusEvaluator>
</ReplyHandler>8.11.6. Kafka Source
The supported attributes on the <Kafka> element are shown in the table below
| Attribute | Description | Required |
|---|---|---|
id |
The id of the corresponding destination |
Yes |
topic |
Specifies the Kafka topic to consume records from |
Yes unless the mapped destination have a default topic defined. |
clientId |
A client identifier |
No |
groupId |
Specifies the group identifier. This is used to join the Kafka consumer with a specific consumer group |
Yes. |
instanceIdHeader |
Specifies the name of the header on the record we consume that will contain the TIF instance value. This is only needed in case you have multiple TIF instances that may consume records from the same topics. In such case you must consider the source of the record. |
Depends |
jobIdHeader |
Specifies the name of the header on the record that will contain the TIF Job ID |
Yes |
destinationIdHeader |
Specifies the name of the header on the record that will contain the TIF destination id, which the record is a reply for. Note that you can omit this header and instead specify a static value in the |
Depends |
replyFor |
Specifies a fixed destination id value. All records consumer are considered being originated for this destination. Either this attribute or the |
Depends |
Example config for Kafka source.
<ReplyHandler>
<Source>
<Kafka id="kafka-reply-dest"
groupId="test-group"
topic="plm-reply"
jobIdHeader="jobId"
replyFor="kafka-dest" />
</Source>
<StatusEvaluator>
function evaluate(ctx) {
....
ctx.setResult(succeeded, msg);
}
</StatusEvaluator>
</ReplyHandler>|
When TIF is running in development mode, you can edit, create or delete configurations at runtime and those will be hot deployed automatically without the need to restart the TIF instance or take any further action. However, in production mode, you can only edit a definition at runtime, but in order to take the changes into use you need to restart the corresponding service activator from within the Administration UI. Add or delete configurations is not supported. See also this chapter for more info |
8.11.7. File Source
Some use cases involves creating files in folders that are watched by other applications. In order to receive status updates from such operation, you can use a File source to listen into a folder, which the other system is responding into.
<ReplyHandler>
<Source>
<File id="file-dest-2"
replyFor="file-dest-1"/>
</Source>
<StatusEvaluator className="com.technia.tif.enovia.job.reply.config.SimpleFileStatusEvaluator" />
</ReplyHandler>In this example we use the default ID locator, which assumes that the file name is the "job id" + an optional suffix.
In the destinations.xml file you may define the outgoing file destination like below in order to include the job-id in the outgoing file-name.
<Destinations>
<File id="file-dest-1"
directory="${tif.temp}/transfer/out"
fileName="${job.id}.xml"/>
<File id="file-dest-2"
directory="${tif.temp}/transfer/in"/>Moreover, we use a built-in status evaluator that has a very simple implementation:
public void evaluate(ReplyHandlerContext ctx) {
Path p = ctx.getMessage();
String dirName = p.getParent().getFileName().toString();
boolean error = "error".equalsIgnoreCase(dirName);
ctx.setResult(!error, readFileContent(p));
}8.11.8. Startup of Reply Handler
Upon startup, TIF will automatically find all reply handler configurations that you have configured and deploy these. This method is called auto-registration and can be disabled if wanted. Below is a table of properties that are of interest.
| Property | Type | Default | Description |
|---|---|---|---|
resources.replyHandler.autoRegister |
boolean |
True |
Use this property to disable the auto registration |
resources.replyHandler.excluded |
Comma separated list |
Comma separated list of resources to be excluded. |
|
resources.replyHandler.included |
Comma separated list |
Comma separated list of resources to be included. |
By default, auto registration is enabled and no resources are excluded.
In earlier versions of TIF, you were forced to specify the reply handler configurations
to be started within the ${TIF_ROOT}/modules/enovia/etc/module.custom.properties file.
This method is still supported, although the preferred approach is to auto-register
all configurations without having to also do extra configuration within the "module.custom.properties" file.
To deploy a reply handler using the old approach, see instructions below:
Syntax of entry within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties
replyHandler.<id>.<property> = <value>Below is an example where two different reply handlers has been configured.
replyHandler.0.config = ECOReply.xml
replyHandler.1.config = tvc:replyhandler:domain/PartReply.xml|
Refering to configurations in the default domain do not require the complete expanded name. E.g. |
|
Each reply handler may be stopped / restarted from the TIF Administration UI. |
The most common configurations requires only the "config" property to be defined. However, there are additional properties available as shown below:
replyHandler.<id>.enabled = true (1)
replyHandler.<id>.config = ... (2)
replyHandler.<id>.className = ... (3)| 1 | May be used to disable a particular reply handler |
| 2 | Specifies the reply handler configuration |
| 3 | Instead of a configuration, specify a Java class implementing com.technia.tif.enovia.job.reply.ReplyHandler |
|
The earlier supported properties called
Are no longer supported. You should configure this from within the reply handler instead using the |
8.12. Create / Update Integration
The create and/or update integration allows you to setup use cases, which will enable support for
-
Create or Update a single object
-
Create or Update multiple objects
-
Create or Update objects and relationships connected in a single or multi level fashion
The integration does not require a certain format of the incoming payload (the incoming data), instead it is via the create/update configuration you specify how the data is formatted and what actions that should be taken.
The create/update configuration is defined in an XML file, which should be stored
within a folder called "createconfig" below ${TIF_ROOT}/modules/enovia/cfg.
| You need to have some basic knowledge in XPath expressions, in order to understand how to write your configurations to match/map to the incoming payload data. |
8.12.1. Contextual or Non-Contextual
The create/update configuration can operate in two different modes depending on the use case, e.g. contextual and non-contextual. Contextual means that the integration runs in the context of a certain business-object, while in the other case it is the incoming payload that contains all information.
8.12.2. Configuration File
The create/update configuration contains on a high level:
-
Format of incoming data
-
Instructions from where in the incoming data to start the processing. This is done via
<EntryPoint>definitions. -
Rules depending on what data that has been matched. This is done via
<Config>definitions.
The root element within a create/update configuration is <CreateConfiguration>,
and this element supports the following attributes:
| Attribute | Description | Type | Default |
|---|---|---|---|
requiresInputObject |
Whether or not to run the integration in contextual mode or not. |
Boolean |
False |
runPrivileged |
Can be used to enforce running the integration as a super-user. This may be useful in situations where the current user do not have sufficient privileges to perform certain changes in the database. |
Booolean |
False |
historyOff |
May be used to turn off history logging while running the integration. |
Booolean |
False |
triggerOff |
May be used to turn off triggers while running the integration. |
Booolean |
False |
maxLevels |
May be used to restrict the integration to process structures deeper than this value. No restrictions are defined by default. |
Integer |
-1 |
txType |
The transaction type to be used while running the integration. Possible values are
|
String |
update |
dateFormat |
The default date format to be used when parsing date values from the incoming data. The value should either be a valid date pattern string, or one of the following pre-defined values:
|
String |
iso-date-time |
xpathFactory |
Define a custom XPathFactory to be used.
Either you point out a class using its fully qualified name, or use the short names
|
String |
Default is |
listener |
Name of class implementing
May be used to listen to event’s occurring during the integration execution |
String |
|
traceTags |
Can be used to turn on ENOVIA/3DExperience trace during the execution. Note that the tracing is only enabled in case TIF is running in development mode. The value is a comma separated string containing the trace types to be enabled. Example: mql,trigger,jpo |
String |
The allowed child elements are:
| Child Element | Cardinality | Required | Description |
|---|---|---|---|
|
0 or 1 |
No |
May be used to handle more complex input formats, for example ZIP input |
|
1+ |
Yes |
Defines entry points, e.g. where to look for the starting point within the incoming payload. |
|
1+ |
Yes |
Defines the create/update rules for a given kind of element. |
|
0+ |
No |
May be used to define different kind of translations of incoming values to ENOVIA/3DExperience understandable values. |
|
0 or 1 |
No |
May be used to point out an XML Schema to be used for validation of the incoming payload. |
|
0 or 1 |
No |
Configure the namespace context while evaluating XPath expressions during the processing. |
8.12.3. Input Formats
With the <InputFormats> element you can specify what kind of format the incoming
data should have. By default, if this is not specified, the incoming data is
assumed to be an XML file processed as-is.
If you omit the <InputFormats> element, we assume that the data passed
into the create/update integration is XML data.
|
The following input formats are supported:
- Default
-
XML, which is handled as-is without any conversion
- XML
-
XML that is converted to another XML format using an XSLT stylesheet.
- JSON
-
JSON data that is converted automatically to XML
- CSV
-
Comma separated values. Automatically converted to XML.
- Zip
-
ZIP file containing the data
Allowed child elements are:
| Child Element | Supported Attributes | Description |
|---|---|---|
|
- |
Used to process ZIP input files. ZIP files may contain both meta-data and additional files, which for example may be checked-in to objects being created and/or updated during the process. |
|
|
Used for conversion of CSV data into XML for further processing |
|
|
Used for converting XML data into another XML format for further processing |
|
|
Used for converting JSON data into XML. |
|
- |
E.g. just use the default input, assumed to be XML without need for further conversion. |
ZIP Input
A ZIP file contains multiple files, and you need to specify what files within the ZIP archive that contains the data that should be processed by the create / update integration engine. You can either point out a single file by its path/name or use globbing pattern to match multiple files.
Exampe 1, ZIP format and starting point is the data.xml file in the root of the ZIP archive.
<InputFormats>
<Zip>
<InputFiles>data.xml</InputFiles>
</Zip>
</InputFormats>Note that if the data you are processing is in a different format, you need to transform it to XML. Supported transformers are CSV, XML and JSON.
Exampe 2, ZIP format and starting point are the files matching the pattern data/*.csv.
<InputFormats>
<Zip>
<InputFiles>data/*.csv</InputFiles>
<Transformer> (1)
<CSV charset="UTF-8" separator="," includesHeader="true" />
</Transformer>
</Zip>
</InputFormats>| 1 | For CSV data, we need to transform it to XML. |
JSON to XML
JSON data is converted to XML as shown in the examples below:
| JSON | XML |
|---|---|
|
|
|
|
| 1 | Any occcurence of invalid XML name character is removed when transforming a JSON property name into an XML element name. E.g. the space is being removed. |
| 2 | In this case, the whole name was invalid - hence we use the fallback element name. |
CSV to XML
CSV is fairly easy to transform into XML. Each row in the CSV data is mapped to a
<row> element and each field is contained in a <field> element.
See below for an example how the CSV data is converted to XML
Input data in CSV format
Part,A-0001,B,Release,45 g
Part,A-0002,C,Release,94 gResults in this XML
<data>
<row>
<field>Part</field>
<field>A-0001</field>
<field>B</field>
<field>Release</field>
<field>45 g</field>
</row>
<row>
<field>Part</field>
<field>A-0002</field>
<field>C</field>
<field>Release</field>
<field>94 g</field>
</row>
</data>8.12.4. Entry Point
Depending on if you run in contextual mode or not (by using the requiresInputObject attribute), you need to use the EntryPoint element in two different ways.
Lets start with the non-contextual mode, in this mode you only need to specify the select attribute and optionally the mode attribute. The select attribute specifies an XPath expression, which will select an element or a list of elements from the incoming payload. Below are some examples
<EntryPoint /> (1)
<EntryPoint select="/" /> (2)
<EntryPoint select="/Data/Items/Item" /> (3)| 1 | Implicitly selects the first level elements below the root element of the incoming payload. |
| 2 | Selects the root element of the incoming payload |
| 3 | Selects the elements (or element) matching the given XPath |
The optional mode attribute may be used to process the matched elements in a particular mode. We will discuss the mode attribute more further in the document.
Example:
<EntryPoint select="/Data/Items/Item" mode="root" />Alternative 2, when processing in contextual mode: In this case, you will not use the select nor the mode attributes. Instead, you will use one or more child elements below the EntryPoint element called ContextObject, which defines for what context object it is valid for and how the context object is connected to the incoming payload. Example:
<EntryPoint>
<ContextObject match="type.kindOf[Part] AND current == 'Release'"> (1)
<Connections>
<Connection relationship="relationship_EBOM" select="/Data/BOM/rows" /> (2)
</Connections>
</ContextObject>
<ContextObject match="type.kindOf[Product]'"> (3)
...
</ContextObject>
<ContextObject> (4)
...
</ContextObject>
...
</EntryPoint>| 1 | Configuration used when context object matches the ENOVIA/3DExperience expression, e.g. for released Part’s. |
| 2 | Connection configuration (See later section for more details). Specifies for different kind of relationship(s) how to connect the context object with the incoming data. The select attribute defines an XPath expression that maps to data that represents objects that should be connected with this relationship. NOTE: You may have multiple Connection elements. |
| 3 | Configuration used when context object is of type Product. |
| 4 | Fallback configuration, which matches any context object. |
|
The match attribute must be a valid ENOVIA/3DExperience expression, which is evaluated against the database by TIF. You can test your expressions via MQL by using the following syntax. |
If you omit the match attribute, it implies that it will be valid for any kind of object.
However, the order a <ContextObject> definition is being resolved, is that the first one that matches will be used.
If none matched, but there is a configuration with an empty (or missing) match attribute,
that configuration will be used.
8.12.5. Config
The Config element describes what to actually do with the incoming data. A single Config definition is mapped to operate against a certain element (or elements) from the incoming payload.
This matching is done via the name of the current element that has been selected either via the EntryPoint or via a Connection
Below are some examples of such mapping.
Figure 3. Basic mapping between EntryPoint and Config

Figure 4. Mapping from Connection to Config using both select and mode
E.g. the select attribute on either the <EntryPoint> or <Connection> elements
consists of an XPath expression that is evaluated from the current position of the
incoming payload. The matched elements are then mapped to a certain <Config> element,
which contains instructions on how to handle the data.
| The mode attribute may be used to allow processing of an element using different configurations, depending on the current processing mode. |
The allowed attributes on the <Config> element are:
| Attribute | Description | Type | Default |
|---|---|---|---|
match |
Defines the name of the XML element from the incoming payload, which this config is valid for. |
String |
|
mode |
An optional value that defines the mode, which this config is valid for |
String |
The allowed child elements are:
| Child Element | Cardinality | Required | Description |
|---|---|---|---|
|
0 or 1 |
No |
Defines what to do, if the object the current element in the incoming payload represents exists in the ENOVIA/3DExperience database. Possible values are:
|
|
0 or 1 |
No |
Defines behavior when the current element in the incoming payload does not map to an object inside the ENOVIA/3DExperience database. Possible values are:
|
|
1 |
Yes |
Defines how to find the object inside the ENOVIA/3DExperience database based upon the incoming values. |
|
0 or 1 |
No |
Defines how to create the object inside the ENOVIA/3DExperience database based upon the incoming values. |
|
0 or 1 |
No |
Defines how to update the object inside the ENOVIA/3DExperience database based upon the incoming values. |
|
0 or 1 |
No |
Specifies optional connections that should be created or updated. |
|
0 or 1 |
No |
May be used to configure how to deal with file content that has been embedded within the incoming data. |
|
0 or 1 |
No |
May be used to configure how to deal with external file content. |
The logic follows this flow:
-
The rules inside the
<IdentityMatch>defines how to obtain values required for identifying the object inside the ENOVIA/3DExperience database. -
If no object could be mapped AND the
<CreateValues>section has been defined, TIF will try to create the object based upon the values given. Note that in the case for create, values defined within the<IdentityMatch>but not in the<CreateValues>section will be part of the create operation. -
If ONE object were found, TIF will if BOTH
<IfFound>is set to update and the<UpdateValues>has been defined, try to update the object inside the database. -
If more than one object were found, an exception will be raised and the processing will abort.
-
If
<IfNotFound>is set to revise, special revisioning rules are applied. See this chapter for more details.
8.12.6. IdentityMatch
The purpose of the <IdentityMatch> element is to define values used to identify
the object in ENOVIA/3DExperience.
The child elements are used to identify data that maps to certain fields inside ENOVIA/3DExperience. You may combine the elements as needed/required depending on the use-case.
Note that there are some common attributes shared by all child elements (except the CustomField).
- select
-
String, defines an XPath expression that is used to select the value from the incoming payload data.
- selectReturnType
-
String, May be used to declare a custom return type from the select expression. Particular if you are using xpath functions, this needs to be defined. Allowed values are: NODE, NODESET, STRING, NUMBER and BOOLEAN.
- fallbackValue
-
String, defines a fallback value to be used. May be used if you don’t expect the value to be present within the incoming payload data.
- valueMapper
-
String, defines an optional value-mapper definition, which is used to lookup the value against.
- resolveValue
-
Boolean, default is true for Type, Policy and Vault values. Defines if to treat value as a symbolic name, e.g. is to resolve it.
- allowEmptyValue
-
Boolean, default is false except for attribute fields and the description field. Defines if to allow empty values.
The table below shows the possible child elements and its additional attributes that may be of interest to use in the context of identity matching.
| Child Element | Valid Attributes in context of Identity Match | Notes |
|---|---|---|
|
|
|
|
|
|
|
Note: The attribute latest and last are used in conjunction to each other. If no revision in the given state was found, you can fallback to last revision. If this behavior is unwanted, set the last attribute to false. |
|
|
- |
|
|
- |
|
|
- |
|
|
|
|
|
- |
|
|
- |
|
|
- |
|
|
|
|
|
- |
No other fields are allowed in identity match. |
|
- |
No other fields are allowed in identity match. |
|
Up to implementation |
Below follows some examples how to construct an Identify Matching.
Example 1:
<Config match="Part">
<IdentityMatch>
<Type fallbackValue="Part"/>
<Name select="@n" />
<Revision select="@rev" />
</IdentityMatch>
</Config>This would work on data that is structured like this
<Part n="A-000101221" rev="C">
...
</Part>Example 2:
<Config match="Part">
<IdentityMatch>
<Type select="Type/text()"/>
<Name select="Name/text()" />
<Revision latest="true" select="State/text()" />
</IdentityMatch>
</Config>This would work on data that is structured like this
<Part>
<Type>Hardware Part</Type>
<Name>A-000101221</Name>
<State>Release</State>
...
</Part>Example 3:
<Config match="Something">
<IdentityMatch>
<Attribute name="attribute_UUID" select="@uuid" />
</IdentityMatch>
</Config>This would work on data that is structured like this
<Something uuid="8a9616bc-ae81-4532-87f3-214993789016">
...
</Something>8.12.7. CreateValues
The purpose of the <CreateValues> element is to define values used when creating
objects inside the ENOVIA/3DExperience database.
The child elements are used to identify data that maps to certain fields inside ENOVIA/3DExperience. You may combine the elements as needed/required depending on the use-case.
Fields defined within the <IdentityMatch> section will automatically be part
of the <CreateValues> unless they are overridden in the <CreateValues> section.
|
Note that there are some common attributes shared by all child elements (except the CustomField).
- select
-
String, defines an XPath expression that is used to select the value from the incoming payload data.
- selectReturnType
-
String, May be used to declare a custom return type from the select expression. Particular if you are using xpath functions, this needs to be defined. Allowed values are: NODE, NODESET, STRING, NUMBER and BOOLEAN.
- fallbackValue
-
String, defines a fallback value to be used. May be used if you don’t expect the value to be present within the incoming payload data.
- valueMapper
-
String, defines an optional value-mapper definition, which is used to lookup the value against.
- resolveValue
-
Boolean, default is true for Type, Policy and Vault values. Defines if to treat value as a symbolic name, e.g. is to resolve it.
- allowEmptyValue
-
Boolean, default is false except for attribute fields and the description field. Defines if to allow empty values.
| Child Element | Valid Attributes in context of Create |
|---|---|
|
- |
|
|
|
|
|
|
|
- |
|
- |
|
|
|
- |
|
- |
|
- |
|
|
|
|
|
|
|
|
|
See this chapter. |
|
Up to implementation |
Below are some examples how to construct a create value section.
Example 1:
<Config match="Part">
<IdentityMatch> (1)
<Type select="@t" valueMapper="type-mapping" />
<Name select="@n" />
<Revision latest="true" fallbackValue="Release" />
</IdentityMatch>
<CreateValues> (2)
<Revision firstInSequence="true" />
<State fallbackValue="Release" />
<Policy fallbackValue="policy_ECPart" />
<Owner fallbackValue="tiftest" />
<Originated select="@created" dateFormat="iso-date" />
<Vault fallbackValue="vault_eServiceProduction" />
</CreateValues>
</Config>| 1 | Values set here but not in the <CreateValues> section are also part of
the create operation. In this case, the Revision field is the only overridden field. |
| 2 | Defines the necessary values to create the object. In this example static/fallback values are used heavily. |
Interface
The <Interface> can be used to add one or more interfaces either always or conditionally.
To define interface name all child elements must either include use attribute OR one or more <Use> sub elements. See below example.
| Child Element | Description | Attributes |
|---|---|---|
|
Defined interfaces are always added. |
|
|
Defined interfaces are added if a condition is true. |
|
|
Defined interfaces are added if a condition is false. |
|
Example:
<Interface>
<Always use="interface_First" />
<If condition="@someAttribute = 'abc'">
<Use>interface_Second</Use>
<Use>interface_Third</Use>
</If>
<Unless condition="@otherAttribute = 'def'" use="interface_Fourth" />
</Interface>8.12.8. UpdateValues
The purpose of the <UpdateValues> element is to define values used when updating
objects inside the ENOVIA/3DExperience database.
The child elements are used to identify data that maps to certain fields inside ENOVIA. You may combine the elements as needed/required depending on the use-case.
Note that there are some common attributes shared by all child elements (except the CustomField).
- select
-
String, defines an XPath expression that is used to select the value from the incoming payload data.
- selectReturnType
-
String, May be used to declare a custom return type from the select expression. Particular if you are using xpath functions, this needs to be defined. Allowed values are: NODE, NODESET, STRING, NUMBER and BOOLEAN.
- fallbackValue
-
String, defines a fallback value to be used. May be used if you don’t expect the value to be present within the incoming payload data.
- valueMapper
-
String, defines an optional value-mapper definition, which is used to lookup the value against.
- resolveValue
-
Boolean, default is true for Type, Policy and Vault values. Defines if to treat value as a symbolic name, e.g. is to resolve it.
- allowEmptyValue
-
Boolean, default is false except for attribute fields and the description field. Defines if to allow empty values.
| Child Element | Valid Attributes in context of Create |
|---|---|
|
- |
|
- |
|
|
|
- |
|
- |
|
- |
|
|
|
|
|
|
|
|
|
Up to implementation |
Below are some examples how to construct an update value section.
Example 1:
<Config match="Part">
....
<UpdateValues>
<Attribute name="attribute_Weight" select="@weight" />
<Attribute name="attribute_UnitOfMeasure" select="@uom" />
<Attribute name="attribute_SparePart" select="@sparePart" />
<Modified select="@modified" dateFormat="iso" />
</UpdateValues>
</Config>
If you don’t want to set the same values during create as in the update case,
set the attribute useForCreate="false" on the <UpdateValues> element.
|
8.12.9. CustomField
As seen in previous chapters related to the elements <IdentityMatch>, <CreateValues>
and <UpdateValues>, an element called <CustomField> has been mentioned.
This field may be used to handle more complex data. To use it, you use the following syntax:
<CustomField className="com.acme.SomeClass" />This class must implement the interface com.technia.tif.enovia.integration.create.def.Field.
8.12.10. Connections
You may use the create/update integration to create and/or update connections within the ENOVIA/3DExperience database.
The <Connections> element is valid to use either within a <Config> section or
within the <EntryPoint> section in case you run the integration within a context object.
The <Connections> element is just a place holder for one or more <Connection>
elements.
The <Connection> element supports the following attributes
| Attribute | Required | Description | Type | Default |
|---|---|---|---|---|
select |
Yes |
Defines an XPath expression that is used to select the "children" from the incoming payload |
String |
|
mode |
No |
Defines what mode to process the child nodes within (This relates to what |
String |
|
relationship |
Yes |
Defines the name of the ENOVIA relationship to be used (symbolic names are allowed) |
String |
|
direction |
No |
Default is FROM, may be used to switch direction to TO |
from or to |
from |
typePattern |
No |
Optional type pattern (comma separated list of type names) to be used when expanding data in ENOVIA and matching with incoming payload |
String |
|
objectWhere |
No |
Optional where clause to apply on objects used when expanding data in ENOVIA and matching with incoming payload |
String |
|
relationshipWhere |
No |
Optional where clause to apply on relationships used when expanding the data in ENOVIA and matching within incoming payload |
String |
|
disconnectExisting |
No |
A flag to indicate whether or not to disconnect existing relationships, that NOT is mapped to the incoming payload |
Boolean |
False |
oneToOne |
No |
A special attribute that can be used to indicated that the connection will always either have none or one object connected |
Boolean |
False |
The allowed child elements are:
| Child Element | Cardinality | Required | Description |
|---|---|---|---|
|
0 or 1 |
Yes, unless the special attribute oneToOne has been set to true |
Defines how to map the incoming data into a particular relationship inside ENOVIA/3DExperience. See below how to construct an identity matching for relationships |
|
0 or 1 |
No |
Defines how to create the relationship inside the ENOVIA/3DExperience database based upon the incoming values. |
|
0 or 1 |
No |
Defines how to update the relationship inside the ENOVIA/3DExperience database based upon the incoming values. |
The identity matching for relationships are constructed by defining a combination of values, where each value either is related to the object or from the relationship itself.
Example 1:
<Connection ...>
<IdentityMatch>
<Relationship>
<Attribute name="attribute_FindNumber" select="@findNumber" />
</Relationship>
<Object>
<Name select="@identifier" />
</Object>
</IdentityMatch>
</Connection>This would construct an identity matcher, which will map the attribute findNumber from the incoming data to the "Find Number" attribute-value of the relationship in the database combined with the name on the related object mapped to the attribute identifier.
You may use either or both values from the relationship or the related object, in order to conduct the identity matching.
Allowed children of the <IdentityMatch>/<Relationship> element:
| Child Element | Description |
|---|---|
|
Maps to the relationship type |
|
Attribute from the relationship |
|
Ownership |
|
Ownership (altowner1) |
|
Ownership (altowner2) |
|
Modified date |
|
Originated date |
|
Custom field mapping |
Allowed children of the <IdentityMatch>/<Object> element:
| Child Element | Description |
|---|---|
|
Maps to object type |
|
Maps to object name |
|
Maps to object revision |
|
Maps to object policy |
|
Maps to object vault |
|
Maps to object state |
|
Maps to object description |
|
Maps to object owner |
|
Maps to object alt-owner1 |
|
Maps to object alt-owner2 |
|
Maps to object modified |
|
Maps to object originated |
|
Maps to object attribute |
|
Custom field mapping |
For the child elements <CreateValues> and <UpdateValues>, see previous chapters.
8.12.11. EmbeddedFiles
With the <EmbeddedFiles> element you can deal with files that is part of the payload.
The files may either be part of the payload itself, e.g embedded in the XML data,
or part of the ZIP file being used for processing the create/update use-case.
Three modes exists:
-
Files embedded directly in the payload, typically base-64 encoded file content
-
Files part of the ZIP file, and the payload refernces or uses files from it
-
Files part of the ZIP file, but no direct reference to the files from the payload, instead the files are mapped using a file-mapper.
It is not recommended to embed too many files within the incoming payload for performance reasons, choose instead to use a ZIP file when the amount of files are large or the size of the files are large.
The <EmbeddedFiles> element is just a container for one or more <File> elements.
The <File> elements supports these common attributes:
| Attribute | Description | Type | Default |
|---|---|---|---|
select |
Defines an XPath expression, used to obtain the element(s) representing the file content. |
String |
. |
cdm |
Defines if to use CDM mode or not. Default is to autodetect this. Possible values are:
|
String |
auto |
reuseVersion |
In case of CDM mode, this attribute can be used to enforce creation of new version |
Boolean |
False |
appendFile |
If to append the file |
Boolean |
True |
unlock |
If to unlock object |
Boolean |
True |
multiple |
May be used to specify if multiple files are expected from the incoming payload |
Boolean |
True |
nameSelect |
An XPath expression to be used to select the name of the file from the current element |
String |
|
nameSelectReturnType |
Allowed values are: NODE, NODESET, STRING, NUMBER and BOOLEAN. |
String |
NODE |
nameFallback |
A static value for the file-name, may only be used IF the multiple attribute has been set to FALSE |
String |
|
formatSelect |
An XPath expression used to select the format of the file |
String |
|
formatSelectReturnType |
Allowed values are: NODE, NODESET, STRING, NUMBER and BOOLEAN. |
String |
NODE |
formatFallback |
A static value for the format to be used |
String |
Embedding Files
To use embedded files mode, one need some additional attributes
| Attribute | Description | Type | Default |
|---|---|---|---|
contentSelect |
An XPath expression used to select the content of the file |
String |
|
contentEncoding |
The encoding used when converting the encoded string into bytes |
String |
UTF-8 |
encoding |
Specifies in what encoding format the content is encoded in. Currently only base64 is allowed/supported |
String |
base64 |
Lets look into an example how this could be utilized.
Example of incoming data, which would map to an objects image holder (note that the content has been cropped to reduce space). File content is embedded within the source XML data.
Incoming XML data
<Data>
<Items>
<Item id="fa-fe-2c-2d" t="Part" n="XZ-0001" rev="A" w="100 g">
...
</Item>
</Items>
<Images>
<Image ref="fa-fe-2c-2d">
<Content format="mxImage" name="image.png">iVBORw0KGgoAAAANSUhEUgAAAQoAAAFmCAMAAACiIyTaAAABv1BMVEU...The essential parts of the create/update configuration
<Config match="Item">
...
<Connections>
<Connection
oneToOne="true"
relationship="relationship_ImageHolder"
direction="to"
select="/Data/Images/Image[@ref = current()/@id]" (1)
mode="Image Holder" />
<Config match="Image" mode="Image Holder"> (2)
<CreateValues>
<Type fallbackValue="type_ImageHolder" />
<Name useSystemTime="true" prefix="auto_"/>
<Revision fallbackValue="" />
<Policy useFirst="true" />
<Vault fallbackValue="vault_eServiceProduction" />
</CreateValues>
<EmbeddedFiles>
<File (3)
cdm="false"
multiple="true"
append="true"
encoding="base64"
select="Content"
nameSelect="@name"
formatSelect="@format"
formatFallback="generic"
contentSelect="text()" />
</EmbeddedFiles>
</Config>| 1 | Connection defined for Item, used to create the image holder |
| 2 | Configuration for creation / updating of the Image Holder |
| 3 | File element that instructs how to find the files to be checked in. |
Referencing Files in ZIP from Payload
To use the file reference mode, one need some additional attributes
| Attribute | Description | Type | Default |
|---|---|---|---|
fileRefSelect |
Depends on input format. For example if you use ZIP input format, your data may refer to a file within the ZIP archive and this attribute specifies the XPath expression that would select the file reference name. The name is then used when querying the Content Handler for the used Input Format. |
String |
|
fileRefSelectReturnType |
Defines the return type of the fileRefSelect |
String |
node |
fileRefPrefix |
Can be used to prepend some path prefix to the selected value |
String |
|
fileRefSuffix |
Can be used to append some path suffix to the selected value |
String |
Example:
Incoming XML data
<Data>
<Images>
<Image name="..." rev="...">
<File fileName="image1.png" format="Large"/>
<File fileName="image2.png" format="Medium"/>The essential parts of the create/update configuration
<Config match="Image">
...
<EmbeddedFiles>
<File
cdm="false"
multiple="true"
append="true"
fileRefSelect="File"
fileRefPrefix="files/"
nameSelect="@fileName"
formatSelect="@format" />
</EmbeddedFiles>
</Config>During processing, the file handler will then look for the following files in the incoming ZIP data:
-
files/image1.png
-
files/image2.png
Mapping Files from ZIP
If the payload itself does not point out the files, one may map files from the ZIP data instead.
To use this mode you need to set the useFileMapper attribute on the <File> element to true.
<File useFileMapper="true" ...>
When this mode is defined, you need to specify some additional mapping rules as child elements.
| Child Element | Description | Required |
|---|---|---|
|
Defines mapping rules, e.g. where to look for files in the incoming ZIP file in context of the current object being processed |
True |
|
Defines additional filtering rules, e.g. files to exclude/include |
False |
The <FileMapper> element must contain at least one <PathItem> element.
The path items together builds up the search path to the files to be processed.
The table below shows the accepted attributes on a path item element.
| Attribute | Description | Example |
|---|---|---|
value |
Defines a static path item name |
|
select |
Defines an XPath expression that will select a value from the current context in the XML data |
|
selectReturnType |
Defines the return type of the select value |
string |
mapsToFormat |
May be used to define that the name of the path at this level specifies the format for the file |
|
ignoreMissing |
May be used to ignore missing item without throwing exception. Default is true. |
|
| If neither the value nor the select attribute are defined, the path-item matches to any directory. |
Lets shown an example below:
Content of incoming ZIP file
│ payload.xml
│
└───files
├───TST-0001
│ ├───generic
│ │ file1.doc
│ │ file2.xls
│ │ file3.doc
│ │
│ └───JT
│ test1.jt
│ test2.jt
│
├───TST-0002
│ └───generic
│ SomeFile.xlsx
│
├───TST-0003
└───TST-0004Payload Content
<Specs>
<Spec type="CAD Drawing" name="TST-0001" rev="A"/>
<Spec type="CAD Drawing" name="TST-0002" rev="A"/>
<Spec type="CAD Drawing" name="TST-0003" rev="A"/>
<Spec type="CAD Drawing" name="TST-0004" rev="A"/>
</Specs>Create/Update Configuration
<CreateConfiguration
txType="update"
runPrivileged="true"
historyOff="true"
triggerOff="true">
<InputFormats>
<Zip>
<InputFiles>payload.xml</InputFiles>
</Zip>
</InputFormats>
<EntryPoint select="/Specs/Spec" />
<Config match="Spec">
<IfFound>Update</IfFound>
<IdentityMatch>
<Type select="@type" />
<Name select="@name" />
<Revision select="@rev"/>
</IdentityMatch>
<CreateValues>
<Policy fallbackValue="CAD Drawing"/>
<Vault fallbackValue="vault_eServiceProduction" />
</CreateValues>
<EmbeddedFiles>
<File reuseVersion="true"
formatFallback="generic"
useFileMapper="true"> (1)
<FileMapper> (2)
<PathItem value="files" />
<PathItem select="@name" />
<PathItem mapsToFormat="true" />
</FileMapper>
<FileFilter excludedFormats="JT" />
</File>
</EmbeddedFiles>
</Config>
</CreateConfiguration>| 1 | The useFileMapper must be set to true |
| 2 | The <FileMapper> element specifies the path to the files. Note that a path item can contain static names or dynamic names selected from the XML data.
A path item may also contain the format name, thush the mapsToFormat attribute can be used to specify that. |
8.12.12. ExternalFiles
With the <ExternalFiles> element you can deal with external files that are referenced from the payload.
External files can be handled as follows:
-
By path reference
-
By URL reference
-
By using a custom file content provider
The <ExternalFiles> element may contain one or more <File> elements.
The <File> elements supports these common attributes:
| Attribute | Description | Type | Default |
|---|---|---|---|
pathSelect |
Defines an XPath expression, used to obtain the path reference to a file content. |
String |
. |
urlSelect |
Defines an XPath expression, used to obtain the URL reference to a file content. |
String |
. |
contentProvider |
Defines a class name of custom Java file content provider. |
String |
. |
cdm |
Defines if to use CDM mode or not. Default is to autodetect this. Possible values are:
|
String |
auto |
versionOf |
In case of CDM mode, this attribute can be specified to identify the previous version. The value can be a file name pattern, such as |
False |
|
reuseVersion |
In case of CDM mode, this attribute can be used to enforce creation of new version |
Boolean |
False |
appendFile |
If to append the file |
Boolean |
True |
unlock |
If to unlock object |
Boolean |
True |
multiple |
May be used to specify if multiple files are expected from the incoming payload |
Boolean |
True |
nameSelect |
An XPath expression to be used to select the name of the file from the current element |
String |
|
nameSelectReturnType |
Allowed values are: NODE, NODESET, STRING, NUMBER and BOOLEAN. |
String |
NODE |
nameFallback |
A static value for the file-name, may only be used IF the multiple attribute has been set to FALSE |
String |
|
formatSelect |
An XPath expression used to select the format of the file |
String |
|
formatSelectReturnType |
Allowed values are: NODE, NODESET, STRING, NUMBER and BOOLEAN. |
String |
NODE |
formatFallback |
A static value for the format to be used |
String |
Possible child element to the <ExternalFiles> element is:
| Child Element | Description |
|---|---|
|
Defines one or more extra parameters control the behavior. See chapters about Parameters are passed as name-value pairs, e.g. |
pathSelect
Path select can be used to reference to external file content by a file path.
Configuration example:
<Config match="payload">
...
<ExternalFiles>
<File
pathSelect="@path"
...
/>
</ExternalFiles>
</Config>Payload example:
<payload path="\\myserver\myfile.txt" />pathSelect supports the following parameters:
| Name | Description |
|---|---|
|
Adds a prefix to the path. |
|
Appends a suffix to the path. |
|
Validates the path starts with defined prefix. |
|
Validates the path starts with defined prefix in case sensitive manner. |
|
Validates the path ends with defined suffix. |
|
Validates the path ends with defined suffix in case sensitive manner. |
|
Validates the path matches the given regular expression pattern. |
| Path is normalized before validation occurs. In practice, single and double dot path steps are removed. |
urlSelect
URL select can be used to reference to external file content by a URL.
Configuration example:
<Config match="payload">
...
<ExternalFiles>
<File
urlSelect="@url"
...
/>
</ExternalFiles>
</Config>Payload example:
<payload url="file:///myserver/myfile.txt" />urlSelect supports the following parameters:
| Name | Description |
|---|---|
|
Adds a prefix to the URL. |
|
Appends a suffix to the URL. |
|
Validates the URL starts with defined prefix. |
|
Validates the URL starts with defined prefix in case sensitive manner. |
|
Validates the URL ends with defined suffix. |
|
Validates the URL ends with defined suffix in case sensitive manner. |
|
Validates the URL matches the given regular expression pattern. |
| URL is normalized before validation occurs. In practice, single and double dot path steps are removed. |
Custom File Content Provider
To customize external file handling you may also implement a Java file content provider.
The class must implement interface com.technia.tif.enovia.integration.FileContentProvider.
Example source code:
package com.acme.tif.create;
import com.technia.tif.enovia.integration.FileContent;
import com.technia.tif.enovia.integration.FileContentProvider;
import com.technia.tif.enovia.integration.create.Context;
import com.technia.tif.enovia.integration.create.Context.Select;
import java.io.IOException;
import java.net.URL;
import java.util.Map;
public class ExampleFileContentProvider implements FileContentProvider {
// Selects url string from "customURL" attribute in the context element.
private final Select select = new Context.Select("@customURL");
@Override
public FileContent getContent(Context ctx, Map<String, String> params) throws IOException {
// Read content from a URL.
URL url = new URL(ctx.getValue(select));
// Naming as "filename.txt", remove parameter
// to auto-detect name from URL path.
return FileContent.fromURL(url, "filename.txt");
}
}8.12.13. ValueMapper
You may use so called value mappers to support translation of values. For example name of types or states may not be the same between two different systems.
You may define as many value mappers as you need, each is given an identifier, which you refer to on those fields representing values that needs to be translated.
The <ValueMapper> element must have an attribute called id containing a valid identifier.
Possible child elements to the <ValueMapper> element are (note you may combine them as you need):
| Child Element | Description |
|---|---|
|
Defines a reference to an external mapping file (see below) |
|
Defines inline rules (see below) |
|
Custom value mappers. Requires attribute className pointing to
class that implements the interface |
Using value lookup:
The <ValueLookup> element supports these attributes:
- name
-
The name of the extrernal file.
If the name starts with file:, then the value is assumed to be a file from the file system, where TIF is running. You may use macros like
${TIF.HOME}to refer to the root directory of the current TIF installation.If the name does not start with file:, it is assumed to be a resource stored within the
${TIF_ROOT}/modules/enovia/cfg/lookupdirectory. If the file ends with.propertiesit is assumed to be a standard Java properties file, otherwise, if it ends with.xmlit is assumed to be an XML file following this format:<Properties> <Property name="property-1" value="value1" /> <Property key="property-2" value="value2" /> <Property name="property-3">value 3</Property> <Group key="group1"> <Property key="p1" value=".." /> <!-- accessed via key group1.p1 --> </Group> </Properties> - keyPrefix
-
An extra string to be prepended to the value before performing the lookup
- keySuffix
-
An extra string to be appended to the value before performing the lookup
Using inline rules:
The <If> element can be used in the following way:
<ValueMapper id="...">
<If is="something" caseSensitive="false">replace value</If>
<If matches="a?c?e*">replace value</If>
<If beginsWith="abc">replace value</If>
<If endsWith="def">replace value</If>
<If regexp="...">replace value</If>
</ValueMapper>8.12.14. Namespaces
The <Namespaces> element can be used to configure the name-space context used when evaluating XPath expressions.
In case your incoming XML data contains namespace information, the XPaths may be difficult to define without the mapping of prefix/uri.
You can choose to either define all your Namespace mappings manually, or use the setting that will copy over the namespaces from the source document. The latter requires that you always know what prefixes are being used for the URIs.
To copy over the namespaces from the source (incoming data), then you should use the following attributes.
<CreateConfiguration>
<Namespaces mapFromSource="true" mapFromRootElementOnly="true" />
...
</CreateConfiguration>The mapFromRootElementOnly attribute is by default set to true, but in case your namespace declarations occurs later on in the document,
you may need to set this flag to false. That implies the whole document is being scanned for xmlns: declarations.
If you prefer declaring the namespaces manually, you can use the following syntax.
<CreateConfiguration>
<Namespaces>
<Namespace prefix="a" uri="http://the_uri_for_a" />
<Namespace prefix="b" uri="http://the_uri_for_b" />
</Namespaces>
...
</CreateConfiguration>This will give you exact control over the prefix/uri mapping.
8.12.15. Revising
If an object could not be mapped through the identity values, the create/update integration can be configured to revise an earlier revision.
First, one need to configure the <IfNotFound> to revise. The default value for this setting is create.
When this mode is enabled, the create/update integration will try to find an object having the same TYPE and NAME as the object you try to match with.
Lets take an example. Below is a simple payload and a matching configuration.
Payload snippet
<Object>
<Kind>Part</Kind>
<Identifier>TEST-000001</Identifier>
<Revision>C</Revision>
</Object>Create/Update configuration snippet
<Config match="Object">
<IfFound>update</IfFound>
<IfNotFound>revise</IfNotFound> (1)
<IdentityMatch>
<Type select="Kind/text()" />
<Name select="Identifier/text()" />
<Revision select="Revision/text()" />
</IdentityMatch>
</Config>If the object Part/TEST-000001/C does not exist, the create update integration will perform a query like below to find an object to revise.
temp query bus Part TEST-000001 * where "revision == last" limit 1
If this query does NOT return any result, the object is created in the same way
as if the <IfNotFound> setting would have its value set to create.
If the query returns a result, that object is first revised and secondly, the revised object is updated according to configurations made.
Additional control over the revisioning can be specified using the <ReviseBehavior> elment as
shown below:
<Config match="Object">
<IfFound>update</IfFound>
<IfNotFound>revise</IfNotFound>
<ReviseBehavior
reviseWithFile="true"
searchType="type_Part"
searchExpandType="true" />
</Config>The attribute supported on the <ReviseBehavior> element are:
| Name | Description |
|---|---|
reviseWithFile |
Defines the flag revise-with-file passed to the ENOVIA kernel upon revising the object. Default is FALSE. |
searchType |
Overrides the type used in the type pattern when quering for the revisions. By default we use the same type as the object you are targetting. Note however if your revision sequence may have objects of different type it may be useful here to specify a common root type that will be used in the query. |
searchVaultPattern |
Specifies a custom vault pattern, if you want to narrow the query over certain vaults. Default is all vaults. |
searchExpandType |
Whether or not to query for objects having a sub-type of the type used in the query. Default is TRUE. |
Advanced Revisioning - Build Revision Sequence
It is possible to as a part of the create/update integration use-case create the revision sequence on-the-fly. Example: you are requesting to create/update an object of revision E and you do not know if the past revisions are in the database. Hence you want to include information that there exists four earlier revisions and let the create/update integration create "placeholders" for these in the database.
Starting with an example, below is a payload snippet and a matching configuration snippet.
Payload Snippet
<Object>
<Kind>Part</Kind>
<Identifier>TEST-000002</Identifier>
<Revision>E</Revision>
<Revisions> (1)
<Rev value="A" state="Obsolete">description...</Rev>
<Rev value="B" state="Obsolete">description...</Rev>
<Rev value="C" state="Obsolete">description...</Rev>
<Rev value="D" state="Release">description...</Rev>
</Revisions>
</Object>| 1 | The revisions are provided in this format (other format alternatives are supported) |
The create/config configuration below:
Create Update Configuration Snippet
<Config match="Object">
<IfFound>update</IfFound>
<IfNotFound>revise</IfNotFound> (1)
<ReviseBehavior> (2)
<BuildSequence select="Revisions/Rev/@value"> (3)
<States select="Revisions/Rev/@state" />
<Descriptions select="Revisions/Rev/text()" />
</BuildSequence>
</ReviseBehavior>| 1 | Remember to specify the if-not-found to revise |
| 2 | Supply <ReviseBehavior> to define advanced revisioning rules |
| 3 | The <BuildSequence> element is used to control the building of revision sequences. |
The attribute supported on the <BuildSequence> element are:
| Name | Required | Description |
|---|---|---|
select |
Yes |
An XPath expression used to select the revisions. The XPath starts from the contextual object you currently are locate on. |
splitBy |
No |
If the select expression maps to a single value containing for example a comma separated list, you need to speficy the delimiter to split by here. |
order |
No |
If the list for some reason is provided in reverse order, you can specify the value "reverse" here to indicate so. |
Allowed (optional) child elements are
-
<States>
-
<Descriptions>
These elements are used to provide additional data to be used when creating the revision sequence. E.g. you may want to specify the states of the objects.
| If a revision already exists in the database, the existing revision will not be updated regarding state or description, even though the data you provided is different. |
Both the <States> and <Descriptions> elements supports the exact same attributes as for the <BuildSequence> element, described above.
| The values selected for the revisions and the states and/or descriptions must have the same number of items. |
Below is an alternate payload and matching configuration:
Payload Snippet
<Object>
<Kind>Part</Kind>
<Identifier>TEST-000002</Identifier>
<Revision seq="A,B,C,D">E</Revision>
</Object>Create Update Configuration Snippet
<Config match="Object">
<IfFound>update</IfFound>
<IfNotFound>revise</IfNotFound>
<ReviseBehavior>
<BuildSequence select="Revision/@seq" splitBy=","/>
</ReviseBehavior>8.12.16. Example Configuration
<CreateConfiguration
txType="update"
runPrivileged="true"
historyOff="true"
triggerOff="true">
<EntryPoint select="/Data/Items/Item" />
<ValueMapper id="type-mapping">
<ValueLookup name="sap-key-values.properties" keyPrefix="type." />
</ValueMapper>
<Config match="Item">
<IfFound>Update</IfFound>
<IdentityMatch>
<Type select="@t" valueMapper="type-mapping" />
<Name select="@n" />
<Revision latest="true" fallbackValue="Release" />
</IdentityMatch>
<CreateValues>
<Revision firstInSequence="true" />
<State fallbackValue="Release" />
<Policy fallbackValue="policy_ECPart" />
<Owner fallbackValue="tiftest" />
<Originated select="@created" dateFormat="iso-date" />
<Vault fallbackValue="vault_eServiceProduction" />
</CreateValues>
<UpdateValues useForCreate="true">
<Attribute name="attribute_Weight" select="@w" ifNull="fail" />
<Description base64Encoded="true" select="Description/text()"/>
<RDO select="@rdo" />
</UpdateValues>
<Connections>
<Connection relationship="relationship_EBOM"
select="Item"
disconnectExisting="true">
<IdentityMatch>
<Relationship>
<Attribute
name="attribute_FindNumber"
select="@findNumber"/>
</Relationship>
</IdentityMatch>
</Connection>
<Connection relationship="relationship_ReferenceDocument"
typePattern=""
select="Specs/Doc"
disconnectExisting="true">
<IdentityMatch>
<Object>
<Name select="@docID" />
</Object>
</IdentityMatch>
<UpdateValues useForCreate="true">
<Attribute
name="attribute_DocumentClassification"
select="@classification" />
</UpdateValues>
</Connection>
</Connections>
</Config>
<Config match="Doc">
<IdentityMatch>
<Type fallbackValue="Document"/>
<Name select="@docID" />
<Revision fallbackValue="*"/>
</IdentityMatch>
<CreateValues>
<Policy fallbackValue="Document" />
<Vault fallbackValue="eService Production" />
</CreateValues>
</Config>
</CreateConfiguration>8.12.17. Trigger a Create/Update Integration via REST
In order to trigger a create/update configuration via REST call, you need to
create a REST service configuration within ${TIF_ROOT}/modules/enovia/cfg/restservice.
Below is an example how to launch such use case without requiring any context object.
<Rest>
<DisplayName>EBOM Create/Update Service</DisplayName>
<ServiceName>ebom</ServiceName>
<Credentials containerManaged="true" />
<Create config="EBOM.xml" /> (1)
<Create config="EBOM.xml" payload="tvc:payload/test1.xml"/> (2)
</Rest>| 1 | This points out the configuration tvc:createconfig/EBOM.xml |
| 2 | Alternative, when there is a need to generate custom response via payload configuration |
Below is an alternative REST service configuration showing how to use input/context object.
<Rest>
<DisplayName>EBOM Create/Update service (single level)</DisplayName>
<ServiceName>ebom-single-level</ServiceName>
<IdLocator type="tnr"> (1)
<Setting name="allowWildcards" value="false" />
</IdLocator>
<Credentials containerManaged="true" />
<Create config="EBOM-single-level.xml" />
</Rest>| 1 | Here we require the type name and revision to be present on the URL. Note that alternative ways to map URL into id’s can be done. Please read the chapter describing configurable REST Services here. |
Using custom payload generation:
When you point out a custom payload, please note that you must use the "objectIdParam" attribute to lookup the correct ID´s. For relationships, use "relationshipIdParam" attribute instead.
<Payload rootElement="Response">
<XMLSpec>
<IncludeTableHeaders>false</IncludeTableHeaders>
<IncludeTableGroups>false</IncludeTableGroups>
<AddColumnId>false</AddColumnId>
<AddCellIndex>false</AddCellIndex>
<AddColumnRef>false</AddColumnRef>
<AddCellValueSize>false</AddCellValueSize>
<OmitCellValueElement>true</OmitCellValueElement>
<OmitRowAttributes>true</OmitRowAttributes>
<UseColumnName>true</UseColumnName>
<TableDataElement/>
<RowElement>${TYPE}</RowElement>
</XMLSpec>
<TableContent objectIdParam="createdObjectIds" outerElement="CreatedObjects"> (1)
<Table>tvc:table/PartBasic.xml</Table>
</TableContent>
<TableContent objectIdParam="updatedObjectIds" outerElement="UpdatedObjects"> (2)
<Table>tvc:table/PartBasic.xml</Table>
</TableContent>
<TableContent relationshipIdParam="createdRelationshipIds" outerElement="CreatedRelationships"> (3)
<Table>tvc:table/RelBasic.xml</Table>
</TableContent>
</Payload>| 1 | Use id’s of created business objects |
| 2 | use id’s of updated business objects |
| 3 | use id’s of created relationships |
The available parameters are:
-
createdObjectIds
-
revisedObjectIds
-
updatedObjectIds
-
allObjectIds
-
createdRelationshipIds
-
updatedRelationshipIds
-
allRelationshipIds
8.12.18. Trigger a Create/Update Integration via JMS
In order to trigger a create/update integration via JMS, you need to
add a JSM message listener within the directory ${TIF_ROOT}/modules/enovia/cfg/jmslistener.
Below is an example how to setup such a listener:
${TIF_ROOT}/modules/enovia/cfg/jmslistener/TestListener.xml
<JMSListener>
<Name>Create Update EBOM via JMS</Name>
<Destination id="jms-1" /> (1)
<WithContext user="..." /> (2)
<Handler type="CreateUpdateIntegration" /> (3)
<Arguments>
<Argument name="configuration" value="tvc:createconfig/EBOM.xml" /> (4)
<!-- Below: Extra optional parameters -->
<Argument name="payloadconfig" value="tvc:payload/EBOM_Response.xml" /> (5)
<Argument name="objectidparam" value="oid" /> (6)
<Argument name="responsemessagetype" value="text" /> (7)
</Arguments>
</JMSListener>| 1 | This is the destination you will get messages from |
| 2 | If you want to run the integration as a certain user, specify so here |
| 3 | This will choose the correct message listener |
| 4 | Points out the create/update configuration to be used |
| 5 | Specify custom payload config used to produce the response |
| 6 | Specify custom header name to use for reading contextual object id |
| 7 | Type of return message, default is text. Use stream to force stream message |
Please see previous chapter for details regarding using a custom payload for creation of the response.
The response message is sent to the queue as specified within the Reply To header of the JMS Message.
|
8.12.19. Trigger a Create/Update Integration via Kafka
In order to trigger a create/update integration via Kafka messages / records, you need to
add a kafka message listener within the directory ${TIF_ROOT}/modules/enovia/cfg/kafkalistener.
Below is an example how to setup such a listener:
${TIF_ROOT}/modules/enovia/cfg/kafkalistener/TestListener.xml
<KafkaListener>
<Name>Create Update EBOM via Kafka</Name>
<Topic>TIF-JOB-TEST</Topic> (1)
<GroupId>TEST_GROUP</GroupId> (2)
<OnError>continue</OnError> (3)
<Destination id="kafka-1" />
<Handler type="CreateUpdateIntegration" /> (4)
<Arguments>
<Argument name="configuration" value="Part_from_ERP.xml" /> (5)
<!-- Below: Extra optional parameters -->
<Argument name="payloadconfig" value="tvc:payload/EBOM_Response.xml" /> (6)
<Argument name="objectidparam" value="oid" /> (7)
<Argument name="replytoheader" value="replyTo" /> (8)
<Argument name="keyheader" value="replyKey" /> (9)
</Arguments>
</KafkaListener>| 1 | This is the topic |
| 2 | Consumer group id |
| 3 | Override default on error setting |
| 4 | This will choose the correct message listener |
| 5 | Points out the create/update configuration to be used |
| 6 | Specify custom payload config used to produce the response |
| 7 | Specify custom header name to use for reading contextual object id (not required) |
| 8 | Specify header containing the reply to topic. (not required) |
| 9 | Custom header containing the reply record key. If not present, same key is used for the reply. (not required) |
Please see previous chapter for details regarding using a custom payload for creation of the response.
8.12.20. Trigger a Create/Update Integration via File
It is also possible to trigger the create/update integration via file system integration.
To do so, you need to add a directory listener within the directory ${TIF_ROOT}/modules/enovia/cfg/directorylistener.
Below is an example how to setup such a listener:
${TIF_ROOT}/modules/enovia/cfg/directorylistener/TestListener.xml
<tif:DirectoryListener
xmlns:tif="http://technia.com/TIF/DirectoryListener"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://technia.com/TIF/DirectoryListener http://products.technia.com/tif/schema/latest/DirectoryListener.xsd">
<tif:Name>Create Update EBOM via File</tif:Name>
<tif:Destination id="file-dest-in" /> (1)
<tif:WithContext user="tiftest" /> (2)
<tif:Handler type="CreateUpdateIntegration" /> (3)
<tif:Paths delete="true" /> (4)
<tif:Arguments>
<tif:Argument name="configuration" value="tvc:createconfig/EBOM.xml" /> (5)
<tif:Argument name="outputDestination" value="file-dest-out" /> (6)
<tif:Argument name="errorDestination" value="file-dest-err" /> (7)
<tif:Argument name="payloadconfig" value="tvc:payload/EBOM_Response.xml" /> (8)
<tif:Argument name="updateSourceFile" value="FALSE" /> (9)
</tif:Arguments>
</tif:DirectoryListener>| 1 | This is the destination that configures the directory to listen for files from |
| 2 | If you want to run the integration as a certain user, specify so here |
| 3 | This will choose the correct directory listener that will trigger the integration correctly |
| 4 | Deletes the source file after completion |
| 5 | Points out the create/update configuration to be used |
| 6 | Defines a destination where the success response is written into. Note that the file-name remains the same as from the input directory. |
| 7 | Defines a destination where the error response is written into. Note that the file-name remains the same as from the input directory. |
| 8 | Specify custom payload config used to produce the response. Please see previous chapter for details regarding using a custom payload for creation of the response. |
| 9 | This flag can be used to control if to update the source file or not. If set to FALSE the result of the create update integration execution can be found in the Admin UI. |
Below is a variant of how the directories can be configured instead of referencing destination via id’s.
<tif:DirectoryListener
xmlns:tif="http://techniatranscat.com/TIF/DirectoryListener"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://techniatranscat.com/TIF/DirectoryListener http://products.technia.com/tif/schema/latest/DirectoryListener.xsd">
<tif:Name>Test Create/Update</tif:Name>
<tif:Paths>
<tif:Input>t:/temp/tif/dir-listener/in</tif:Input>
<tif:Output>t:/temp/tif/dir-listener/out</tif:Output>
<tif:Error>t:/temp/tif/dir-listener/err</tif:Error>
</tif:Paths>
<tif:WithContext user="tiftest" />
<tif:Handler type="CreateUpdateIntegration" />
<tif:Arguments>
<tif:Argument name="configuration" value="tvc:createconfig/CreateOrUpdateObject.xml" />
<tif:Argument name="updateSourceFile" value="false" />
</tif:Arguments>
</tif:DirectoryListener>Encoding
Encoding of input and success/error response payload can be optionally defined as arguments.
For example:
<tif:DirectoryListener>
...
<tif:Arguments>
<tif:Argument name="inputEncoding" value="UTF-8" /> (1)
<tif:Argument name="outputEncoding" value="UTF-8" /> (2)
</tif:Arguments>
</tif:DirectoryListener>| 1 | Defines encoding of input payload. If not defined, default charset is used. |
| 2 | Defines encoding of success/error payload. If not defined, default charset is used. |
8.12.21. Extension Points
There are some possibilities within the create/update integration to plugin custom code in order to override certain behavior or add extra logic when something happens during the processing.
Custom listener
In order to listen to occurring events, one can specify a listener within the configuration as shown below.
Such listener must implement the interface com.technia.tif.enovia.integration.event.IntegrationListener.
This interface has one method that you need to implement:
void handleEvent(IntegrationEvent event);The event argument passed may be an instance of:
-
com.technia.tif.enovia.integration.event.ObjectEvent
-
com.technia.tif.enovia.integration.event.RelationshipEvent
-
com.technia.tif.enovia.integration.event.FileEvent
-
com.technia.tif.enovia.integration.event.FailureEvent
-
com.technia.tif.enovia.integration.event.XMLParsedEvent
From the event object, you can get the event type, which is an enum constant with the following values
| Enum Constant | Description |
|---|---|
OBJECT_CREATED |
A business object was created |
OBJECT_REVISED |
A business object was revised |
OBJECT_UPDATED |
A business object was modified |
OBJECT_DELETED |
A business object was deleted |
RELATIONSHIP_CREATED |
A relationship was created |
RELATIONSHIP_UPDATED |
A relationship was modified |
RELATIONSHIP_DELETED |
A relationship was deleted |
FILE_CHECKEDIN |
A file was checked-in to a business object |
STARTED |
The integration started |
COMPLETED |
The integration is complete |
FAILURE |
The integration failed |
TRANSACTION_START_UPDATE |
An update transaction has been started |
TRANSACTION_START_READ |
A read transaction has been started (not commonly used) |
TRANSACTION_COMMITTED |
The transaction was committed |
TRANSACTION_ABORTED |
The transaction was aborted |
XML_PARSED |
The XML data has been parsed |
OTHER |
Other unspecified event |
If you want to abort the processing of the integration, you can always throw an unchecked exception, example:
package com.acme;
import com.technia.tif.core.TIFRuntimeException;
import com.technia.tif.enovia.integration.event.FailureEvent;
import com.technia.tif.enovia.integration.event.IntegrationEvent;
import com.technia.tif.enovia.integration.event.IntegrationListener;
import com.technia.tif.enovia.integration.event.ObjectEvent;
import com.technia.tif.enovia.integration.event.RelationshipEvent;
public class MyListener implements IntegrationListener {
@Override
public void handleEvent(IntegrationEvent event) {
switch (event.getType()) {
case OBJECT_UPDATED:
String oid = ((ObjectEvent) event).getObjectId();
if (getValueFromObject(oid).equals("Bad")) {
throw new TIFRuntimeException("Bad value detected. Aborting");
}
....
}
}
}In order to register your listener, use the listener attribute on the root element:
<CreateConfiguration listener="com.acme.MyListener" ...>
...
</CreateConfiguration>Business Object Finder
During the processing of a create/update integration, the integration will at certain places try to find business objects from the database in order to map them to the incoming payload.
You may override the find logic by providing a class that implements the interface
com.technia.tif.enovia.integration.create.BusinessObjectFinder. The default implementation
is com.technia.tif.enovia.integration.create.impl.DefaultBusinessObjectFinder.
<CreateConfiguration>
...
<Config>
<ObjectFinder className="com.acme.MyFinder" />
...
</Config>
</CreateConfiguration>Business Object Processor
A business object processor is involved for the creation, updating or revising an object.
You may override this logic by providing a class that implements the interface
com.technia.tif.enovia.integration.create.BusinessObjectProcessor. The default implementation
is com.technia.tif.enovia.integration.create.impl.DefaultBusinessObjectProcessor.
<CreateConfiguration>
...
<Config>
<ObjectProcessor className="com.acme.MyObjectProcessor" />
...
</Config>
</CreateConfiguration>Relationship Processor
Similar to a business object processor, a relationship processor is used for the creation, updating and deletion of connections between business objects.
To override the default logic you can provide a custom class that implements the interface
com.technia.tif.enovia.integration.create.RelationshipProcessor.
The default implementation is com.technia.tif.enovia.integration.create.impl.DefaultRelationshipProcessor.
<CreateConfiguration>
...
<Config>
<Connections>
<Connection>
<RelationshipProcessor className="com.acme.MyRelProcessor" />
...
</Connection>
...
</Connections>
...
</Config>
</CreateConfiguration>File Processor
A file processor is responsible for the checkin file operation.
To override the default logic you can provide a custom class that implements the interface
com.technia.tif.enovia.integration.create.FileProcessor.
The default implementation is com.technia.tif.enovia.integration.create.impl.DefaultFileProcessor.
<CreateConfiguration>
...
<Config>
<FileProcessor className="com.acme.MyFileProcessor" />
...
</Config>
</CreateConfiguration>8.12.22. Debugging
When "TRACE" log level is enabled, create / update integration provides more information to TIF’s log file. This can be useful for testing and development purposes.
You may change run time log settings from Admin UI. See sections "Admin UI" and "TIF Core" / "Log Settings" in the documentation.
| "TRACE" log level is not intended to be used in the production use as detailed logging might negatively affect the performance. |
9. Batch Jobs
A batch job in TIF is a job that typically performs some operation onto files and/or objects inside the ENOVIA/3DExperience database.
Example of batch job could be converting Microsoft Word document into PDF and apply a watermark upon release of the document object.
9.1. File Modification - Overview
TIF provides functionality for performing batch operations on files checked in to ENOVIA/3DExperience. The kind of operations supported are:
-
Converting Microsoft Word, Excel and Power Point files into PDF
-
Setting document properties on Microsoft Word, Excel and Power Point files
-
Adding watermark to PDF files
This feature has been part of TIF since its first release. However, the first implementation required the TIF instance performing the conversion jobs to be ran on a Windows machine. This first implementation is referred to as Modifier for Windows.
Now, TIF also contains an implementation in Java, which performs most of the operations within the JVM. Some operations could also be dispatched to an external process, for example invoking a program that does some conversion such as Adlib™. This implementation is referred to as Modifier for Java.
The next chapters describes the different implementations.
| When using the File Modifier feature on a TIF instance running on Windows, the "windows" implementation is per default selected unless otherwise configured. On any other platform, the Java implementation will be the default and the Windows implementation cannot be chosen. |
9.2. File Modifier - Windows
By default, this functionality only works if TIF is running on a Windows based OS. If you are using Linux/UNIX OS’es and want to use this implementation, one option is to setup an additional TIF instance running on a Windows OS, and configure that TIF instance to process jobs from one dedicated queue. Then you just have to ensure that all jobs that are performing file modifications as describe in this page is using that dedicated queue.
If a Windows based OS is not available, switch to use the Java based implementation. See chapter Custom Java implementation below.
|
If you run TIF as a service, ensure that the following folders exists in the filesystem:
|
|
The following software needs to be installed on the server for PDF functionality:
|
|
Depending on the event that triggered a file modification job, the job may get information about one particular file from the business object in question to operate upon. That is for example the case if the job was initiated via a checkin-event. However, for other events that triggers the file modification job, TIF will then operate upon all files attached to the business object in question. |
To start with, below is an example job configuration showing how to utilize the file modification functionality.
<Job>
<Name>Convert to PDF</Name>
<FileModifier>
<FileFilter
includeFormats="generic,other"
excludeFileNames="*.pdf"/>
<!-- or
<FileFilter
excludeFormats="PDF"
includeFileNames="*.*"/> -->
<UpdateProperties>
<PropertyHandler>com.acme.foo.MyPropertyHandler</PropertyHandler>
<Property name="Property 1" selectExpression="type"/>
<Property name="Property 2" selectExpression="attribute[attribute_Foo]"/>
</UpdateProperties>
<CreatePDF>
<ExcelOptions>
<MarginTop>10</MarginTop>
<MarginRight>10</MarginRight>
<ScaleToFit>true</ScaleToFit>
</ExcelOptions>
</CreatePDF>
<PDFWatermark>
<Definition if="current == Released">
<Text>${current}</Text>
<FontSize>72</FontSize>
<FontColor>rgb(0,255,0)</FontColor>
<TextRotation>45</TextRotation>
</Definition>
<Definition>
<Text>NOT RELEASED (${current})</Text>
<FontSize>144</FontSize>
<FontColor>rgb(255,0,0)</FontColor>
</Definition>
<Checkin format="PDF" fileName="${name}.pdf"/>
</PDFWatermark>
</FileModifier>
<Events>
<Error>
...
</Error>
</Events>
</Job>The example above will be executed only if the object (which the job is running against) has a file checked in under the format "generic" or "other" and not ending with ".pdf". Shortly, what happens in this case is:
- Properties are updated on the file
-
The example here illustrates the usage of a custom class defining key/values to set as well as defining properties mapped to select-expression.
- Secondly, a PDF is created
-
If the source file is an Excel file then there are some additional settings available for handling margins / scaling.
- Finally, watermarking
-
A watermark is applied to the PDF file and the final PDF file is checked-in to ENOVIA/3DExperience under the PDF format. The actual watermark text is selected based upon the if condition.
The root tag in the definition is always <Job>.
The first child element of the Job element defines the kind of job,
in this case we will use the <FileModifier> element to define the use of the file modification functionality.
Below the FileModifier element, the following child elements are available.
<FileFilter>-
Defines what files to perform operation upon.
<UpdateProperties>-
Defines that the document properties shall be updated
<CreatePDF>-
Converts the Office document into PDF
<PDFWatermark>-
Applies a PDF watermark to the PDF file
The child pages will go through the configuration possibilities in more detail.
File modification jobs support job events for handling errors etc. Read more in the Job Events chapter.
9.2.1. File Filter
The <FileFilter> element is used to define what files to operate on. A business object may have several files attached and they may be attached into different formats (ENOVIA/3DExperience feature).
On the <FileFilter> element, you have a couple of attributes that can be used to define either inclusion rules or exclusion rules. See table below:
| Attribute | Description |
|---|---|
includeFormats |
Comma separated list of formats to accept |
excludeFormats |
Comma separated list of formats to reject |
includeFileNames |
Comma separated list of file name patterns to accept |
excludeFileNames |
Comma separated list of file name patterns to reject |
if |
Comma separated list of parameter names that should be present in order for the filter to accept the file. The parameters are resolved from the originating job. |
unless |
Comma separated list of parameter names that NOT must be present in order for the filter to accept the file. |
The values of the parameter specified in either the if and/or unless attribute are not relevant. We are only checking the presence of such parameter.
|
Example:
<Job>
<FileModifier>
<FileFilter
if="special.condition"
includeFormats="format_Generic,format_SomeOther,format_AThirdFormat"
includeFileNames="*.doc,*.docx"/>| The patterns are case insensitive. |
9.2.2. Update Properties
The <UpdateProperties> element defines that you want to update the document properties on the file (only for Microsoft Office™ files such as Word™, Excel™, Powerpoint™).
You may point out a Java class that provides the properties (key/value pairs) to set and/or define in the configuration properties mapped to some select expression that in turn gives the value for the property.
The possible child elements are listed in the table below:
| Child Element | Description | Example |
|---|---|---|
|
Defines a single property to be transferred to the document. |
|
|
Defines that the default property handler provided by TIF shall be used. |
|
|
Points out a Java class implementing the interface |
<PropertyHandler>com.acme.integrations.file.SetProperties</PropertyHandler> |
|
If you want to check-in the document after the properties has been set, use this element to do so. |
|
Property
Defines a property to be transferred.
Example
<UpdateProperties>
<Property name="Type" selectExpression="${attribute[attribute_ProductType]}"/>
<Property name="Status" selectExpression="current"/>
</UpdateProperties>Default Properties
This element uses a default property handler available inside TIF. This property handler will extract a large amount of properties from the business object and propagate it to the file.
This property handler provides the same/similar properties as done in the TVC File Manager application.
The prefix and suffix attributes are optional and may be used to add a prefix/suffix to the property name.
Custom Property Handler
The interface com.technia.tif.enovia.job.executors.file.PropertyHandler is defined as below:
package com.technia.tif.enovia.job.executors.file;
import java.util.Map;
import com.technia.tvc.core.TVCException;
public interface PropertyHandler {
/**
* Returns the properties for a specific file/object/format combination.
*
* @param objectId The ID of the business object, which the file belongs to.
* @param format The format, which the file is being checked in to
* @param fileName The name of the file
* @return A {@link Map} containing string keys and values representing the
* properties to transfer
* @throws TVCException When some DB communication occurs.
*/
Map<String, String> getProperties(String objectId, String format, String fileName) throws TVCException;
}Checkin
Optionally, you may want to checkin the file containing the modified properties. If so, then use the <Checkin> element for that.
Without any attributes specified, the file will be checked in using the same name and format. If the file is checked-in to a CDM object (Common Document Model) a new version will be created unless the "overwrite" attribute has been set to true.
Supported attributes are:
- fileName
-
The file name to check-in to (if undefined, same file name is used).
Note that you may use the following macros:
${filename}: the original filename (full name)${name}: the original filename excluding the file extension${ext}: the original file-extension - format
-
The format to check-in to (if undefined, same format is used).
- overwrite
-
Boolean (default is false) specifying if to overwrite the current version with the modified file. False causes a new version (CDM version) to be created.
9.2.3. Create PDF
The <CreatePDF> element defines that you want to convert the Microsoft Office file into a PDF file.
The possible child elements are listed in the table below:
| Child Element | Description | Example |
|---|---|---|
|
Defines additional options that applies to conversion of a Microsoft Excel file into PDF |
|
|
Defines additional options that applies to conversion of a Microsoft Word file into PDF |
|
|
Defines if the ISO standardized PDF format (archive) should be used. |
+
|
|
If you want to check-in the generated PDF file, use this element to do so |
|
Excel Options
The ExcelOptions element can have the following child elements:
| Child Element | Description | Example |
|---|---|---|
|
Defines the top margin |
|
|
Defines the right margin |
|
|
Defines the bottom margin` |
|
|
Defines the left margin` |
|
|
Page orientation for the PDF file. Possible values are "landscape" and "portrait" |
|
|
A boolean specifying if to scale the Excel sheet to fit the PDF page |
|
Word Options
The WordOptions element can have the following child elements:
| Child Element | Description | Example |
|---|---|---|
|
Defines if to export bookmarks to PDF. The accepted values are:
|
|
Checkin
See above.
9.2.4. PDF Watermark
The <PDFWatermark> is used to define how to generate (or add) watermarks onto a PDF file.
You may have several watermark definitions and depending on some condition of the business object, for example if the object itself is in a particular state you may want to use a different watermark definition than in other cases.
This is implemented by allowing you to specify an ENOVIA/3DExperience expression that should evaluate to true on the current business object holding the PDF file.
The possible child elements are listed in the table below:
| Child Element | Description | Example |
|---|---|---|
|
Contains the watermark definition (specified by child elements). You may add several "Definition" elements using different "conditions". Note that the first Definition whose condition evaluates to true on the current business object will be used. |
|
|
If you want to check-in the generated PDF file, use this element to do so. |
|
Images
Alternate to text, you may also add image onto a PDF file.
Please note image transformations such as rotation or transparency are not supported. Instead, use an external image manipulation tool to rotate the image and/or save it in a format that supports the transparency, such as PNG.
Definition
The <Definition> element may have an attribute named "if" containing an ENOVIA/3DExperience expression, which if evaluated to TRUE for the current business object result then is used to create the watermark.
The expression itself must be a valid ENOVIA/3DExperience expression and you can test your expression from for example MQL via the following syntax:
print businessobject 1.2.3.4 select evaluate[YOUR EXPRESSION] dump;
example:
<MQL> print businessobject 1.2.3.4 select evaluate[current matchlist 'Release,Approved' ','] dump;
If you omit the "if" attribute or let it be empty, it will evaluate to TRUE for any business object.
The <Definition> elements are evaluated in the order they are defined.
The possible child elements are listed in the table below:
| Child Element | Description | Example |
|---|---|---|
|
Contains the text definition. You may mix static text along with macros referring to select statements that will be evaluated against the business object holding the file. Alternate to static text along with macros is to point out a custom Java class that provides the text. The class must implement the interface |
|
|
The name of the font to be used. Default is Arial |
|
|
The size of the font to be used. Default is 50. |
|
|
Defines the color of the font. Different ways of specifying the color is supported, for example:
The default color is black. |
|
|
Defines the rotation in degrees. -360 - 360 are allowed values. Default value is 0. |
|
|
Defines the transparency of the watermark. Allowed values are in the range 0 to 255. Default is 255. |
|
|
Number of times the text is printed between (start-x, start-y) and (end-x, end-y). Default is 1. |
|
|
Start position on X-axis. Valid value is a percentage between 0 and 100. Default is 50. |
|
|
Start position on Y-axis. Valid value is a percentage between 0 and 100. Default is 50. |
|
|
End position on X-axis. Valid value is a percentage between 0 and 100. Default is 50. |
|
|
End position on Y-axis. Valid value is a percentage between 0 and 100. Default is 50. |
|
|
Defines file name of an image to be used as a watermark.
|
|
|
Image start position on X-axis. Valid value is a percentage between 0 and 100. Default is 50. |
|
|
Image start position on Y-axis. Valid value is a percentage between 0 and 100. Default is 50. |
|
| Windows version of File Modifier assumes the position (0,0) is top left corner of PDF page. |
Checkin
See above
Custom Text Provider
The interface com.technia.tif.enovia.job.executors.file.TextProvider is defined as below:
package com.technia.tif.enovia.job.executors.file;
import com.technia.tif.enovia.job.EnoviaJob;
import com.technia.tvc.core.TVCException;
public interface TextProvider {
/**
* Returns text for a specific job/file/object/format combination.
*
* @param job Job object
* @param objectId The ID of the business object, which the file belongs to.
* @param format The format, which the file is being checked in to
* @param fileName The name of the file
* @return Text
* @throws TVCException When some DB communication occurs.
*/
String getText(EnoviaJob job,
String objectId,
String format,
String fileName) throws TVCException;
}9.3. File Modifier - Java
Instead of using TIF’s built-in Windows based file modifier, it is possible to run File Modifier via Java implementations / via external processes such as Adlib PDF Converter or Libre Office PDF converter.
To enable Java implementation, the attribute type must be present with value
java in the configuration element FileModifier. On non Windows platforms, this
is however not needed, since the Java implementation is the default selected.
However, for clarity it is recommended to specify that.
The default implementations in Java are implemented as described below:
- UpdateProperties
-
Uses the Apache POI library to set document properties.
- CreatePDF
-
Invokes an external process for the creation of the PDF document. For example you can use Adlib PDF converter or Libre Office to conduct the conversion.
- PDFWatermark
-
Uses the Java library iText (version 2.1) for applying the watermark.
Below is a complete example illustrating how to use the Java file modifier
<Job>
<Name>PDF Converter</Name>
<FileModifier type="java">
<FileFilter
includeFormats="generic"
includeFileNames="*.docx"/>
<UpdateProperties>
<DefaultProperties prefix="MX" suffix=""/>
<Checkin fileName="${filename}"/>
</UpdateProperties>
<!-- NOTE: Use one of the below CreatePDF elements -->
<CreatePDF implementation="adlibPDFConverter">
<Input destinationId="adlib-in-folder" />
<Output destinationId="adlib-out-folder" />
<Error destinationId="adlib-err-folder" />
<Checkin fileName="${filename}.pdf"/>
</CreatePDF>
<!-- OR Use this: -->
<CreatePDF>
<Command>C:/Program Files/LibreOffice/program/soffice.exe</Command>
<Command>--headless</Command>
<Command>--convert-to</Command>
<Command>pdf</Command>
<Command>${file}</Command>
<Extensions>doc;docx;ppt;pptx;xls;xslx</Extensions>
<Timeout>60000</Timeout>
<OutputFile>${fileprefix}.pdf</OutputFile>
<Checkin fileName="${filename}.pdf"/>
</CreatePDF>
<PDFWatermark allowMultiple="true">
<Definition if="current == 'Preliminary'">
<Text>${current}</Text>
<FontSize>30</FontSize>
<FontColor>rgb(255,0,0)</FontColor>
<TextRotation>-45</TextRotation>
<StartX>15</StartX>
<StartY>15</StartY>
<TextTransparency>50</TextTransparency>
<Count>1</Count>
</Definition>
<Definition if="current == 'Released'">
<Text>RELEASED</Text>
<FontSize>50</FontSize>
<FontColor>rgb(0,255,0)</FontColor>
<TextRotation>45</TextRotation>
<StartX>15</StartX>
<StartY>15</StartY>
<TextTransparency>70</TextTransparency>
<Count>1</Count>
</Definition>
<Checkin fileName="${filename}.pdf"/>
</PDFWatermark>
</FileModifier>
</Job>9.3.1. Update Properties
Follows the same format and syntax as described above for the Windows File Modifier implementation. The difference is that this implementation performs the property update using the Apache POI library.
See Update Properties above.
9.3.2. Create PDF - Using External Program
Create PDF will per default assume that you use an external program that converts the input file to PDF.
E.g. the attribute implementation="externalFileConverter" on the <CreatePDF> element
is the default value unless otherwise specified.
Starting with an example below:
<Job>
...
<FileModifier type="java">
...
<CreatePDF>
<Command>/opt/LibreOffice/program/soffice</Command>
<Command>-env:UserInstallation=file://${workdir}</Command>
<Command>--nolockcheck</Command>
<Command>--headless</Command>
<Command>--convert-to</Command>
<Command>pdf</Command>
<Command>${file}</Command>
<Extensions>doc;docx;ppt;pptx;xls;xslx</Extensions>
<Timeout>60000</Timeout>
<OutputFile>${fileprefix}.pdf</OutputFile>
<Checkin fileName="${filename}.pdf"/>
</CreatePDF>
</FileModifier>
...
</Job>There is a legacy format accomplishing the same, which is shown below for reference. Note however that this format should not be used.
<Job>
...
<FileModifier type="java">
<CreatePDF implementation="externalFileConverter">
<Arg name="commands" value="C:/Program Files/LibreOffice/program/soffice.exe;--headless;--convert-to;pdf;${file}" />
<Arg name="extensions" value="doc;docx;xls;xlsx;ppt;pptx" />
<Arg name="timeout" value="60000" />
<Arg name="outputFile" value="${fileprefix}.pdf" />
<Checkin fileName="${filename}.pdf"/>
</CreatePDF>
</FileModifier>
...
</Job>You can also configure default configurations within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties.
These will be used in case you omit something in the Job Configuration itself.
E.g. if you don’t specify any command in the job configuration, TIF will look for such in the property file.
# A ; separated list of allowed file extensions
externalFileConverter.extensions=
# A ; separated list containing commands to launch converter process with arguments
externalFileConverter.commands=
# Converter process timeout in milliseconds
externalFileConverter.timeout=
# Expected output file name after conversion
externalFileConverter.outputFile=Supported macros in the configuration:
| Macro | Description |
|---|---|
${file} |
Input file name |
${workdir} |
The current working directory using forward slashes as directory separator char |
${workdir_win} |
The current working directory using Windows backslash char as directory separator char |
${fileprefix} |
Input file name prefix (for example: test.docx → test) |
${filesuffix} |
Input file name suffix (for example: test.docx → docx) |
${iso} |
Value of configuration element <ISO> |
${scaletofit} |
Value of configuration element <ScaleToFit> |
${marginbottom} |
Value of configuration element <MarginBottom> |
${marginleft} |
Value of configuration element <MarginLeft> |
${marginright} |
Value of configuration element <MarginRight> |
${margintop} |
Value of configuration element <MarginTop> |
Below are examples how to configure externalFileConverter to call LibreOffice in headless mode to convert MS Office document to PDF and finally check in the converted PDF.
Example 1: Job configuration and module.custom.properties
Job configuration:
<Job>
...
<FileModifier type="java">
<CreatePDF implementation="externalFileConverter"> (1)
<Checkin fileName="${filename}.pdf"/>
</CreatePDF>
</FileModifier>
</Job>| 1 | Implementation attribute can be omitted, since the external file converter is the default implementation. |
${TIF_ROOT}/modules/enovia/etc/module.custom.properties:
externalFileConverter.extensions=doc;\
docx;\
ppt;\
pptx;\
xls;\
xlsx
externalFileConverter.commands=C:/Program Files/LibreOffice/program/soffice.exe;\
--env:UserInstallation=file:///${workdir};\
--nolockcheck;\
--headless;\
--convert-to;\
pdf;\
${file}
externalFileConverter.timeout=60000
externalFileConverter.outputFile=${fileprefix}.pdfExample 2: Job configuration with everything configured in the job configuration
<Job>
...
<FileModifier type="java">
<CreatePDF>
<Command>/opt/LibreOffice/program/soffice</Command>
<Command>--headless</Command>
<Command>--convert-to</Command>
<Command>pdf</Command>
<Command>${file}</Command>
<Extensions>doc;docx;ppt;pptx;xls;xslx</Extensions>
<Timeout>60000</Timeout>
<OutputFile>${fileprefix}.pdf</OutputFile>
<Checkin fileName="${filename}.pdf"/>
</CreatePDF>
</FileModifier>
</Job>9.3.3. Create PDF - Using Adlib
If you have Adlib PDF converter available, an option is to use the Adlib folder connector for PDF conversion.
To use this, you need to set the attribute implementation="adlibPDFConverter" on the <CreatePDF> element.
Below is an example how to configure this:
<Job>
<Name>PDF Converter</Name>
<FileModifier type="java">
<FileFilter
includeFormats="generic"
includeFileNames="*.docx"
excludeFileNames="*.pdf"/>
<CreatePDF implementation="adlibPDFConverter"> (1)
<Input destinationId="adlib-in-folder" /> (2)
<Output destinationId="adlib-out-folder" />
<Error destinationId="adlib-err-folder" />
<PollTimeout>5000</PollTimeout>
<MaxTimeout>600000</MaxTimeout>
</CreatePDF>
</FileModifier>
</Job>| 1 | You can either use the element <AdlibPDFConverter> or saying <CreatePDF implementation="adlibPDFConverter">. The result is equal. |
| 2 | The Input, Output and Error element accepts either a destinationId attribute OR a path attribute.
The destinationId refers to a File destination with the given id inside the destinations.xml file. |
The poll timeout and max timeout are default set to 5 seconds and 10 minutes. Override if necessary. Note that the times are defined in milliseconds.
9.3.4. PDF Watermark
The PDF Watermarking implementation used when the Java file modifier is chosen, is using the iText/Lowagie library that is part of the TVC-Core library to conduct the watermarking.
Absolution positioning of watermark
By default, start and end positions of watermark are configured relatively as percentages.
lowagiePdfWatermark additionally supports absolute positioning of watermark.
To enable it, set the attribute position to absolute on the elements <StartX>, <StartY>, <EndX>, <EndY>, <ImageStartX> and/or <ImageStartY>.
Use a decimal value to define position.
Default value for position is relative, if not set.
lowagiePdfWatermark assumes the position (0,0) is bottom left corner of PDF page.
|
Multiple watermarks
This implementation can stamp multiple watermarks (in opposite to the Windows file modifier implementation).
To enable it, set the boolean attribute allowMultiple to true on the <PDFWatermark> element.
When allowMultiple is set to true, all watermarks are stamped of which <Definition> is evaluated to TRUE.
For example:
<Job>
...
<FileModifier type="java">
...
<PDFWatermark allowMultiple="true">
...
<Definition>
...
<!-- Absolute position -->
<StartX position="absolute">10.0</StartX>
...
<!-- Relative position -->
<StartY>20.0</StartY>
</Definition>
...
<Definition>
...
</Definition>
</PDFWatermark>
</FileModifier>
...
</Job>9.3.5. Custom Implementations
The elements <UpdateProperties>, <CreatePDF> and <PDFWatermark> all supports
overriding its default functionality by setting a className attribute pointing to a
class that extends from com.technia.tif.enovia.job.executors.file.FileAction.
For example:
<Job>
...
<FileModifier type="java">
<UpdateProperties className="com.acme.tif.CustomUpdateProperties">
</UpdateProperties>
<CreatePDF className="com.acme.tif.CustomCreatePDF">
</CreatePDF>
<PDFWatermark className="com.acme.tif.CustomPDFWatermark">
</PDFWatermark>
</FileModifier>
...
</Job>The base class have one method that is required to be implemented:
import com.technia.tif.enovia.job.executors.file.FileActionContext;
import com.technia.tif.enovia.job.executors.file.FileActionResult;
protected FileActionResult process(FileActionContext ctx) throws Exception;The FileActions part of TIF is available in source code format. See below:
9.4. Report Generation
If you have the TVC Report Generator or the ENOVIA/3DExperience RPT component available, you may let TIF perform the creation of the reports.
This will replace the need to using som called Report Daemon/Agents and let TIF also handle this.
To setup a Report Daemon inside TIF you configure this within ${TIF_ROOT}/modules/enovia/etc/module.custom.properties.amp
The syntax is shown below.
reportGeneratorQueue.<ID>.enabled = true
reportGeneratorQueue.<ID>.queue = Test Queue
reportGeneratorQueue.<ID>.threadCount = 1
reportGeneratorQueue.<ID>.sleepInterval = 15000For each queue you need to setup one block like above, each block must have its own unique <ID>.
In the Report Generator you may also configure a Queue to keep it’s job and additionally define a time period for how long the Jobs will be kept after completion. In such case, you can easily setup a cleaning routine with TIF to remove those jobs that are out-of-date.
This is examplified below.
${TIF_ROOT}/modules/enovia/etc/timetable.xml
<timetable>
<group id="maintenance">
<report-job-cleanser> (1)
<schedule>
<hour>2</hour>
<minute>0</minute>
<second>0</second>
</schedule>
</report-job-cleanser>
</group>
</timetable>| 1 | Special tag that is used to enable the report job cleanser routine |
10. Scheduled Jobs
TIF provides support for running jobs at a scheduled time or period.
The scheduled jobs are defined within a file called timetable.xml within the directory ${ROOT_DIR}/modules/enovia/etc.
You can have instance specific timetable definitions. This is accomplished by adding more timetable files, within the same directory, following this naming convention:
-
timetable-{node-id}-{instance-id}.xml
-
timetable-{instance-id}.xml
-
timetable.xml
| The file names are case insensitive |
TIF does not contain any timetable files per default.
However, a sample file called timetable.xml.sample is provided in the same directory containing information and examples how to register scheduled jobs.
10.1. Configuration Format
The root element of the XML file is <timetable>.
Below this element you may have the following elements:
-
group
-
job
Jobs may be put into groups or un-grouped. Within the group element you may only have "job" elements.
The <group> element must have an attribute called "id" containing the ID of the group (unique among all groups).
An example is shown below:
<timetable>
<job id="job1">...
<job id="job2">...
<group id="g1">
<job id="job3">...
<job id="job4">...
...
</group>
<group id="g2">
<job id="job5">...
</group>
</timetable>10.2. Job Element
The <job> element defines the details of the scheduled job. You may configure a job to do one of the below
-
Execute a Java class
-
Execute a Script
-
Execute a MQL statement
-
Execute / Run a Job definition
The job element must have one attribute called "id" containing a unique identifier for the job.
The possible child elements for the job element is shown in the table below:
| Child Element | Description | Required | Example |
|---|---|---|---|
|
Used to provide the job with arguments |
No |
|
|
Defines when the job is executed. A cron format is used for specifying the time/period. See below for details. |
Yes |
|
|
Executes a Java class. See below for details |
|
|
|
Executes a script file. See below for details |
|
|
|
Executes a MQL statement (or statements) |
|
|
|
Executes a TIF job. Note that a TIF job typically requires an object as input, hence you need also some kind of "id provider" mechanism. See below for details |
|
| One of java, script, mql or jobcfg is required. |
10.3. Arguments (<args>)
The arguments section are used to pass in arguments to the job. The syntax below is used.
<args>
<arg name="the name" value="the value" type="string | int | integer | long | real | double | bool | boolean | float"/>
...
</args>10.4. Schedule (<schedule>)
The <schedule> element defines when the job should be executed.
This element may have the following child elements.
<schedule>
<second>..</second>
<minute>..</minute>
<hour>..</hour>
<day-of-month>..</day-of-month>
<month>..</month>
<day-of-week>..</day-of-week>
<year>..</year>
</schedule>
|
| Field Name | Allowed Values | Allowed Special Characters |
|---|---|---|
second |
0-59 |
,-*/ |
minute |
0-59 |
,-*/ |
hour |
0-23 |
,-*/ |
day-of-month |
1-31 |
,-*?/LW |
month |
1-12 or JAN-DEC |
,-*/ |
day-of-week |
1-7 or SUN-SAT |
,-*?/L# |
year |
1970-2099 |
,-*/ |
Special characters:
-
* ("all values") - used to select all values within a field.
-
? ("no specific value") - useful when you need to specify something in one of the two fields in which the character is allowed, but not the other.
-
- Used to specify ranges. For example, "10-12" in the hour field means "the hours 10, 11 and 12".
-
, Used to specify additional values. For example, "MON,WED,FRI" in the day-of-week field means "the days Monday, Wednesday, and Friday".
-
/ Used to specify increments. For example, "0/15" in the seconds field means "the seconds 0, 15, 30, and 45".
-
L ("last") - has different meaning in each of the two fields in which it is allowed.
For example, the value "L" in the day-of-month field means "the last day of the month".
If used in the day-of-week field by itself, it simply means "7" or "SAT".
But if used in the day-of-week field after another value, it means "the last xxx day of the month" - for example "6L" means "the last friday of the month".
-
W ("weekday") - used to specify the weekday (Monday-Friday) nearest the given day.
As an example, if you were to specify "15W" as the value for the day-of-month field, the meaning is: "the nearest weekday to the 15th of the month".
-
# used to specify "the nth" XXX day of the month. For example, the value of "6#3" in the day-of-week field means "the third Friday of the month" (day 6 = Friday and "#3" = the 3rd one in the month).
Other examples: "2#1" = the first Monday of the month and "4#5" = the fifth Wednesday of the month.
-
The 'L' and 'W' characters can also be combined in the day-of-month field to yield 'LW', which translates to "last weekday of the month".
10.5. Java (<java>)
To execute a Java class, use the <java> element to specify your class to be executed.
This class must implement the interface com.technia.tif.enovia.scheduling.ScheduledJob,
which is defined like this:
package com.technia.tif.enovia.scheduling;
public interface ScheduledJob {
void execute(JobContext ctx) throws Exception;
}The JobContext argument is defined like this:
package com.technia.tif.enovia.scheduling;
import java.util.Iterator;
import java.util.Map;
public interface JobContext {
String getId();
String getGroupId();
Iterator<String> getParamNames();
String[] getValues(String name);
String getValue(String name);
Integer getIntValue(String name);
Double getDoubleValue(String name);
Long getLongValue(String name);
Boolean getBoolValue(String name);
Map<String, String[]> toParamMap();
}Custom classes are placed inside some JAR file within the ${TIF_HOME}/modules/enovia/lib/custom directory.
10.6. Script
You may instead of implementing a Java class implement the scheduled job in a script file.
Within the <script> element, point out the script file to be executed. For example:
<script>tvc:script:background/Job1.js</script>This would refer to the file
${TIF_ROOT}/modules/enovia/cfg/background/script/Job1.jsThe script must have a function like below:
function execute(jobCtx, objectIds) {
}The last argument may be optional and might be null depending on if an "idProvider" attribute has been set on the script element.
Example with id provider:
<script idProvider="tvc:dataset:background/FindSomeObjects.xml">
tvc:script:background/JobThatDoesSomethingWithObjectsInEnovia.js
</script>10.7. MQL
The <mql> element may be used if to execute MQL or MQL/TCL code in the ENOVIA/3DExperience database.
See below for configuration details:
<mql>
execute program BackgroundJob;
</mql>or
<mql idProvider="tvc:dataset:background/SomeDataSet.xml" tcl="true">
mql delete bus ${OBJECTID}
</mql>The attributes available on the <mql> element are:
- idProvider
-
Points out an ID provider, for example a data set that returns the objects used as input.
Note the usage of the macro ${OBJECTID} in conjunction with the use of an idProvider. The MQL code is executed once for each object found by the "id provider" and the macro is replaced with the actual object-id value.
- tcl
-
True if the code is MQL/TCL.
- resolveMacro
-
True if to resolve any symbolic names prior to running the code.
10.8. Job Config
The <jobcfg> element may be used to launch an existing Job configuration.
See below for configuration details:
<jobcfg idProvider="tvc:dataset/MyDataSet.xml">
tvc:jobcfg/SomeJobConfig.xml
</jobcfg>The job defined by the configuration is executed once per object found by the "id provider".
11. Job Events
When executing integration jobs a number of events are triggered, e.g. when starting the job, successfully completing it and when an error occurs. There are built-in support to send e-mail and notifications upon the events. This is useful for instance to send e-mails to the support team in case an integration fails or notify the user initiating a job that it has finished. It’s also supported to provide a custom handler which handles custom logic, e.g. promote the ECO in case the job is successful.
Job events are configured for each integration service. They are supported for all job using jobcfgs, e.g. TransferData, FileModification and custom jobs.
| Handlers can be combined. You can both send an e-mail and provide one or more custom handlers. |
11.1. Event Types
The type of events the handlers can react on.
- Start
-
Triggered before the job starts.
- Success
-
Triggered when (and if) a job has been successfully executed.
- Error
-
Triggered when a job fails.
11.2. Mail
Sends an e-mail to the person initiating the integration job and/or other persons.
Element name: <Mail>
Available sub elements:
| Element | Description |
|---|---|
|
Defines the users to send the e-mail to. Use e-mail address. |
|
Defines the users to add as CC on the e-mail. Use e-mail address. |
|
Defines the users to add as BCC on the e-mail. Use e-mail address. |
|
Subject of e-mail |
|
Message of e-mail |
|
Content type of e-mail |
11.3. Notifications
| Notifications requires that the TVC Collaboration component is installed. |
Sends a notification to the person initiating the integration job and/or other persons. The notification is displayed directly in the ENOVIA/3DExperience UI in a similar way as when you receive an e-mail in Outlook. All notifications sent to you can be viewed in the Inbox. It’s also possible to view notifications related to for instance a Product by navigating to it and expanding the Collaboration Panel.
This feature creates messages and notifications in the TVC Collaboration component. More details on how to configure the Collaboration Panel, Inbox and searching is available in the TVC Collaboration Administration Guide.
Element name: <Notification>
Available sub elements:
| Element | Description |
|---|---|
|
Defines users to send notification to. Use the user name. |
|
Defines users to add as CC to the notification. Use the user name. |
|
Defines users to add as BCC to the notification. Use the user name. |
|
Subject of the notification |
|
Message of the notification |
|
Defines system tags to stamp on notification. Add one or more |
To configure who to send notifications from are done within the ${TIF_ROOT}/modules/enovia/etc/module.properties.
The following properties
# Enable/disable notifications globally for TIF
notification.enabled = true
# User name to send notifications from. Notification sent from yourself are not displayed.
notification.from.userName = User Agent
# Relates the notification message to the source object for the integration job
notification.relateToObject = true| The "from user" needs a Person business object in the database. |
| The notifications are broadcasted from the TIF application server to the app server which the user is logged in on. TVC Collaboration is using sensible defaults making it work in most cases. More details on how its configured is available in the Collaboration Admin Guide. |
| Notifications sent from yourself are not displayed. I.e. notifications sent by "Test Everything" is not displayed to a user logged in as "Test Everything". |
11.4. New Job
Creates and executes a new job.
Available configuration attributes:
| Attribute | Description | Required |
|---|---|---|
|
Job configuration for new job. |
Yes |
|
Points out an id provider, either a data set or a custom Java class that returns object id used as input for new job. |
No |
|
Boolean flag that indicates if the object id from the parent job is used as input for new job. If |
No |
|
Specifies the minimum number of object ids the id provider is allowed to return. Default value is 0. |
No |
|
Specifies the maximum number of object ids the id provider is allowed to return. The value -1 means unlimited. Default value is 1. |
No, unless |
|
Points out a custom Java class that returns map of job parameters used as input for new job. |
No |
|
Boolean flag that indicates if the job parameters from the parent job are used as input for new job. If |
No |
|
Points out a custom Java class that evaluates whether a new job should be created or not. |
No |
|
Boolean flag to indicate if to use response payload from a destination as input for new job. This can be only applied with outbound ENOVIA/3DExperience jobs that receive response payload from a destination. |
No |
|
ID of destination whose response payload is used as input for new job. Can be defined along with attribute |
No |
Available configuration sub elements:
| Element | Description | Required |
|---|---|---|
|
Specifies job parameters for new job. Add one or more |
No |
An example configuration that uses object id and job parameters from the parent job:
<Job>
...
<Events>
<Success>
<NewJob jobcfg="tvc:jobcfg/MyJob.xml" copyObjectId="true" copyParams="true" />
</Success>
</Events>
</Job>Another example that includes job parameters specified:
<Job>
...
<Events>
<Success>
<NewJob jobcfg="tvc:jobcfg/MyJob.xml" ...>
<Params>
<Param name="My First Param" value="some value" />
<Param name="My Second Param" value="first value; second value" />
</Params>
</NewJob>
</Success>
</Events>
</Job>11.4.1. Job Execution
The new job is executed synchronously within the same thread as the parent job. In practice, the thread is released and the parent job is completed after all jobs created by <NewJob> are executed and completed or if those are pending or awaiting reply. Retries and replies are executed in a separate thread.
If new jobs are created upon <Start> event, they are executed first. The parent job continues with the execution after new jobs are marked with status completed, pending or awaiting reply.
| It is not recommended to mass create new jobs if the parent job is initiated by a single threaded job queue listener, as it might block pending jobs in the queue. |
11.4.2. ID Provider
Id provider can be either a data set or a custom Java class that returns object ids used as input for new job.
New job is created for each object id returned by the provider. To prevent creating number of jobs unintentionally, the provider is allowed to return only one object id by default. You may override the restriction with settings minAllowedIds and maxAllowedIds.
|
An example configuration with dataset:
<Job>
...
<Events>
<Success>
<NewJob jobcfg="tvc:jobcfg/MyJob.xml" idProvider="tvc:dataset/MyDataSet.xml" />
</Success>
</Events>
</Job>An example configuration with custom Java class:
<Job>
...
<Events>
<Success>
<NewJob jobcfg="tvc:jobcfg/MyJob.xml" idProvider="com.acme.tif.MyIdProvider" />
</Success>
</Events>
</Job>The custom class needs to implement the interface com.technia.tif.enovia.jobevent.newjob.ObjectIdProvider:
public interface ObjectIdProvider {
/**
* Returns an array containing object ids.
*
* @param event Job event
* @param jobcfg Jobcfg for new job.
*
* @return An array of object ids.
*/
String[] getIds(JobEvent event, String jobcfg) throws TVCException;
}11.4.3. Job Parameter Provider
Job parameter provider is a custom Java class that returns map of job parameter used as input for new job.
An example configuration:
<Job>
...
<Events>
<Success>
<NewJob jobcfg="tvc:jobcfg/MyJob.xml" paramProvider="com.acme.tif.MyParamProvider" />
</Success>
</Events>
</Job>The custom class needs to implement the interface com.technia.tif.enovia.jobevent.newjob.JobParamProvider:
public interface JobParamProvider {
/**
* Returns map containing job parameters.
*
* @param event Job event
* @param jobcfg Jobcfg for new job.
* @param objectId Object id for new job.
*
* @return Job parameters.
*/
public Map<String, String[]> getParams(JobEvent event, String jobcfg, String objectId) throws TVCException;
}The provider is called separately for each jobcfg and object id combination.
11.4.4. Evaluator
By default, <NewJob> does not allow to create new job with the same jobcfg as parent job.
To override this, it is possible to specify a custom Java class that evaluates whether or not new job should be created, based on input.
| The default behavior prevents a possible infinite loop by not allowing to create and execute new job with the same jobcfg endlessly. It is important to prevent it in your custom code! |
An example configuration:
<Job>
...
<Events>
<Success>
<NewJob jobcfg="tvc:jobcfg/MyJob.xml" evaluator="com.acme.tif.MyNewJobEvaluator" />
</Success>
</Events>
</Job>The custom class needs to implement the interface com.technia.tif.enovia.jobevent.newjob.NewJobEvaluator:
public interface NewJobEvaluator {
/**
* Evaluates if new job should be created.
*
* @param event Job event
* @param jobcfg Job cfg
* @param objectId Object id for new job
* @param params Job parameters for new job
*
* @return True if job should be created, false if not.
*/
boolean evaluateNewJob(JobEvent event, String jobcfg, String objectId, Map<String, String[]> params) throws TVCException;
}11.5. Handler
Provides to possibility to configure a custom java class containing custom logic. You can for instance promote the object in case the integration is successful. Specify the qualified java class name as text of the element.
The provided java class needs to implement the interface JobEventListener.
Specify a custom handler by adding an element with the name <Handler> and provide the qualified name of the java class in the attribute className.
public interface JobEventListener {
/**
* Invoked when event occurs.
*
* @param event Event data
* @since 2015.3.0
*/
void onJobEvent(JobEvent event);
}Example configuration:
<Job>
...
<Events>
<Start>
<Handler className="com.company.acme.tif.StartHandler" />
</Start>
</Events>
</Job>The method onJobEvent(JobEvent) is executed once per event type (start/success/error).
Implement the interface com.technia.common.xml.XMLReadable if your handler support configuration settings.
|
11.5.1. Errors
By default, exceptions thrown from handler are ignored. This can be changed with boolean attribute ignoreErrors.
For example:
<Handler className="com.company.acme.tif.StartHandler" ignoreErrors="false" />If not defined, the default value is true.
| You may throw any unchecked exception from handler. |
The table below lists event types and difference on behavior when an exception is thrown from handler:
| Event Type | Errors ignored | Errors NOT ignored |
|---|---|---|
Start |
Job continues execution. |
Execution gets stopped and job fails. Emails, notifications or following handlers configured in |
Success |
Job completes successfully. |
Job fails. Emails, notifications or following handlers configured in |
Error |
Job fails with the original exception. |
Job fails with the exception thrown from handler. Following handlers configured in |
11.6. Trigger Create / Update Integration
| This event handler is only applicable with outbound ENOVIA/3DExperience jobs that receive response payload from a destination. |
Triggers a create/update integration by using response payload from a destination as input.
Available configuration attributes:
| Attribute | Description | Required |
|---|---|---|
|
Create/update configuration. |
Yes |
|
Custom payload configuration used to produce the response which is displayed in Admin UI. See example. |
No |
|
ID of destination whose response payload is used as input. This attribute is not required if job only has one destination configured. |
No |
Available configuration sub elements:
| Element | Description | Required |
|---|---|---|
|
Defines if to run create/update integration in an ENOVIA/3DExperience context. E.g. |
No |
Example configuration:
<Job>
...
<TransferData>
...
<Destinations>
<Http id="http-1" />
</Destinations>
</TransferData>
<Events>
<Success>
<!-- Uses response from destination http-1 -->
<CreateUpdate config="tvc:createconfig/CreateUpdateTest.xml" />
</Success>
</Events>
</Job>Another example:
<Job>
...
<TransferData>
...
<Destinations>
<Http id="http-1" />
<Http id="http-2" />
</Destinations>
</TransferData>
<Events>
<Success>
<!-- Uses response from destination http-2 -->
<CreateUpdate inputFrom="http-2" config="tvc:createconfig/CreateUpdateTest.xml">
<!-- Defines ENOVIA context -->
<WithContext user="Integration user" />
</CreateUpdate>
</Success>
</Events>
</Job>The triggered create/update integration is executed in a separate job/service context that is visible in TIF Admin UI.
You may define the display name for the service by setting attribute displayName in create/update configuration, e.g:
<CreateConfiguration
displayName="My Service Name"
...
>11.7. Macros
The Mail and Notification handler supports a number of macros:
| Macro | Supported on Event | Where |
|---|---|---|
|
All |
|
|
All |
|
|
All |
|
|
All |
|
|
All |
|
|
All |
|
|
Error |
|
|
Error |
|
11.8. Example Configuration
<Job>
...
<Events>
<Start>
<Notification>
<To>${JOB_INITIATOR}</To>
<Subject>TIF Part Basic job started</Subject>
<Message>The integration job started</Message>
</Notification>
</Start>
<Success>
<Notification>
<To>${JOB_INITIATOR}</To>
<Subject>TIF Part Basic finished successfully</Subject>
<Message>The job is now completed</Message>
</Notification>
<Handler className="com.acme.tif.CustomHandler" />
</Success>
<Error>
<Mail>
<To>${JOB_INITIATOR}</To>
<Subject>TIF Part Basic: Error</Subject>
<Message>Error encountered.
Message:
${ERROR_MESSAGE}
Stack trace:
${STACK_TRACE}
</Message>
</Mail>
<Notification>
<To>${JOB_INITIATOR}</To>
<Subject>TIF Part Basic: Error</Subject>
<Message>The integration job failed. The administrator has been notified.</Message>
<SystemTags>
<Tag key="origin" value="TIF" />
<Tag key="event" value="error" />
</SystemTags>
</Notification>
</Error>
</Events>
</Job>12. Miscellaneous Settings
12.1. Job Macros
In many places one can use macros that during runtime are resolved to real values. Depending on the context the possible macros varies, but in general, the table below illustrates the syntax of the macros and what they are resolved to.
| Macro | Descriptions | ||
|---|---|---|---|
|
Resolves the id of the current job |
||
|
Resolves the id of the current destination |
||
|
The ID of the TIF instance |
||
|
A setting from TIF named ABC |
||
|
A Java system parameter named AAA |
||
|
The ID of the ENOVIA/3DExperience user |
||
|
The ID of the source object in ENOVIA/3DExperience which the job relates to |
||
|
The TYPE of the source object in ENOVIA/3DExperience which the job relates to |
||
|
The NAME of the source object in ENOVIA/3DExperience which the job relates to |
||
|
The REVISION of the source object in ENOVIA/3DExperience which the job relates to |
||
|
The CURRENT STATE of the source object in ENOVIA/3DExperience which the job relates to |
||
|
CLASSNAME is a class implementing Example: ${job.java.a.b.c.TheResolver:the-key}
|
||
|
A custom select expression that is selected on the source object. Note that this results in extra DB calls. |
||
|
The ENOVIA/3DExperience RPE variable named ABC as set when the job was initiated Note that there is a legacy format available that does the same:
This format should however not be used since it will be removed in a future release. |
||
|
The parameter named ABC as specified when the job was initiated |